大數據流難以管理?借助StreamSets來駕馭
譯文【51CTO.com快譯】
物聯網數據有望發掘獨特的、前所未有的業務洞察力,不過前提是企業能夠成功地管理從眾多物聯網數據源流入的數據。許多企業試圖從物聯網項目獲得價值,但經常遇到的一個問題是數據漂移(data drift):源設備和數據處理基礎設施經常發生不可預測的變化,因而導致數據的結構、內容或含義發生變化。
無論流式處理還是批量處理,數據通常經由眾多工具,從數據源進入到最后的存儲位置。這條鏈上任何地方的變化都會導致下流系統中出現不完整、不準確或不一致的數據,無論是源系統的模式發生變化、編碼字段值的含義發生變化,還是參與數據生成的軟件組件出現升級或添加。
這種數據漂移的影響可能危害特別大,因為它們常常長時間沒有被發現,因而讓低逼真度數據污染了數據存儲和隨后的分析。在被發現之前,使用這種有問題的數據會導致錯誤的發現結果和拙劣的業務決定。等到最后發現了問題,通常借助數據科學家的手動數據清理和準備來加以解決,這給數據分析增添了硬性成本、機會成本和延誤。
StreamSets Data Collector
使用StreamSets Data Collector來構建和管理大數據攝取管道將有助于緩解數據漂移的影響,同時大大縮短花在數據清理上的時間。我們在本文中將逐步介紹一種典型的使用場合:實時攝取物聯網傳感器生成的數據,饋入到HDFS,以便分析,并使用Impala或Hive實現可視化。
不用編寫一行代碼,StreamSets Data Collector就能從眾多數據源攝取流數據和批量數據。StreamSets Data Collector可執行轉換,并在數據流傳輸過程中清理數據,然后寫入到眾多目的地。管道部署到位后,你就能獲得細粒度的數據流度量指標、檢測異常數據,并發出警報,那樣你就能密切關注管道性能。StreamSets Data Collector可以獨立運行,也可以部署在Hadoop集群上,它提供了支持眾多類型的數據源和目的地的連接件。
下列使用場合涉及從貨運集裝箱實時生成的數據。
數據漂移的第一個例子體現在貨運集裝箱使用的物聯網傳感器。由于長期以來的升級,生產一線的傳感器運行三種不同固件版本中的一種。每種版本添加新的數據字段,改變模式。為了從該傳感器數據獲得價值,我們用來攝取信息的系統必須能夠兼顧這種多樣性。
