













GitHub超9千星:一個(gè)API調(diào)用六種架構(gòu),27個(gè)預(yù)訓(xùn)練模型
只需一個(gè)API,直接調(diào)用BERT, GPT, GPT-2, Transfo-XL, XLNet, XLM等6大框架,包含了27個(gè)預(yù)訓(xùn)練模型。簡(jiǎn)單易用,功能強(qiáng)大。
One API to rule them all。
3天前,著名最先進(jìn)的自然語(yǔ)言處理預(yù)訓(xùn)練模型庫(kù)項(xiàng)目pytorch-pretrained-bert改名Pytorch-Transformers重裝襲來(lái),1.0.0版橫空出世。
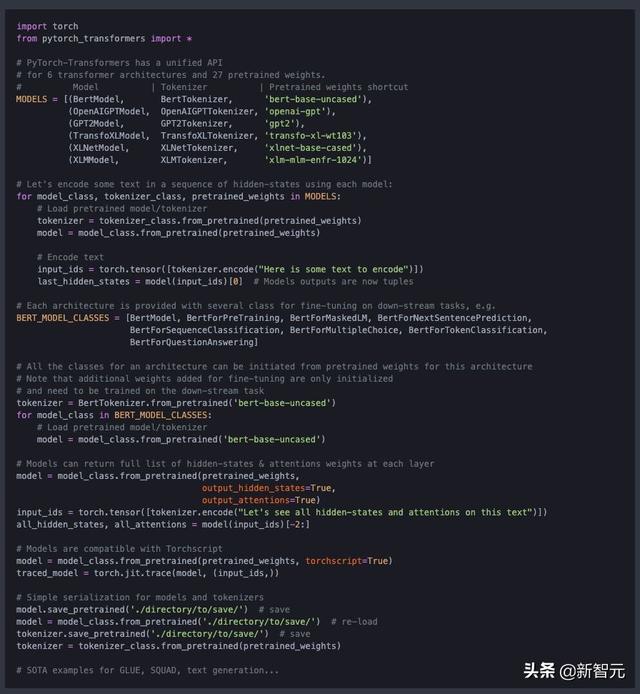
只需一個(gè)API,直接調(diào)用BERT, GPT, GPT-2, Transfo-XL, XLNet, XLM等6大框架,包含了27個(gè)預(yù)訓(xùn)練模型。
簡(jiǎn)單易用,功能強(qiáng)大。目前已經(jīng)包含了PyTorch實(shí)現(xiàn)、預(yù)訓(xùn)練模型權(quán)重、運(yùn)行腳本和以下模型的轉(zhuǎn)換工具:
- BERT,論文:“BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding”,論文作者:Jacob Devlin, Ming-Wei Chang, Kenton Lee,Kristina Toutanova
- OpenAI 的GPT,論文:“Improving Language Understanding by Generative Pre-Training”,論文作者:Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya Sutskever
- OpenAI的GPT-2,論文:“Language Models are Unsupervised Multitask Learners”,論文作者:Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei,Ilya Sutskever
- 谷歌和CMU的Transformer-XL,論文:“Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context”,論文作者:Zihang Dai, Zhilin Yang, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov.
- 谷歌和CMU的XLNet,論文:“XLNet: Generalized Autoregressive Pretraining for Language Understanding”,論文作者:Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le
