大數據計算框架Spark之任務調度
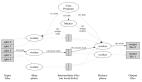
Spark有幾種資源調度設施。每個Spark Application(SparkContext實例)獨立地運行在一組executor進程內。cluster manager為應用間的調度提供設施。在每個Spark應用內,如果將多個job(多個spark action)提交給不同的線程,那么他們會并行運行。

1 Application間的資源調度
集群上,每個Spark application獲得獨立的一組executor JVM,這組executor JVM只為那個application運行task和存儲數據。如果多個用戶要共享集群,有不同的策略管理資源分配,這取決于使用的cluster manager。
資源的靜態分區(static partitioning)可被所有的cluster manager獲得,這樣每個application在他的生命周期內都可獲得他能使用的最多資源。standalone、YARN、coarse-grained Mesos mode這三種模式使用的就是這種方式。
1.1控制資源使用
集群類型下,如下配置資源分配:
- Standalone mode:application提交到standalone mode集群,將會以FIFO的順序運行,每個application會盡可能地使用所有可用節點,配置spark.cores.max來限制application使用節點的數目,或者設置spark.deploy.defaultCores。除了可以設置application可用內核數,還可以設置spark.executor.memory來控制內存的使用。
- Mesos:為了使用靜態分區(static partitioning)在Mesos集群上,spark.mesos.coarse=true,可以通過設置spark.cores.max來限制每個application的資源共享,通過設置spark.executor.memory來控制executor內存的使用。
- YARN:通過設置--num-executors選項,spark YARN客戶端可控制集群上有多少executor被分配(對應的配置屬性為spark.executor.instances),--executor-memory(對應的配置屬性spark.executor.memory)和--executor-cores(對應的配置屬性spark.executor.cores)控制了分配給每個executor的資源。
應用之間無法共享內存。
1.2動態資源分配
Spark提供了依據應用的工作量動態調整資源的機制。這意味著你的application不在使用的資源會返還給集群,當需要的時候再申請分配資源,這種特性對于多應用共享集群特別有用。
這個特性默認失效,但在所有coarse-grained cluster manager上都可用,如:standalone mode, YARN mode, 和Mesos coarse-grained mode。
使用這個特性有兩個要求。首先用于必須設置spark.dynamicAllocation.enabled=true,其次要設置external shuffle service在集群上的每個worker node并設置spark.shuffle.service.enabled=true。設置external shuffle service目的是executor可被移除但是不刪除他們生成的shuffle文件。
設置這個變量的方式為:
- 在standalone模式:設置spark.shuffle.service.enabled=true
- Mesos coarse-grained模式:在所有從節點運行$SPARK_HOME/sbin/start-mesos-shuffle-service.sh設置spark.shuffle.service.enabled=true
- YARN:詳見運行spark與YARN
1.3資源分配策略
當Spark不再使用executor時就出讓它,需要的時候再獲取它。因為沒有一個確定的方式預測將要被移除的executor是否在不久的將來會被使用,或者一個將要被添加的新executor實際上是否是空閑的,所以我們需要一系列試探來確定是移除executor(可能會移除多個)還是請求executor(可能會請求多個)。
請求策略
開啟Spark application動態分配資源特性,當pending task等待被調度時,Spark application會請求額外的executor。這就意味著,當前的這些executor無法同時滿足所有的task,這些task已經被提交,但是還沒有執行完。
Spark輪流請求executor。當task等待的時間大于spark.dynamicAllocation.schedulerBacklogTimeout時,真正的請求(申請executor的請求)被觸發,之后,如果未完成task隊列存在,那么每隔spark.dynamicAllocation.sustainedSchedulerBacklogTimeout秒請求被觸發一次。每一輪請求的executor數量以指數級增長。例如,***輪請求一個executor,第二輪請求2個,第三,四輪分別請求4,8個。
按指數形式增長的動機有兩個,首先,起初應用應該慎重地請求executor,以防只需幾個executor就能滿足需求,這和TCP慢啟動類似。其次,當應用確實需要更多的executor時,應用應該能夠及時地增加資源的使用。
移除策略
當executor閑置超過spark.dynamicAllocation.executorIdleTimeout秒時,就將他移除。注意,大多數情況下,executor的移除條件和請求條件是互斥的,這樣如果仍然有待調度的task的情況下executor是不會被移除的。
executor優雅地退役
非動態分配資源情況下,一個Spark executor或者是由于失敗而退出,或者是因相關application退出而退出。這兩種情況下,不在需要與executor相關聯的狀態并且這些狀態可以被安全地丟棄。動態分配資源的情況下,當executor被明確移除時,application仍然在運行。如果application要想使用這些由executor存儲和寫下的狀態,就必須重新計算狀態。這樣就需要一種優雅的退役機制,即在executor退役前保留他的狀態。