清潔和傳送數據
我們的管道從RabbitMQ系統讀取數據,該系統負責從生產一線的傳感器接收MQTT消息。我們進行核實,確保我們收到的消息正是想要處理的那些消息。為此,我們使用數據流選擇器處理程序,為入站消息指定數據規則。然后,我們使用該規則宣布與該規則的標準匹配的所有數據都傳送到下游,但是不匹配的任何數據一概被丟棄。
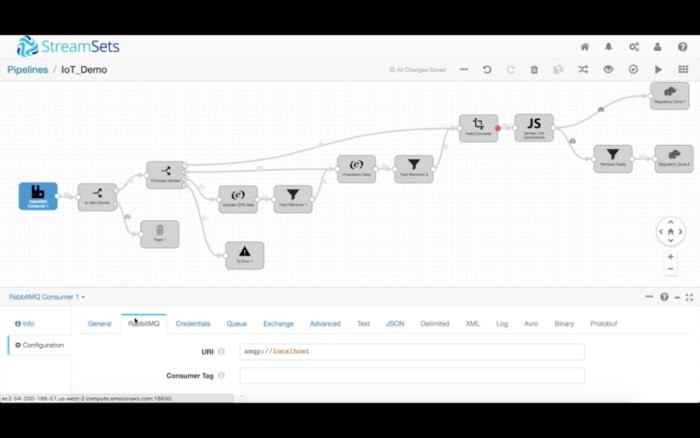
然后,我們使用另一個數據流選擇器,根據設備的固件版本來傳送數據。與版本1匹配的所有記錄走一條路徑,與版本2匹配的所有記錄走另一條路徑,以此類推。我們還指定了一條默認的全部捕獲(catch-all)規則,將任何異常發送到一條“錯誤”路徑。針對現代數據流,我們完全預料到數據會出現意外的變化,于是我們設立了一種從容的錯誤處理機制:把異常記錄引到本地文件、Kafka數據流或輔助管道。那樣一來,我們就能保持管道正常運行,同時事后重新處理不符合主要目的的數據。
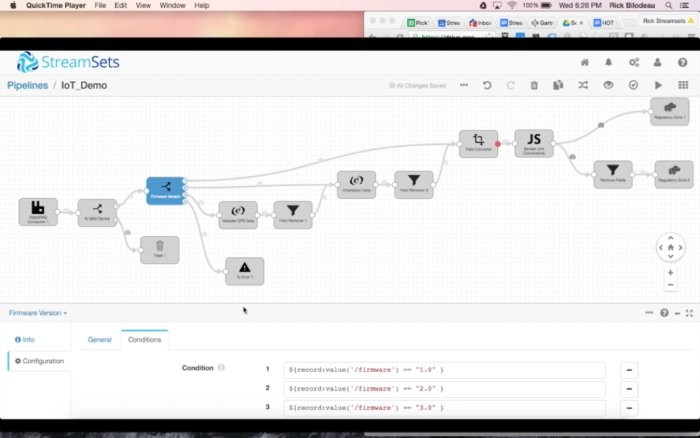
不妨從為固件版本3處理數據入手,這增添了緯度/經度數據。我們馬上想要確保那些字段出現在數據集中,而且數據包含有效的值。由于位置字段是一個嵌套的結構,我們想要對它作扁平化處理,最終丟棄嵌套的數據。
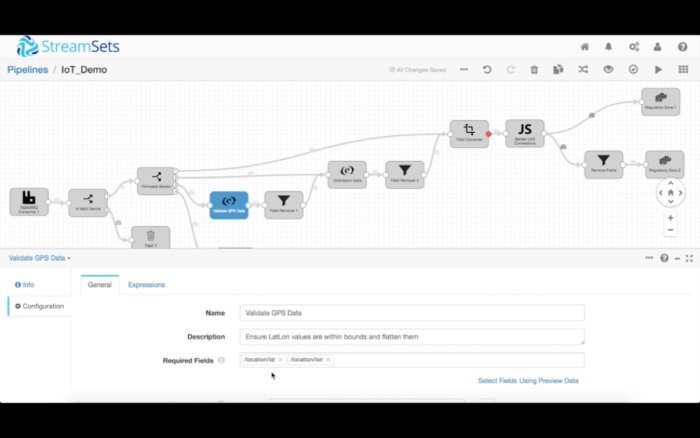
同樣,固件版本2包括新的方位字段(raw、pitch和roll),我們可以以一種類似的方式來核實和清潔它。
最后,所有設備版本都包含溫度和濕度讀數。首先,我們轉換這些讀數的數據類型。濕度轉換成了雙精度浮點型(double),濕度轉換成了整型(integer),日期轉換成了Unix時間戳。
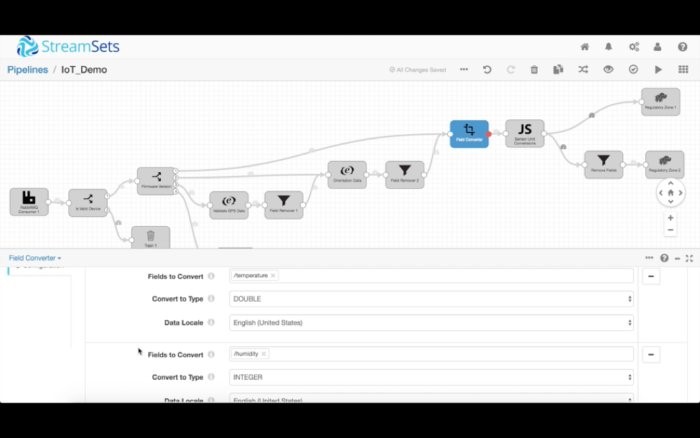
然后我們使用腳本處理程序來編寫一些自定義邏輯,比如將華氏度值轉換成攝氏度。StreamSets腳本處理程序支持Jython、Groovy和JavaScript。
清理數據(也就是根據固件版本和最終用途來傳送數據)后,我們把它發送到幾個HDFS目的地。
配置目的地
StreamSets本身支持許多數據格式,比如明文、分隔文本、JSON、Protobuf和Avro。在該例子中,我們將把數據寫入到一個經過壓縮的Avro文件。
