













如果不是造化弄人,我現在已經是某某公司的CEO了……
最近上海垃圾分類以來,許多人都變了:珍珠奶茶也不喝了,外賣也不點了,丟個垃圾戰戰兢兢跟期末考試一樣,繼“今天誰洗碗?”之后,兩口子間的爭執又多了一個:“今天誰去倒垃圾?”
看到這些新聞,我一拍大腿,“啊呀”叫出聲:造化弄人啊,如果我幾年前提的AI分類付諸實施,現在的人哪需要受這種罪啊!而且我的想法一定符合時代需要,要是當初落地了,沒準兒我現在就是個CEO了!
事情還要從幾年前說起。
當時我們五六個人組隊參加大學生創業比賽,以設立一家公司的形式,對公司前期籌備、后期經營、財務管理狀況做出規劃,最終形成商業計劃書提交。
“第一步我們要開動腦筋,想一下生活中,人們有哪些需求沒有被滿足?先把公司業務確定下來,一周后咱們碰碰想法。”組長在第一次開會中總結道。
生活中那些不便和痛苦的細節里,往往隱藏著無限商機。
為此,我絞盡腦汁遍歷生活里各種不便的瞬間,終于梳理出一個非常有前景的朝陽項目:
利用AI進行垃圾分類
每次提著一袋子垃圾,來到標著“可回收物”、“不可回收物”的垃圾桶面前,我都要猶豫好幾秒鐘——這到底是可回收還是不可回收?究竟哪些是可回收的,哪些又是不可回收的?自己心里沒譜兒,現場查資料又費勁,最后只得憑感覺投遞,結果當然不可避免地錯誤百出,也導致這個可回收和不可回收的垃圾桶失去了意義。
“快速簡便地進行垃圾分類就是需求,這么多垃圾,人為分類麻煩,不如叫機器替我們做,在垃圾桶上安放智能AI系統,來垃圾了掃描一下,自動判斷該投入什么垃圾桶,省時高效,對環境相當友好!
我喜不自勝,在第二次會議上提出這個點子,等著大家的認可。
然而,組長一句權威引用,讓這個會在未來大放異彩的朝陽項目胎死腹中——
“沒用的,某當紅明星說過,他曾經特別認真地把垃圾分好類,分別投進可回收和不可回收垃圾桶,然而保潔阿姨清理時卻一股腦地把所有垃圾都混在一起,任你之前分得多仔細都沒用!”組長搖頭否決。
好吧(°ー°〃),礙于這位明星的權威,我沒再堅持,轉而跟大家談論別的點子,雖然最后方案交上去以后,我們組慘遭淘汰多年來,我也默認了垃圾分類無法貫徹的結論,這個歷史難題就交給歷史去解決吧,有關AI智能分類的想法漸漸隨風逝去……直到今年上海推出垃圾分類管理條例后,支付寶上線的垃圾分類小程序火速躥紅,我才感到會心一擊:這不就是我幾年前被扼殺的點子嗎?當年被認為無用的垃圾分類,竟然站到了歷史高點,成為舉國參與的大運動!
可悲可嘆!我就問一句,組長,你后悔了嗎?
我把這個事情講給朋友聽,朋友不以為然,垃圾分類固然是大勢所趨,可你那AI分類太難了,目前的科技還沒達到那個水平吧……
那你可低估AI了,它不會的,可以學呀!
垃圾分類交給AI
在這個言必談AI的時代,人們一提到AI,伴隨而來的就是ML(機器學習)、DL(深度學習),這三者之間究竟有什么關系呢?
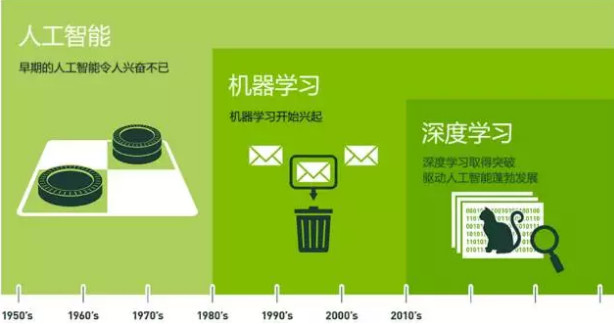
人工智能(AI)
在1956年作為一個獨立學科誕生,其理論包括計劃、理解語言、識別物體和聲音、學習和解決問題。AI又分為強AI和弱AI:強AI即科幻電影里無所不能的機器人,所有技能都強于人類;現在我們談的AI大多是弱AI,像AlphaGo通過不斷學習、改進算法,在下圍棋這件事情上能夠戰勝人類棋王,但在其他領域一無所能。
機器學習(ML)
AI的一個子集,顧名思義,讓機器具備獲取知識的能力,利用算法解析原始數據,不斷學習來對發生的事務做出判斷和預測。機器的學習思維和人腦有很大的差距,在底層需要大量的數學理論作為技術支撐,常見的如決策樹、貝葉斯網絡、支持向量機等。
深度學習(DL)
目前實現AI先進的技術,利用多層人工神經網絡構建的算法模型,得出我們所期望的結果。深度學習分為訓練和推理兩個階段,訓練階段中,從原始數據經過算法分析得到預估值的過程稱為前向傳播,將預估值與原始數據之間的差異迭代修正參數的過程稱為反向傳播,在這不停地試錯過程中得出一個趨近完美的模型。將訓練好的模型放到實際生產業務中應用,即推理階段。
簡單一句話:機器學習是實現人工智能的一種方式,深度學習是機器學習的一種技術手段。
就像垃圾分類小程序里,輸入某種垃圾會有相應分類跳出來,我們也可以把這些原始素材庫“喂”給AI,建立模型進行訓練,最終讓它學會垃圾自動分類并應用出去,而且這兩年隨著AI崛起,計算機視覺系統自動篩選也讓智能垃圾分類成了可能。
從此,人們再也不用為那些“珍珠奶茶幾步走”,“到底多大尺寸的豬大骨才算干垃圾標準下的豬大骨”等五花八門的分類要求心煩了——垃圾桶前一掃描,AI告訴你怎么放,人做著不容易的,交給機器去做,豈不是簡單快捷、省時省力?
