數據湖核心能力解析
一、數據湖發展趨勢分析

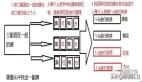
當下,數據湖已成為企業數據平臺架構的重要組成部分。傳統的數據平臺架構一般由數據湖、流式計算和 OLAP 引擎查詢三個部分組成:
- 數據湖:由 Hadoop 搭建的大數據平臺承載,負載海量數據存儲與批量計算。
- 流式計算:一般由 Flink 組件承載,負責實時的數據流處理。
- OLAP 數倉:可選擇技術比較多,包括:開源的 Doris、StarRocks、Clickhouse 等以及傳統數倉,負責承載數據查詢業務。
這三個平臺在以往通常是獨立建設的,集群也是獨立部署。三者之間數據互相拉通,采用以下方案:
湖平臺與流式平臺的互通:通常采用 Lambda 架構搭建實時計算平臺和離線批量計算平臺,以實現流式計算與數據湖之間的協同。
流式計算平臺與 OLAP 倉互通:一般實際與計算引擎的數據源對接方式拉通,還會基于 Kappa 架構在流式計算中進行實時的數據加工處理,將計算結果寫入數倉中,以實現實時的 OLAP 查詢,這也是通常講的實時數倉解決方案。
湖平臺與數倉平臺互通:一般是通過數據拷貝方式,將數據湖的原始數據或者批量計算結果數據復制一份到數倉當中。
以上的解決方案存在一些問題。首先,從建設和維護的角度來看,這種架構需要分別建設三個平臺,導致建設與維護成本增大;其次,數據共享需要進行一定的冗余存儲和數據拷貝,導致方案復雜讀變高。因此大家現在在逐漸嘗試將三個功能平臺融合到一起,形成融合數據湖。
在融合數據湖中,將通過流批一體的架構實現實時計算和批量計算的數據共享,解決數據冗余和數據搬遷的問題。通過湖內建倉的方式,在數據湖實現數倉的能力,構建 OLAP 能力,避免了數據的搬遷。這種融合數據湖的架構不僅可以提高數據處理的效率,還可以降低數據平臺的建設和維護成本,實現數據的共享和流通。
二、數據湖整體架構

上圖是一個基于開源技術的數據湖參考架構,從數據流上分為幾個環節:
數據源:數據流的起點,來源于業務系統,包括業務數據庫、消息流、日志等。
數據集成:數據湖架構中的重要環節。數據集成是業務系統與數據湖之間的橋梁,實現入湖和出湖的能力。通過批量和實時能力,可以實現 T+1 和 T+0 的集成能力。根據業務訴求和具體業務架構選擇不同的集成方式。
數據存儲:采用開源的 Lakehouse 技術進行數據存儲管理。底層的存儲引擎可以采用 Hadoop 的 HDFS 組件也可以采用對象存儲引擎。存儲格式采 Parquet 和 ORC 格式,這些格式提供了高效的壓縮和編碼方式,有助于提升數據的存儲和處理效率。基于 Lakehouse 技術,構建數倉能力,例如:ACID 能力、Update 能力、Schema 的演進,以及查詢加速的緩存和索引技術。
數據計算:采用支持流批一體的計算引擎,如 Spark 和 Flink,也可以基于 Hive 引擎進行批量計算。
湖內交互式分析:通過交互式查詢引擎 Presto、Trino 等,實現對湖內數據進行查詢分析,通過湖存儲的加速技術加持,查詢性能也可以實現秒級時延。
OLAP 層:在湖內進行數據加工處理完成后,需要更快速的查詢能力,通過數據集成同步到 OLAP 組件,根據具體業務需求,我們可以選擇不同的組件,如 CK 大寬表的快速查詢和 HBase KV 查詢等。當前部分 OLAP 組件也可以直接查詢湖內數據,避免了數據搬遷。
以上環節組合形成完整數據平臺架構,滿足多種業務場景的技術訴求。
三、數據集成

數據集成是業務系統與數據湖之間的橋梁,要面對多種不同的數據源。在流批一體的數據湖平臺中,數據集成主要分為批量集成和實時集成兩種方式。
批量集成:采用定時周期性的搬遷方式,將上游數據一次性搬遷到數據湖,或者將數據湖的數據搬遷到 OLAP 組件,例如 Sqoop、DataX 等開源組件,通過 JDBC 連接到源數據庫,將數據抽取出來并寫入數據湖中。這種方式適用于對時效性要求不高的場景,面臨的挑戰主要是大數據量的集成帶來的吞吐壓力。
實時集成:采用上游數據變更觸發的數據搬遷方式,通常采用實時增量技術采集上游數據。通常會利用開源技術如 Flink CDC(Change Data Capture)來實現數據庫的實時數據捕獲,將這些變化的數據采集到Kafka 等消息隊列中或者直接入湖實現實時入湖。采用增量讀取的方式將數據湖新變更數據同步到 OLAP 組件層,例如:采用 Flink 實時讀取 Hudi 的新增數據寫入 Doris。這種實時集成方式極大地提高了數據的時效性。
在實時集成中挑戰:
- 完整性保證:區別于批量集成,實時集成是實時采集每一條變更的新數據,在異常場景要保證數據不丟。
- 有序性保證:在流式計算中數據流有更新操作,數據是否保序會影響到計算結果的準確性,例如:上游數據庫對同一主鍵記錄更新多次,數據集成會采集到多條記錄,如果亂序那計算結果就會錯誤。
- 穩定性保證:日常的業務通常會有波峰波谷的出現,在實時集成通道要有能力保證流量增大也能保證任務運行的穩定性,可以通過加強監控的方式發現問題,通過彈性伸縮能力或者上線前壓測,保證任務的資源分配到位,或者通過限流措施犧牲波峰的時效性來保證穩定性。
隨著技術的發展,一些開源工具已經能夠實現流批一體的實時數據集成,這些工具不僅可以降低建設成本,還能夠減少技術復雜度。
四、Lakehouse 核心能力

在數據湖的存儲層,Lakehouse 技術的應用為數據處理和分析帶來了革命性的變革。Lakehouse 不僅繼承了數據湖的靈活性和可擴展性,還引入了數據倉庫的關鍵特性,如 ACID 事務、強一致性 Schema 管理、SQL 查詢等。以下是Lakehouse 技術應具備的關鍵能力:
- 增強的 DML SQL 能力:Lakehouse 新增了 update、upsert 和 merge into 等操作,數據湖也具備了更新能力。
- Schema Evolution:業務系統不斷演進過程中,會帶來表結構的變更,傳統大數據在該場景通常采用的是重新建表的方式。Lakehouse 支持 Alter table 能力,保證數據湖表可以更加靈活的適配業務的演進發展。
- ACID 事務和多版本支持:為了確保數據的一致性和完整性,Lakehouse 應提供 ACID 事務支持,并在異常情況下提供數據的回滾能力。多版本支持則允許訪問歷史數據,為數據的時間旅行提供可能。
- 并發控制:在多用戶環境中,Lakehouse 應能夠處理并發讀寫操作,確保數據的一致性和準確性。這包括對同一張表的并發寫入以及在讀寫操作中的嚴格一致性保證。
- 時間旅行:Lakehouse 應支持時間旅行功能,使用戶能夠訪問任意時間點的數據快照。這不僅為數據回溯和歷史分析提供了便利,還支持了流式的增量讀取能力。
- 文件存儲優化:為了支持高效的 OLAP 查詢,Lakehouse 應優化數據存儲格式,以便在特定場景下能夠快速檢索數據。
- 流批一體處理:Lakehouse 應同時支持流式和批量的數據讀寫,實現數據的一體化存儲和處理,滿足多樣化的數據處理需求。
- 索引構建:為了加速 OLAP 查詢,Lakehouse 提供了索引構建能力,以滿足業務對查詢時延的要求。
- 自動化管理:Lakehouse 具備自動化管理能力,包括數據的合并、歷史數據的清理、索引的構建等,以減輕用戶的維護負擔,并提高數據平臺的可靠性和穩定性。
五、Lakehouse 開放性設計

在現代數據湖的 Lakehouse 架構中,保持開放性的設計原則是至關重要的。這種開放性體現在幾個關鍵方面:
- 數據格式的開放性:Lakehouse 架構應確保其支持的數據格式具有開放性。這意味著使用標準化的、與開源社區廣泛兼容的數據格式,如 Parquet 和 ORC。這種開放的數據格式允許 Lakehouse 與各種數據處理工具和計算引擎無縫對接,無論是開源的還是商業的。例如,Apache Spark、Presto 和 Flink 等流行的開源計算引擎都能夠高效地讀取和寫入這些開放格式的數據。
- 計算引擎的開放性:Lakehouse 架構還應支持多種開源和商業計算引擎的接入。這種開放性確保了企業可以根據具體的業務需求和數據處理的場景,選擇最合適的計算引擎。無論是實時數據處理、批處理還是交互式查詢,Lakehouse 都能夠與各種計算引擎協同工作,提供高效的數據處理能力。
- 元數據與數據權限的集成:在 Lakehouse 中,元數據和數據權限管理是數據管理的基本能力要求。這種能力不僅確保了數據的組織和管理效率,還提供了精細的數據訪問控制,保障了數據的安全性和合規性。
- 多云部署能力:Lakehouse 架構應支持多云部署策略,包括在私有云和公共云環境中的部署。這種靈活性確保了企業可以根據自身的業務需求和資源狀況,選擇最合適的部署環境,同時保證了平臺的持續穩定演進。
六、流批一體

流批一體架構是現代數據處理平臺的核心特征之一,它實現了數據存儲、計算的深度融合。流批一體通常包含三種解釋:
- 數據存儲的流批一體:同一份數據既支持流式讀取也支持批量讀取。物理上數據存儲是一份。這種存儲模式確保了數據的一致性,并減少了數據冗余。
- 計算引擎的流批一體:指流式計算和批量計算可以由同一個計算引擎完成。例如,Apache Flink 和 Apache Spark 都支持流批一體的數據處理。這種方式可以降低架構復雜度,降低開發者的使用門檻。
- 數據處理代碼的流批一體化:指數據處理的代碼可以同時適用于流式和批量的方式執行。這樣可以降低開發成本,同時保證流批的任務代碼邏輯一致性。
在流批一體架構中,全鏈路支持批量和實時 ETL 計算。在數據倉庫的各分層中,企業可以采用批量計算來保證小時級和天級的處理能力,同時利用實時計算來保證分鐘級的數據處理能力。通過數據的統一處理,企業可以實現分鐘級的數據可見性,并確保數據的一致性,避免批處理和流處理數據結果的不一致性。
七、實時 OLAP

OLAP 能力是實現快速數據分析和決策支持的關鍵。為了滿足業務對快速響應和高效處理的需求,需要提供秒級的查詢時延和數百級別的并發查詢能力。隨著業務的發展具體的能力會有所變動,在面對業務量的大幅波動時,基于數據湖架構能夠迅速擴展計算能力,以應對高業務壓力的挑戰。
此外,基于容器化的部署能力,數據湖可以實現根據業務量的彈性伸縮。這種靈活性不僅提高了資源利用率,還確保了在高峰時段能夠提供足夠的計算資源,以滿足業務需求。在業務量減少時,資源可以相應地縮減,以優化成本效率。
八、湖內建倉

在數據湖架構中,湖內建倉的概念是將數據倉庫的能力集成到數據湖內部,以實現數據的高效管理和分析。這一過程涉及多層的存儲優化和數據組織。
首先,在數據文件層,我們實施存儲優化技術,如排序存儲和哈希分布,以提高數據文件的訪問效率。此外,我們還進行數據打散和內容組織優化,以進一步加速 OLAP 查詢。
接下來是索引層的構建。為了加速計算過程,采用與數據倉庫類似的技術,包括數據裁剪、下推和緩沖等,以優化計算性能。同時,提供統一的元數據服務,確保數據資產的統一視圖,并統一數據開發中的數據庫管理。
在數倉模型方面,繼續使用傳統的數倉分層存儲模型,如 ODS、DWS 和ADS,同時根據業務需求對數據進行主題域劃分,以實現更精細的數據管理。
在表模型方面,采用常見的快照表模型和拉鏈表模型進行數據存儲,并根據需要采用其他模型。通過這些方式,我們能夠在數據湖內部實現數倉的數據管理能力和數據處理能力。