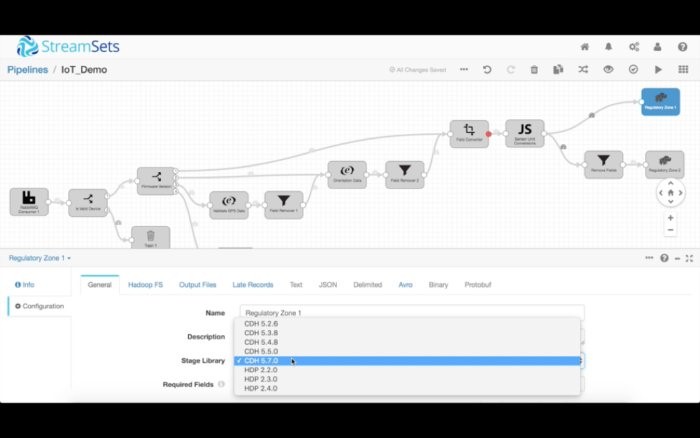
HDFS目的地可以靈活配置。你可以按照企業政策的要求來配置安全、動態配置輸出文件的路徑和位置,甚至決定寫入多個Cloudera CDH版本。
一旦你設計好了管道,就可以切換至預覽模式,使用數據樣本來測試和調試數據流。你可以逐步調試每一個處理程序,在任何階段分析數據狀態。
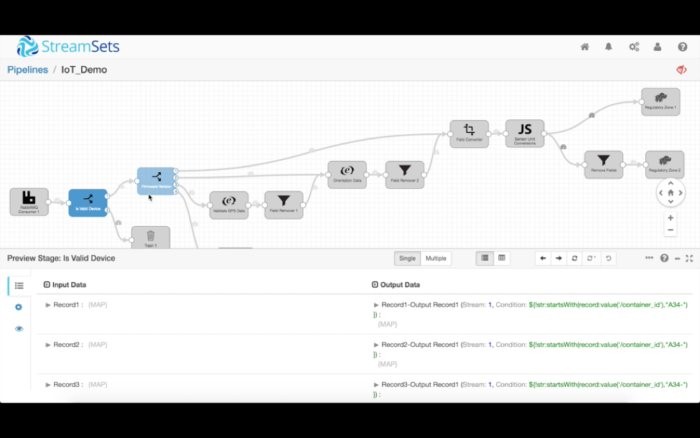
比如說,我們可以在下面看到,reading_date和temperature的數據類型被轉換成了長整型和雙精度浮點型。如果執行了轉換數據的運算,StreamSets也會提醒你。
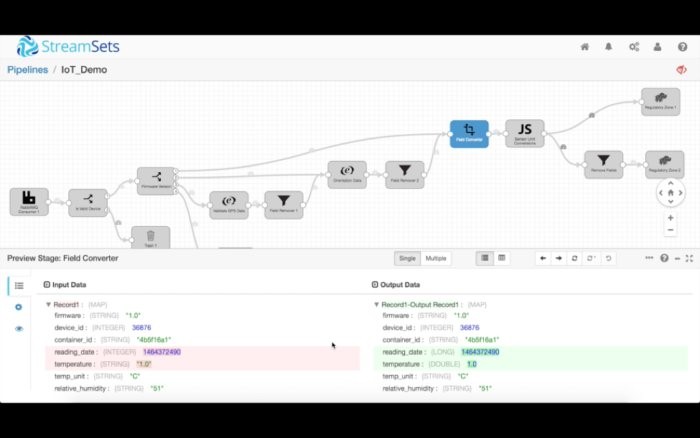
你還可以把異常或“極端情況”數據注入到數據流,看看它對你的數據流有何影響。預覽模式讓你可以輕松地調試復雜的管道,不需要把管道放入到生產環境。
執行管道
現在我們準備執行管道,開始將數據攝入到我們的集群中。點擊“開始”按鈕,用戶界面就會切換至執行模式。
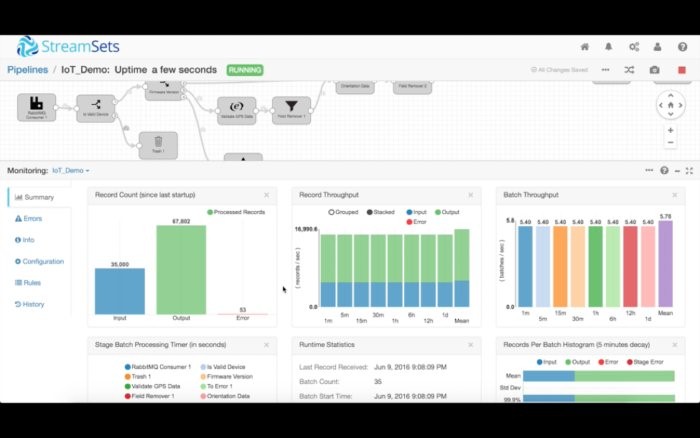
這時候,StreamSets Data Collector開始攝取數據,在內存中處理數據,然后將數據發送到目的地。屏幕底部的監控窗口顯示了各個實時度量指標,比如多少記錄讀入、多少記錄寫出。你還可以查看多少時間花在了每個處理程序上,它占用了多少內存。這些度量指標以及更多的指標還可以通過Java管理擴展(JMX)來加以訪問。
我們將數據送入到HDFDS后,立即就能開始查詢Impala,并運行分析、機器學習或可視化。
如今,由于用戶改動和更新系統,或者甚至更換平臺,物聯網設備、傳感器日志、Web點擊流及其他重要數據源在不斷變化。數據內容、結構、行為和含義的這些變化是不可預測、未宣布、沒完沒了的,它們會給數據處理和分析系統及其運營帶來重大危害。StreamSets Data Collector有助于管理數據基礎設施不斷出現的變化,馴服數據漂移,并確保數據處理系統的完整性。
原文標題:Tame unruly big data flows with StreamSets,作者:Arvind Pabhakar
【51CTO譯稿,合作站點轉載請注明原文譯者和出處為51CTO.com】