一個系統,搞定閑魚服務端復雜問題告警-定位-快速處理
引言
服務端問題排查(服務穩定性/基礎設施異常/業務數據不符合預期等)對于開發而言是家常便飯,問題并不可怕,但是每天都要花大量時間去處理問題會很可怕;另一方面故障的快速解決至關重要。那么目前問題排查最大的障礙是什么呢?我們認為有幾個原因導致:
- 大量的告警信息。
- 鏈路的復雜性。
- 排查過程繁復。
- 依賴經驗。
- 然而實際工作中的排查過程并非無跡可尋,其排查思路和手段是可以沉淀出一套經驗模型。
沉淀路徑
下面是我的訂單列表的簡單抽象,其執行過程是先拿到我買到的訂單列表。訂單列表中又用到了賣家,商品以及店鋪信息服務,每個服務又關聯著單次請求中提供服務對應的主機信息。
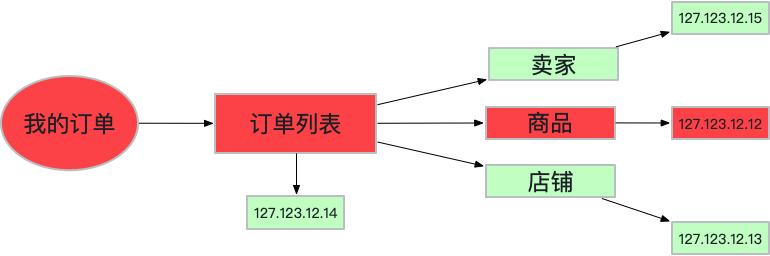
以線上常見的服務超時為例,上圖中因為127.123.12.12這臺機器出現異常導致商品服務超時,進而導致我的訂單列表服務超時。根據日常中排查思路可以總結出以下分析范式:
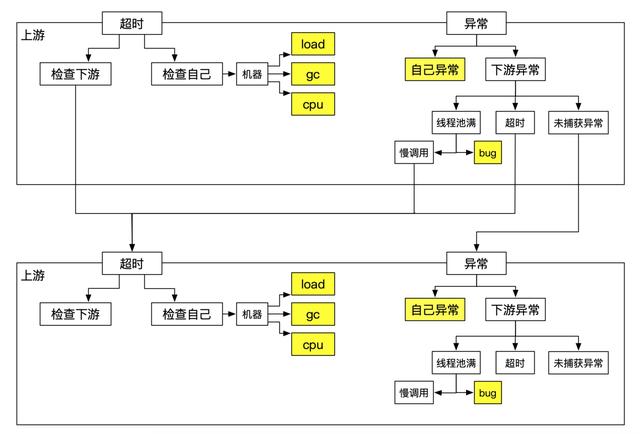
上面這種分析范式看起來很簡單清晰,但是它首先面臨著以下問題:
- 如何準確界定超時/異常。
- 上下游調用鏈路如何生成。
- 自己和下游,如何確定誰的問題(超時&異常)。
- 下游異常時,如何區分超時/線程池滿/未知異常。
- 以上問題本質上是底層數據埋點問題,幸運的是阿里集團完備的數據建設使得這些問題基本都能找到很好的解決方案。有了底層數據支撐再配合上層抽象出來的這樣一套分析模型,設計并實現一套完全自動化問題定位系統是完全有可能的。
系統架構
我們認為這樣一套問題自動定位的系統一定要滿足4個目標,這同時也是整個系統的難點所在。
- 準(定位準確率不亞于開發人員)
- 定位結果與真實原因哪怕有一點出入,影響的都是開發對系統本身的信心,所以準是一大前提。
- 快(定位結果早于監控發現)
- 監控作為發現問題最重要的手段,只有監控發現問題時能立馬定位出結果,才真正具有實用價值。
- 簡單(從問題發現到定位結果之間的最短鏈路)
- 線上問題/故障定位爭分奪秒,操作路徑越簡單越有價值。
- 自動化
- 全程不需開發人員參與。
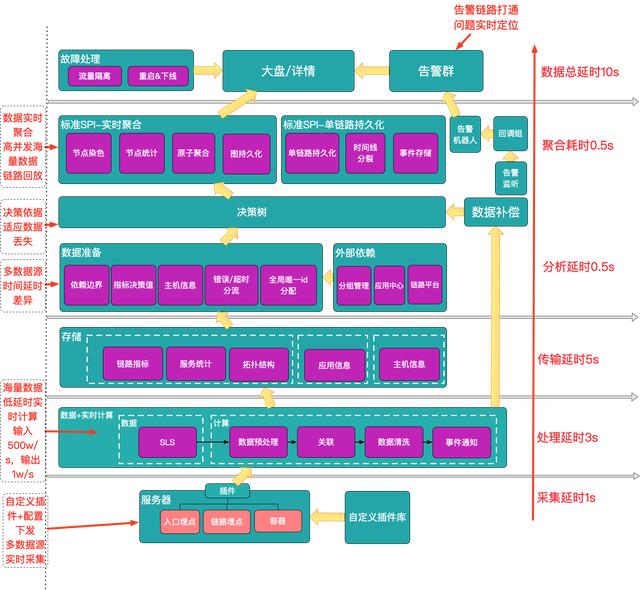
