數據處理必看:如何讓你的Pandas循環加快71803倍

雷鋒網 AI 開發者按,如果你使用 python 和 pandas 進行數據分析,那么不久你就會第一次使用循環了。然而,即使是對小型數據集,使用標準循環也很費時,你很快就會意識到大型數據幀可能需要很長的時間。當我第一次等了半個多小時來執行代碼時,我找到了接下來想與你共享的替代方案。
標準循環
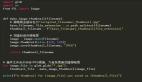
數據幀是具有行和列的 pandas 對象。如果使用循環,則將遍歷整個對象。python 不能用任何內置函數,而且速度非常慢。在我們的示例中,我們得到了一個具有 65 列和 1140 行的數據幀,它包含 2016-2019 賽季的足球比賽結果。我們要創建一個新的列來指示某個特定的隊是否打過平局。我們可以這樣開始:
- leaguedf['Draws'] = 99999
- for row in range(0, len(leaguedf)):
- if ((leaguedf['HomeTeam'].iloc[row] == TEAM) & (leaguedf['FTR'].iloc[row] == 'D')) | \
- ((leaguedf['AwayTeam'].iloc[row] == TEAM) & (leaguedf['FTR'].iloc[row] == 'D')):
- leaguedf['Draws'].iloc[row] = 'Draw'
- elif ((leaguedf['HomeTeam'].iloc[row] == TEAM) & (leaguedf['FTR'].iloc[row] != 'D')) | \
- ((leaguedf['AwayTeam'].iloc[row] == TEAM) & (leaguedf['FTR'].iloc[row] != 'D')):
- leaguedf['Draws'].iloc[row] = 'No_Draw'
- else:
- leaguedf['Draws'].iloc[row] = 'No_Game'
- def soc_loop(leaguedf,TEAM,):

因為我們的數據框架中包含了英超的每一場比賽,所以我們必須檢查我們感興趣的球隊(阿森納)是否參加過比賽,是否適用,他們是主隊還是客隊。如你所見,這個循環非常慢,需要 207 秒才能執行。讓我們看看如何提高效率。
pandas 內置函數:iterrow()——快 321 倍
在第一個示例中,我們循環訪問了整個數據幀。iterrows()為每行返回一個序列,因此它以一對索引的形式在數據幀上迭代,而感興趣的列以序列的形式迭代。這使得它比標準循環更快:
- def soc_iter(TEAM,home,away,ftr):
- #team, row['HomeTeam'], row['AwayTeam'], row['FTR']
- if [((home == TEAM) & (ftr == 'D')) | ((away == TEAM) & (ftr == 'D'))]:
- result = 'Draw'
- elif [((home == TEAM) & (ftr != 'D')) | ((away == TEAM) & (ftr != 'D'))]:
- result = 'No_Draw'
- else:
- result = 'No_Game'
- return result

代碼運行需要 68 毫秒,比標準循環快 321 倍。但是,許多人建議不要使用它,因為仍然有更快的方法,并且 iterrows() 不保留跨行的數據類型。這意味著,如果在數據幀上使用 iterrow(),則可以更改數據類型,這會導致很多問題。要保留數據類型,還可以使用 itertuples()。我們不會在這里詳細討論,因為我們要關注效率。你可以在這里找到官方文件:

https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.itertuples.html?source=post_page-----805030df4f06----------------------
apply()方法——快 811 倍
apply 本身并不快,但與數據幀結合使用時具有優勢。這取決于應用表達式的內容。如果可以在 Cython 空間中執行,則速度會更快(在這里就是這種情況)。
我們可以將 apply 與 Lambda 函數一起使用。我們要做的就是指定軸。在這種情況下,我們必須使用 axis=1,因為我們要執行一個列操作:

此代碼甚至比以前的方法更快,只需要 27 毫秒就能完成。
pandas 矢量化——快 9280 倍
現在我們可以討論一個新話題了。我們利用矢量化的優點來創建真正快速的代碼。重點是避免像前面的例子 [1] 中那樣的 Python 級循環,并使用優化的 C 代碼,這個代碼使用內存的效率更高。我們只需要稍微修改函數:
- df['Draws'] = 'No_Game'
- df.loc[((home == TEAM) & (ftr == 'D')) | ((away == TEAM) & (ftr == 'D')), 'Draws'] = 'Draw'
- df.loc[((home == TEAM) & (ftr != 'D')) | ((away == TEAM) & (ftr != 'D')), 'Draws'] = 'No_Draw'
- def soc_iter(TEAM,home,away,ftr):
現在我們可以用 pandas series 作為輸入創建新列:

在這種情況下,我們甚至不需要循環。我們要做的就是調整函數的內容。現在我們可以直接將 pandas series 傳遞給我們的函數,這會導致巨大的速度增益。
Numpy 矢量化——速度快 71.803 倍
在前面的示例中,我們將 pandas series 傳遞給了函數。通過添加.values,我們收到一個 Numpy 數組:

Numpy 數組非常快,我們的代碼運行時間為 0305 毫秒,比開始使用的標準循環快 71803 倍。
結論
如果您使用 python、pandas 和 Numpy 進行數據分析,那么代碼總會有一些改進空間。我們比較了五種不同的方法,在計算的基礎上增加了一個新的列到我們的數據框架中。我們注意到在速度方面存在巨大差異:

如果你從這篇文章中選擇兩條規則,我會很高興:
- 如果確定需要使用循環,則應始終選擇 apply 方法
- 否則,矢量化總是更好的,因為它更快
本文轉自雷鋒網,如需轉載請至雷鋒網官網申請授權。