大數據流處理:Flume、Kafka和NiFi對比
在構建大數據流水線時,我們需要考慮處理數據的數量,種類和速度,這些數據通常出現在Hadoop生態系統的入口。在決定采用哪種工具來滿足我們的要求時,都會考慮到可擴展性、可靠性、適應性、開發時間方面的成本等初步因素。在本文中,我們將簡要介紹三種Apache處理工具:Flume,Kafka和NiFi。這三種產品都具有出色的性能,可以橫向擴展,并提供插件機制,可通過自定義組件擴展功能。
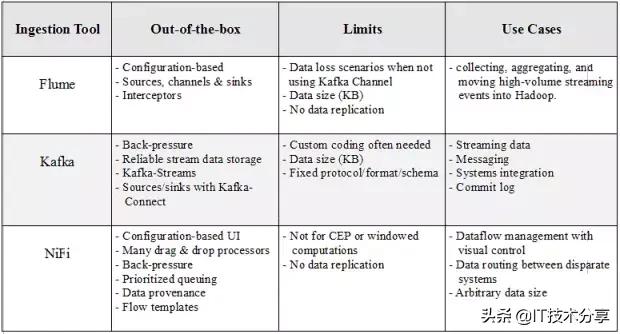
Apache Flume
Flume部署由一個或多個使用拓撲配置的代理組成。Flume代理是一個JVM進程,它承載Flume拓撲的基本構建塊,即源、通道和接收器。Flume客戶機將事件發送到源,該源將這些事件成批放置到名為channel的臨時緩沖區中,然后從該緩沖區中數據流到連接到數據最終目的地的接收器。接收器也可以是其他Flume代理的后續數據源。代理可以被鏈接,并且每個代理都有多個源、通道和接收器。
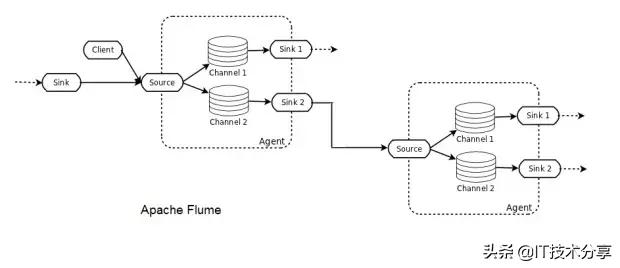
Flume是一個分布式系統,可用于收集、聚合流事件并將其傳輸到Hadoop中。它有許多內置的源、通道和接收器,例如Kafka通道和Avro接收器。Flume是基于配置的,它有攔截器來對通道中的數據執行簡單的轉換。
如果不小心,使用Flume很容易丟失數據。例如,為高吞吐量選擇內存通道有一個缺點,即當代理節點關閉時,數據將丟失。文件通道將以增加延遲為代價提供持久性。即使如此,由于數據沒有復制到其他節點,因此文件通道僅與底層磁盤一樣的可靠性。Flume通過多跳/扇入扇出流提供了可伸縮性。對于高可用性(HA),可以水平擴展代理。
Apache Kafka
Kafka是一種分布式、高吞吐量的消息總線,它將數據生產者與消費者分離開來。消息被組織成主題,主題被拆分成分區,分區被跨集群中的節點(稱為代理)復制。與Flume相比,Kafka具有更好的可擴展性和消息持久性。Kafka現在有兩種風格:一種是“經典”的生產者/消費者模型,另一種是新的Kafka-Connect,它為外部數據存儲提供可配置的連接器(源/接收器)。
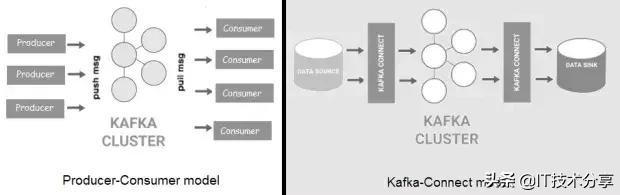
Kafka可用于大型軟件系統組件之間的事件處理和集成。此外,Kafka附帶了Kafka流,它可以用于簡單的流處理,而不需要像Apache Spark或Apache Flink那樣的單獨集群。
由于消息被持久化在磁盤上,并且在集群中被復制,因此數據丟失情況不像Flume那樣常見。也就是說,無論是使用Kafka客戶端還是通過Connect API,生產者/來源和消費者/接收器通常都需要自定義編碼。與Flume一樣,消息大小也有限制。最后,為了能夠進行通信,Kafka的生產者和消費者必須就協議、格式和架構達成一致,這在某些情況下可能會有問題。
Apache NiFi
與Flume和Kafka不同,NiFi可以處理任意大小的消息。在基于Web的拖放式用戶界面后面,NiFi在集群中運行,并提供實時控制,使您可以輕松管理任何源和任何目標之間的數據移動。它支持不同格式、模式、協議、速度和大小的分散和分布式源。
NiFi可以用于具有嚴格安全性和合規性要求的關鍵任務數據流中,在那里我們可以可視化整個過程并實時進行更改。在撰寫本文時,它有近200個隨時可用的處理器(包括Flume和Kafka處理器),可以進行拖放、配置和立即投入使用。NiFi的一些關鍵特性是優先級排隊、數據跟蹤和每個連接的背壓閾值配置。
盡管NiFi用于創建容錯生產管道,但它還沒有像Kafka那樣復制數據。如果一個節點發生故障,那么可以將流定向到另一個節點,但是排隊等待故障節點的數據必須等待該節點恢復。NiFi不是一個成熟的ETL工具,也不是復雜計算和事件處理(CEP)的理想選擇。為此,它應該連接到Apache Flink,Spark Streaming或Storm等流式傳輸框架。
組合
沒有哪個工具滿足您的所有要求。組合以更好方式執行不同操作的工具可以實現功能的增強,并提高處理更多場景的靈活性。根據您的需求,NiFi和Flume都可以充當Kafka生產者或消費者。
Flume-Kafka集成非常受歡迎,它有自己的名字:Flafka(我不是這樣做的)。Flafka包括Kafka源,Kafka通道和Kafka池。結合Flume和Kafka,Kafka可以避免自定義編碼并利用Flume經過實戰考驗的資源和接收器,通過Kafka通道的Flume事件將在Kafka代理中進行存儲和復制,以實現彈性。
組合工具可能看起來很浪費,因為它似乎在功能比較重疊。例如,NiFi和Kafka都提供了代理來連接生產者和消費者。但是,它們的做法不同:在NiFi中,大部分數據流邏輯不在生產者/消費者內部,而是在代理中,允許集中控制。NiFi的構建是為了做一件重要的事情:數據流管理。通過兩種工具的結合,NiFi可以充分利用Kafka可靠的流數據存儲,同時解決Kafka無法解決的數據流挑戰。
END
總結: