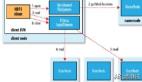
大數據核心框架MapReduce過程解析
首先MapReduce很明顯是分為Map階段和Reduce階段。兩個階段分別做什么呢?
小編自己畫了個圖,大家共勉一下
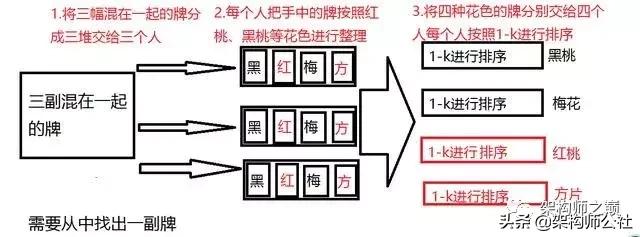
圖中1-2過程為map過程,3為Reduce過程,接下來看一張專業(yè)圖片,兩張對比一起看
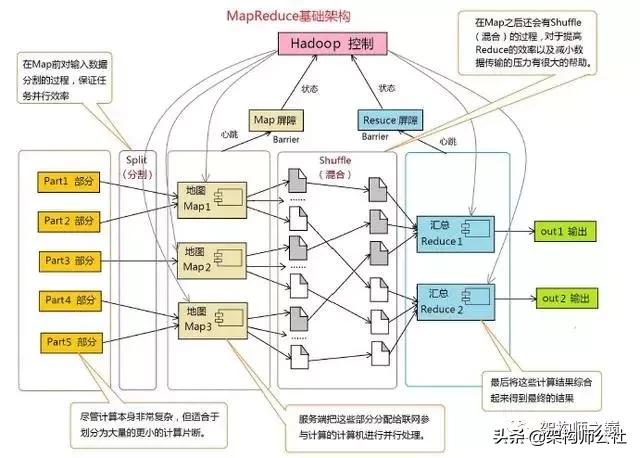
在整個mapReduce過程包含很多復雜的處理過程,而我們要學習的就是其中幾個過程包含,Split過程、Partitione過程還有Shuffle過程,舉一個實例的話
假設我們手上有很多復雜數據,那么怎樣來處理呢? 第一步就是分類,把數據分類。 分類后的數據就不復雜了,這就是異而化同。 分類之后數據還是很多,怎么辦呢? 第二步,分割。 分割就是把數據切分成小塊, 這樣就可以并發(fā)或者批量處理了, 這就是大而化小。
回到 map-reduce概念上, map的工作就是切分數據,然后給他們分類,分類的方式就是輸出key,value對,key就是對應“類別”了。 分類之后,reducer拿到的都是同類數據,這樣處理就很容易了。
大數據一般采用的HDFS 解決了大數據存儲的問題,那么 MapReduce 自然要解決的是數據計算問題在處理大數據計算中,一臺機器是無法滿足大批量數據計算的,這個時候就需要使用MapReduce,MapReduce是一種編程模型,用于大規(guī)模數據集的并行計算,需要將數據分配到大量的機器上計算,每臺機器運行一個子計算任務,最后再合并每臺機器運算結果并輸出。 MapReduce 的思想就是 『分而治之』
MapReduce 將整個并行計算過程抽象到兩個函數,在 Map 中進行數據的讀取和預處理,之后將預處理的結果發(fā)送到 Reduce 中進行合并。一個簡單的 MapReduce 程序只需要指定 map()、reduce()、 input 和output,剩下的事由框架完成。
Map ( 映射 ) : 對一些獨立元素組成的列表的每一個元素進行指定的操作,可以高度并行。
Reduce( 化簡 ) : 對一個列表的元素進行合并。
MapReduce執(zhí)行流程
以經典的 WordCount 的例子來說明一下MapReduce的執(zhí)行流程,WordCount就是統(tǒng)計每個單詞出現的次數。
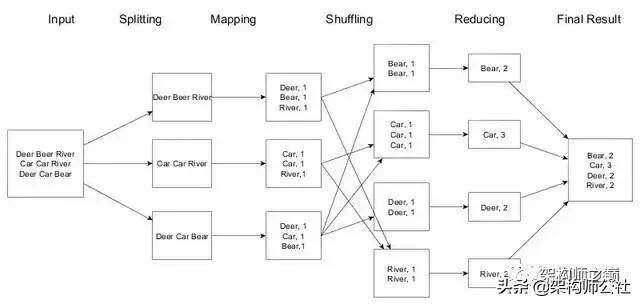
MapReduce計算框架的一般流程有以下幾個步驟:
輸入 ( Input ) 和拆分 ( Split ):
對數據進行分片處理。將源文件內容分片成一系列的 InputSplit,每個 InputSplit 存儲著對應分片的數據信息,記住是對文件內容進行分片,并不是將源文件拆分成多個小文件。
迭代 ( iteration ):
遍歷輸入數據,并將之解析成 key/value 對。拆分數據片經過格式化成鍵值對的格式,其中 key 為偏移量,value 是每一行的內容,這一步由MapReduce框架自動完成。
映射 ( Map ):
將輸入 key/value 對映射 ( map ) 成另外一些 key/value 對。MapReduce 開始在機器上執(zhí)行 map 程序,map 程序的具體實現由我們自己定義,對輸入的 key/value 進行處理,輸出新的 key/value,這也是hadoop 并行事實發(fā)揮作用的地方。
洗牌 ( Shuffer ) 過程:
依據 key 對中間數據進行分組 ( grouping )。這是一個洗牌的過程,得到map方法輸出的 對后,Mapper 會將它們按照 key 值進行處理,這包括 sort (排序)、combiner (合并)、partition (分片) 等操作達到排序分組和均衡分配,得到 Mapper 的最終輸出結果交給 Reducer。mapper 和 reducer 一般不在一個節(jié)點上,這就導致了reducer 需要從不同的節(jié)點上下載數據,經過處理后才能交給 reducer 處理。
歸并( Reduce ):
以組為單位對數據進行歸約 ( reduce )。Reducer 先對從 Mapper 接收的數據進行排序,再交由用戶自定義的 reduce方法進行處理。
迭代:
將最終產生的 key/value 對保存到輸出文件中。得到新的 對,保存到輸出文件中,即保存在 HDFS 中。