要實踐,要落地
那么問題來了,如何落地?機器學習大量建模、調參、訓練的過程,肯定離不開一個高性能基礎平臺吧!
那當然,OpenAI研究報告顯示:2012年起AI消耗的計算力平均每3.5個月增長一倍,過去6年已增長了30萬倍。人工智能產業快速發展驅動AI計算向精細化、集群化、多元化邁進,如今構建高性能的AI基礎架構平臺,更需要端到端進行基礎架構設計。
這不,今年夏天戴爾易安信就推出了一款AI基礎架構平臺——DSS 8440。
DSS 8440是一款2路4U服務器,專為機器學習應用程序和其他需要高計算性能的高要求工作負載設計,配備多達10個加速器、高速PCIe結構和大量的本地存儲,非常適用于機器學習、訓練應用程序以及其他計算密集型工作負載。
DSS 8440專門針對復雜的訓練階段進行設計,可提供更高算力,快速處理復雜的工作負載(如圖像識別、面部識別及自然語言處理)。
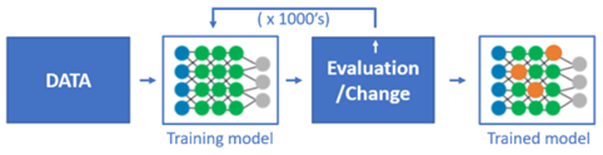
(機器學習訓練流程)
機器學習包括兩個階段:訓練(training)和推理(inference),雖然這兩個階段都可以通過GPU進行加速,但是它們實現的方式卻不相同。
機器學習訓練階段通過加權的多層算法,將大量數據迭代計算“訓練”出模型,與特定的目標結果進行比較、不斷調整參數使其最終形成一個“訓練有素”的模型;
推理階段是將訓練好的模型用于生產中,基于生產數據做出相應預測。
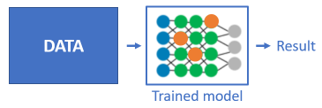
(機器學習推理流程)
除了超高算力,DSS 8440還具備以下特點:
特 點
☑ GPU密度高
4U機箱內可支持10塊NVIDIA Tesla V100 GPU,相比友商8卡機型,單機密度提升25%;針對大模型訓練,更多GPU卡同時參與任務訓練,提升數據并行或者模型并行的訓練速度;針對多用戶共享GPU平臺,更多GPU卡可支持更多用戶在線進行模型訓練。
☑ 環境適應能力強
在35℃環境中支持高達205W CPU,配置性能更強的處理器,提供模型訓練更高的數據處理能力和調度性能;在機器前端有12個大尺寸風扇,充分保障GPU自身散熱,使GPU保持好的性能狀態,并且減少機房空調耗電,起到綠色節能的作用。
☑ 更多本地存儲空間
機箱內部支持10塊本地硬盤(NVMe SSD和SAS/SATA SSD),滿足本地訓練數據集存儲容量要求和KB級別小文件(圖像、語音)IO性能要求,提高文件數據導入導出速度。
☑ I/O擴展能力好
在滿配了10塊GPU后,依然可以提供10個x16 PCI-E槽位用于擴展IO流量;擴展Infiniband 100Gb EDR,100Gb/25Gb低延遲以太網絡,并且支持RDMA技術實現GPU direct computing;提供遠程節點間GPU直接訪問,可大程度降低GPU服務器之間的通信延遲。
DSS 8440適合的工作負載:
▐ 深度學習
DSS 8440的高密集型加速器非常適合機器學習訓練任務——(例如:圖像識別、氣候建模、自然語言處理等),能夠為各種開源軟件框架及其相關的優化數學庫提供高性能。
此外,它還支持創建高度復雜的多層神經網絡,在更低的成本基礎上,提供和同等競爭性訓練產品一樣的速度。
▐ HPC/計算密集型
DSS 8440可為科學和工程環境中的建模、仿真和預測分析等需要大量計算的工作負載提供更高的效率和生產力水平;DSS 8440單個機箱中使用多達10個GPU,為多個部門和工作負載提供資源,使用戶獲得更高的操作靈活性。
有了這樣的利器,垃圾分類不再發愁!
《上海灘之垃圾分類》
紙巾~(噔噔噔~)
干垃圾~(噔噔噔~)
不管多濕它都是干垃圾~
瓜子皮~(噔噔噔~)
濕垃圾~(噔噔噔~)
不管多干它都是濕垃圾~
相關閱讀推薦:報告說,協作式AI、多模界面等四種技術將幫助企業面向未來業務
了解更多數字化轉型方案查看此鏈接:
https://www.dellemc-solution.com/home/index.html