圍繞著這4大目標,我們實現了上面這樣一套完整的定位系統,實現了從告警->定位->快速處理這樣一套完整閉環。自下而上劃分為4個模塊,下面講一下每個模塊解決的問題以及其難點。
數據采集
數據采集模塊主要負責埋點數據的采集與上報,需要解決兩個問題:
- 海量數據。線上的埋點數據每時每刻都在產生,其數據量可達到80G/分鐘。
- 采集時延。快作為整個系統追求的一大目標,數據采集需要滿足低時延。
- 可擴展指標。隨著模型的不斷演進完善,需要實現靈活的增加采集指標(cpu/gc/gc耗時/線程數等)。
- 采用SLS+自定義插件庫來實現線上流量埋點數據的采集與上報。SLS是阿里云研發針對日志類數據的一站式服務,其生命周期管理(TTL)以及極低的存儲成本可以很好的解決海量數據帶來的成本問題。
實時計算
實時計算以數據采集的輸出作為輸入,負責對數據進行一輪預處理,包括鏈路數據的關聯(請求都有唯一標識,按照標識group by),數據清洗(只選取需要的數據)以及事件通知。
- 計算延時。從拿到數據到最后過濾輸出,要盡可能壓縮計算延時來提升整個系統的時效性。
- 多數據源協同。數據來源于底層不同的數據源,他們之前對應著不同的到達時間,需要解決數據等待問題。
- 數據清洗。需要有一定的策略來進行一輪數據清洗,過濾出真正有效的數據,來減少計算量以及后續的存儲成本。
- 存儲成本。雖然經過了一輪數據清洗,但是隨著累積數據量還是會線性增長。
實時分析
當收到事件通知后根據實時計算產出的有效數據進行自動化的分析,輸出問題的發生路徑圖。需要解決:
- 實時拓撲 vs. 離線拓撲。實時拓撲對埋點數據有要求,需要能夠實時還原調用鏈路,但依賴采集數據的完整度。離線拓撲離線生成,不依賴采集數據的完整度,但不能準確反應當前拓撲。最后選擇了實時還原拓撲方式保證準確率。
- 數據丟失。雖然實時計算中有解決數據協同等待的問題,但無法徹底解決數據的丟失問題(數據延時過大/埋點數據丟失),延時以及丟失數據需要采取不同的處理策略。
- 分析準確率。影響準確率的因素很多,主要包括數據完整度以及分析模型的完備度。
聚合&展示
按照時間窗口對問題發生路徑進行實時聚合,還原問題發生時的現場。將監控,告警和診斷鏈路進行了互通,最大化的縮短從問題發現到結果展現的操作路徑。