- Facebook的XLM,論文:“Cross-lingual Language Model Pretraining”,論文作者:Guillaume Lample,Alexis Conneau
這些實(shí)現(xiàn)都在幾個(gè)數(shù)據(jù)集(參見(jiàn)示例腳本)上進(jìn)行了測(cè)試,性能與原始實(shí)現(xiàn)相當(dāng),例如BERT中文全詞覆蓋在SQuAD數(shù)據(jù)集上的F1分?jǐn)?shù)為93;OpenAI GPT 在RocStories上的F1分?jǐn)?shù)為88;Transformer-XL在WikiText 103上的困惑度為18.3;XLNet在STS-B的皮爾遜相關(guān)系數(shù)為0.916。
項(xiàng)目中提供27個(gè)預(yù)訓(xùn)練模型,下面是這些模型的完整列表,以及每個(gè)模型的簡(jiǎn)短介紹。
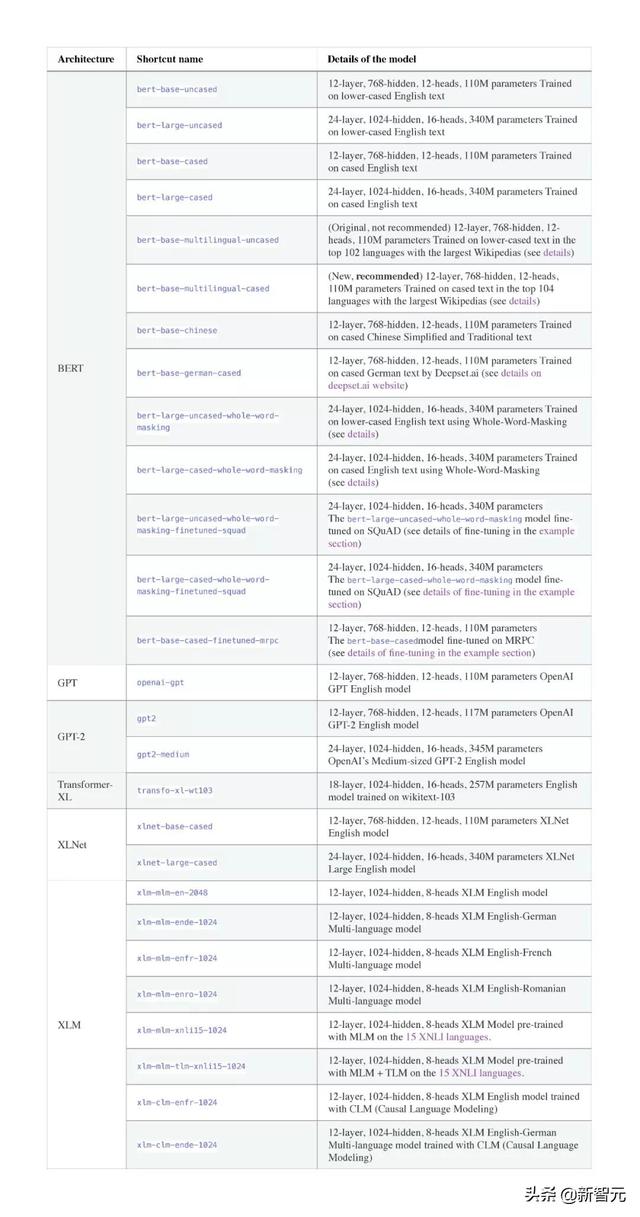
BERT-base和BERT-large分別是110M和340M參數(shù)模型,并且很難在單個(gè)GPU上使用推薦的批量大小對(duì)其進(jìn)行微調(diào),來(lái)獲得良好的性能(在大多數(shù)情況下批量大小為32)。
為了幫助微調(diào)這些模型,作者提供了幾種可以在微調(diào)腳本中激活的技術(shù) run_bert_classifier.py和run_bert_squad.py:梯度累積(gradient-accumulation),多GPU訓(xùn)練(multi-gpu training),分布式訓(xùn)練(distributed training )和16- bits 訓(xùn)練( 16-bits training)。
注意,這里要使用分布式訓(xùn)練和16- bits 訓(xùn)練,你需要安裝NVIDIA的apex擴(kuò)展。
作者在doc中展示了幾個(gè)基于BERT原始實(shí)現(xiàn)和擴(kuò)展的微調(diào)示例,分別為:
- 九個(gè)不同GLUE任務(wù)的序列級(jí)分類(lèi)器;
- 問(wèn)答集數(shù)據(jù)集SQUAD上的令牌級(jí)分類(lèi)器;
- SWAG分類(lèi)語(yǔ)料庫(kù)中的序列級(jí)多選分類(lèi)器;
- 另一個(gè)目標(biāo)語(yǔ)料庫(kù)上的BERT語(yǔ)言模型。
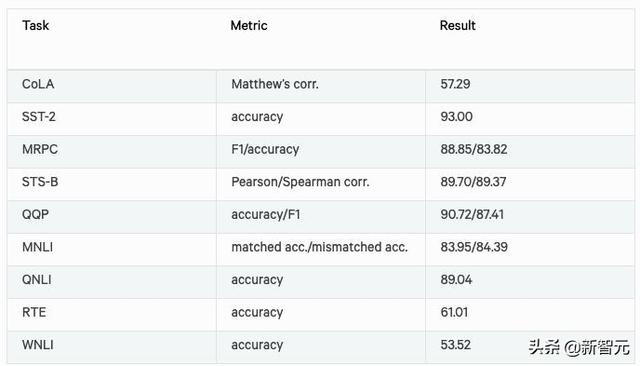
這里僅展示GLUE的結(jié)果:
該項(xiàng)目是在Python 2.7和3.5+上測(cè)試(例子只在python 3.5+上測(cè)試)和PyTorch 0.4.1到1.1.0測(cè)試。
項(xiàng)目地址:
https://github.com/huggingface/pytorch-transformers