這個機制對于shuffles特別重要。shuffle期間,executor自己的map輸出寫入本地磁盤。當其他的executor要獲取這些文件的時候,這個executor充當了文件服務器的角色。對于那些落后的executor,他們的task執行時間比同輩要長,在shuffle完成之前,動態資源分配可能移除了一個executor,這種情形下,那個executor寫入本地的文件(即executor的狀態)不必重新計算。
保留shuffle文件的辦法就是使用外部的shuffle服務,這是在Spark 1.2中引入的。這個外部的shuffle服務指的是長時間運行的進程,它運行與集群的每個節點上,獨立于application和executor。如果這個服務可用,executor就從這個服務獲shuffle file,而不是彼此之間獲取shuffle file。這意味著executor生成的任何shuffle文件都可能被服務包含,即使在executor生命周期之外也是如此。
executor除了寫shuffle 文件到本地硬盤,還緩存數據到硬盤或內存中。但是,當executor被移除后,緩存到內存中的數據將不可用。為了解決這一問題,默認地緩存數據到內存的executor永遠不會被刪除。可以通過spark.dynamicAllocation.cachedExecutorIdleTimeout配置這一行為,
2 Application內的資源調度
概述
給定的application內部(SparkContext 實例),如果多個并行的job被提交到不同的線程上,那么這些job可以同時執行。這里的job指的是Spark action及Spark action觸發的計算task。Spark scheduler是線程安全的,支持spark application服務于多個請求。
默認地Spark scheduler以FIFO的順序執行job,每個job被切分為一到多個stage(例如,map和reduce),當***個job的stage的task啟動后,這個job優先獲得所有可用資源,然后才是第二,三個job......。如果隊頭的job不必使用整個集群,之后的job就能立即啟動。如果隊頭的job較大,那么之后的job啟動延遲會比較明顯。
從Spark 0.8開始,也可以通過配置實現隊列間的公平調度。Job間的task資源分配采用單循環的方式。所有job都會獲得大致相同的集群資源。這就意味著,當有長job存在時,提交的短job可以立即獲得資源啟動運行而不必等到長job執行完畢。可以設置spark.scheduler.mode為FAIR
- val conf = new SparkConf().setMaster(...).setAppName(...)
- conf.set("spark.scheduler.mode", "FAIR")
- val sc = new SparkContext(conf)
公平調度池(可能多個)
公平調度器也支持在池中對job分組并給每個池配置不同的選項。這有助于為更重要的job設置高優先級池,例如把每個用戶的job分到一組,并且給這些用戶相等的資源不論有多少并行task,而不是給每個job相等的資源。
不需要任何干預,新job會進入默認池,但是可以使用spark.scheduler.pool設置job池。
- sc.setLocalProperty("spark.scheduler.pool", "pool1")
設置完后,這個線程(通過調用RDD.save, count, collect)提交的所有job都會使用這個資源池的名稱。設置是針對每一個線程的,這樣更容易實現一個線程運行一個用戶的多個job。如果想清除與一個線程相關的池,調用:sc.setLocalProperty("spark.scheduler.pool", null)
池默認行為
默認地每個池都能獲得相等的資源(在默認池中每個job都能獲得相等的資源),但在每個池內部,job以FIFO 的順序運行。例如如果為每一個用戶創建一個池,這就意味著每一個用戶將獲得相等的資源,并且每個用戶的查詢都會按順序運行而不會出現后來的查詢搶占了前面查詢的資源
配置池屬性
可以通過修改配置文件改變池屬性。每個池都支持三種屬性:
- schedulingMode:可以是FIFO或FAIR,控制池中的job排隊等候或公平地分享集群資源。
- weight:控制資源分配的比例。默認所有池分配資源比重都是1。如果指定一個池的比重為2,那么他獲得的資源是其他池的2倍。如果將一個池的比重設的很高,比如1000,那么不論他是否有活躍的job,他總是***個開始執行task。
- minShare:除了設置總體的占比之外,還可以對每個池設定一個最小資源分配(例如CPU核數)。在根據比重重新分配資源之前,公平調度器總是試圖滿足所有活躍池的最小資源需求。minShare屬性能以另一種方式確保一個池快速地獲得一定數量的資源(10個核)而不必給他更高的優先級。默認地minShare=0。
調用SparkConf.set,可以通過XML文件配置池屬性:
- conf.set("spark.scheduler.allocation.file", "/path/to/file")
每個池一個,在XML文件中沒有配置的池使用默認配置(調度模式 FIFO, weight 1, minShare 0),例如:
- <?xml version="1.0"?><allocations>
- <pool name="production">
- <schedulingMode>FAIR</schedulingMode>
- <weight>1</weight>
- <minShare>2</minShare>
- </pool>
- <pool name="test">
- <schedulingMode>FIFO</schedulingMode>
- <weight>2</weight>
- <minShare>3</minShare>
- </pool></allocations>