- 實時聚合 vs. 查詢時聚合。查詢時聚合性能差但是很靈活(可以根據不同的條件聚合數據),反之實時聚合犧牲了靈活性來保證查詢性能。這里我們選擇保證查詢性能。
- 并發問題。采用實時聚合首先要解決的是并發寫(線上集群對同一個接口的聚合結果進行修改)。最后采取將圖拆解成原子key,利用redies的線程安全特性保證線上集群的寫并發問題。
- 存儲成本 vs. 聚合性能。為了解決并發問題,我們利用redis的線程安全特性來解決,但帶來的一個問題就是成本問題。分析下來會發現聚合操作一般只會跨越2~5個窗口,超過之后聚合結果就會穩定下來。所以可以考慮將聚合結果持久化。
效果
系統上線以來經受住了實踐的檢驗,故障以及日常問題的定位效率得到顯著提升,并獲得了穩定性的結果。將日常問題/故障定位時間從10分鐘縮短到5s以內,以下是隨機選取的兩個真實case。
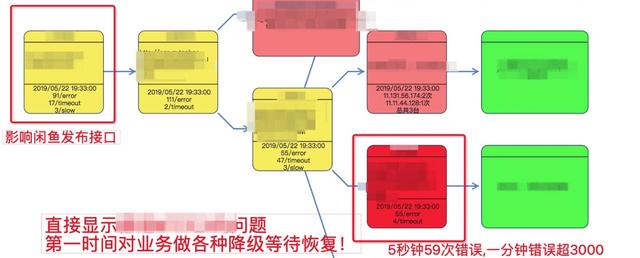
案例1:閑魚發布受影響
監控系統發現商品發布接口成功率下跌發出來告警信息,點擊告警診斷直接跳轉到問題現場,發現是因為安全某個服務錯誤率飆升導致,整個過程不到5s。
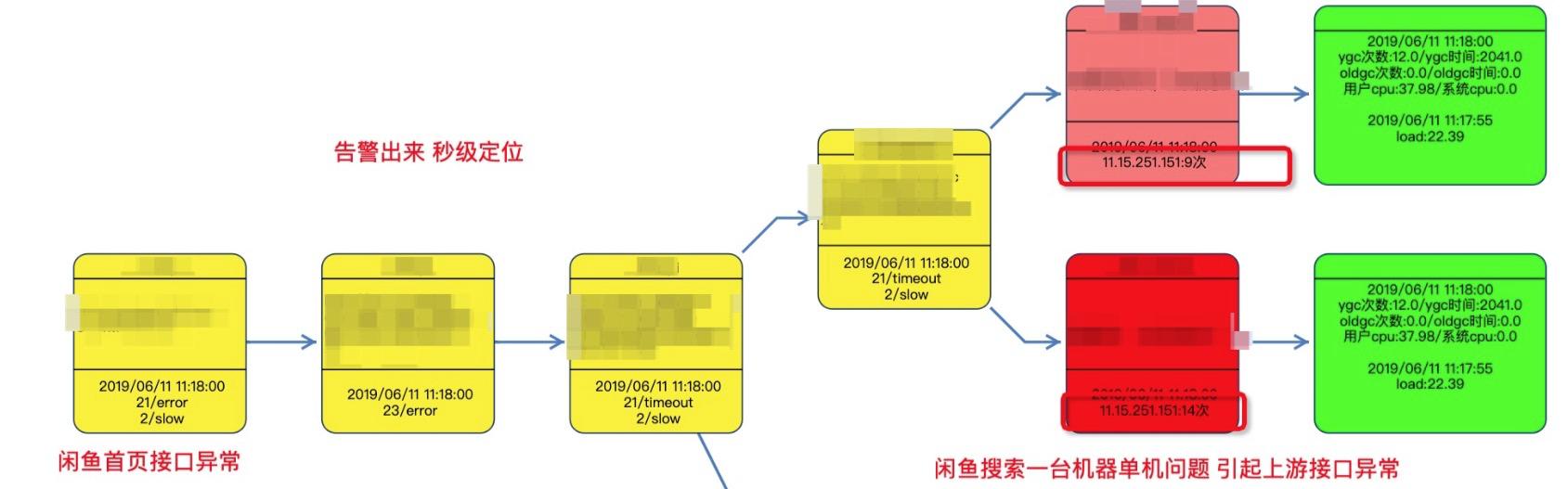
案例2: 首頁因為單機問題受到影響
閑魚首頁因為單機gc問題抖動觸發大量告警信息,秒級給出問題發生路徑。根據診斷路徑顯示搜索單機出現大量異常。
總結
目前整個系統主要聚焦服務穩定性相關的問題定位,仍然有許多場景有待覆蓋,信息有待補全,措施有待執行,定位只是其中的一環。最終目的一定是建設問題定位,隔離,降級,與快速恢復這樣一個完整閉環。要想實現這樣一個完整閉環,離不開底層各個子系統的數據建設,核心在于兩點一面的建設:
- 底層數據建設。完備的數據支持一定是整個系統能夠發揮價值的前提,雖然現階段很多系統在產出這方面的數據,但仍然遠遠不夠。
- 完備的事件抽象。數據不僅僅局限于請求產生的埋點數據,其范圍應該更為廣泛(應用發布,線上變更,流量波動等),任意可能對線上造成影響的操作都應該可以抽象成一個事件。
- 知識圖譜的建立。僅僅有完備的事件并沒有多大的價值,真正的價值在于把這些事件關聯起來,在問題/故障發生時第一時間還原現場,快速定位問題。