再見for循環!pandas提速315倍~

for是所有編程語言的基礎語法,初學者為了快速實現功能,依懶性較強。但如果從運算時間性能上考慮可能不是特別好的選擇。
本次東哥介紹幾個常見的提速方法,一個比一個快,了解pandas本質,才能知道如何提速。
下面是一個例子,數據獲取方式見文末。
- >>> import pandas as pd
- # 導入數據集
- >>> df = pd.read_csv('demand_profile.csv')
- >>> df.head()
- date_time energy_kwh
- 0 1/1/13 0:00 0.586
- 1 1/1/13 1:00 0.580
- 2 1/1/13 2:00 0.572
- 3 1/1/13 3:00 0.596
- 4 1/1/13 4:00 0.592
基于上面的數據,我們現在要增加一個新的特征,但這個新的特征是基于一些時間條件生成的,根據時長(小時)而變化,如下:
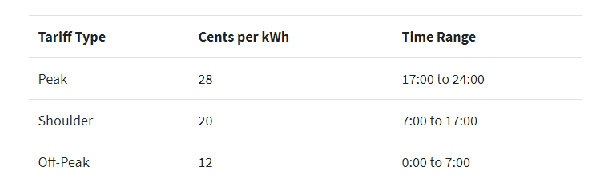
因此,如果你不知道如何提速,那正常第一想法可能就是用apply方法寫一個函數,函數里面寫好時間條件的邏輯代碼。
- def apply_tariff(kwh, hour):
- """計算每個小時的電費"""
- if 0 <= hour < 7:
- rate = 12
- elif 7 <= hour < 17:
- rate = 20
- elif 17 <= hour < 24:
- rate = 28
- else:
- raise ValueError(f'Invalid hour: {hour}')
- return rate * kwh
然后使用for循環來遍歷df,根據apply函數邏輯添加新的特征,如下:
- >>> # 不贊同這種操作
- >>> @timeit(repeat=3, number=100)
- ... def apply_tariff_loop(df):
- ... """用for循環計算enery cost,并添加到列表"""
- ... energy_cost_list = []
- ... for i in range(len(df)):
- ... # 獲取用電量和時間(小時)
- ... energy_used = df.iloc[i]['energy_kwh']
- ... hour = df.iloc[i]['date_time'].hour
- ... energy_cost = apply_tariff(energy_used, hour)
- ... energy_cost_list.append(energy_cost)
- ... df['cost_cents'] = energy_cost_list
- ...
- >>> apply_tariff_loop(df)
- Best of 3 trials with 100 function calls per trial:
- Function `apply_tariff_loop` ran in average of 3.152 seconds.
對于那些寫Pythonic風格的人來說,這個設計看起來很自然。然而,這個循環將會嚴重影響效率。原因有幾個:
首先,它需要初始化一個將記錄輸出的列表。
其次,它使用不透明對象范圍(0,len(df))循環,然后再應用apply_tariff()之后,它必須將結果附加到用于創建新DataFrame列的列表中。另外,還使用df.iloc [i]['date_time']執行所謂的鏈式索引,這通常會導致意外的結果。
這種方法的最大問題是計算的時間成本。對于8760行數據,此循環花費了3秒鐘。
接下來,一起看下優化的提速方案。
使用 iterrows循環
第一種可以通過pandas引入iterrows方法讓效率更高。這些都是一次產生一行的生成器方法,類似scrapy中使用的yield用法。
.itertuples為每一行產生一個namedtuple,并且行的索引值作為元組的第一個元素。nametuple是Python的collections模塊中的一種數據結構,其行為類似于Python元組,但具有可通過屬性查找訪問的字段。
.iterrows為DataFrame中的每一行產生(index,series)這樣的元組。
在這個例子中使用.iterrows,我們看看這使用iterrows后效果如何。
- >>> @timeit(repeat=3, number=100)
- ... def apply_tariff_iterrows(df):
- ... energy_cost_list = []
- ... for index, row in df.iterrows():
- ... # 獲取用電量和時間(小時)
- ... energy_used = row['energy_kwh']
- ... hour = row['date_time'].hour
- ... # 添加cost列表
- ... energy_cost = apply_tariff(energy_used, hour)
- ... energy_cost_list.append(energy_cost)
- ... df['cost_cents'] = energy_cost_list
- ...
- >>> apply_tariff_iterrows(df)
- Best of 3 trials with 100 function calls per trial:
- Function `apply_tariff_iterrows` ran in average of 0.713 seconds.
這樣的語法更明確,并且行值引用中的混亂更少,因此它更具可讀性。
時間成本方面:快了近5倍!
但是,還有更多的改進空間,理想情況是可以用pandas內置更快的方法完成。
pandas的apply方法
我們可以使用.apply方法而不是.iterrows進一步改進此操作。pandas的.apply方法接受函數callables并沿DataFrame的軸(所有行或所有列)應用。下面代碼中,lambda函數將兩列數據傳遞給apply_tariff():
- >>> @timeit(repeat=3, number=100)
- ... def apply_tariff_withapply(df):
- ... df['cost_cents'] = df.apply(
- ... lambda row: apply_tariff(
- ... kwh=row['energy_kwh'],
- ... hour=row['date_time'].hour),
- ... axis=1)
- ...
- >>> apply_tariff_withapply(df)
- Best of 3 trials with 100 function calls per trial:
- Function `apply_tariff_withapply` ran in average of 0.272 seconds.
apply的語法優點很明顯,行數少,代碼可讀性高。在這種情況下,所花費的時間大約是iterrows方法的一半。
但是,這還不是“非常快”。一個原因是apply()將在內部嘗試循環遍歷Cython迭代器。但是在這種情況下,傳遞的lambda不是可以在Cython中處理的東西,因此它在Python中調用并不是那么快。
如果我們使用apply()方法獲取10年的小時數據,那么將需要大約15分鐘的處理時間。如果這個計算只是大規模計算的一小部分,那么真的應該提速了。這也就是矢量化操作派上用場的地方。
矢量化操作:使用.isin選擇數據
什么是矢量化操作?
如果你不基于一些條件,而是可以在一行代碼中將所有電力消耗數據應用于該價格:df ['energy_kwh'] * 28,類似這種。那么這個特定的操作就是矢量化操作的一個例子,它是在pandas中執行的最快方法。
但是如何將條件計算應用為pandas中的矢量化運算?
一個技巧是:根據你的條件,選擇和分組DataFrame,然后對每個選定的組應用矢量化操作。
在下面代碼中,我們將看到如何使用pandas的.isin()方法選擇行,然后在矢量化操作中實現新特征的添加。在執行此操作之前,如果將date_time列設置為DataFrame的索引,會更方便:
- # 將date_time列設置為DataFrame的索引
- df.set_index('date_time', inplace=True)
- @timeit(repeat=3, number=100)
- def apply_tariff_isin(df):
- # 定義小時范圍Boolean數組
- peak_hours = df.index.hour.isin(range(17, 24))
- shoulder_hours = df.index.hour.isin(range(7, 17))
- off_peak_hours = df.index.hour.isin(range(0, 7))
- # 使用上面apply_traffic函數中的定義
- df.loc[peak_hours, 'cost_cents'] = df.loc[peak_hours, 'energy_kwh'] * 28
- df.loc[shoulder_hours,'cost_cents'] = df.loc[shoulder_hours, 'energy_kwh'] * 20
- df.loc[off_peak_hours,'cost_cents'] = df.loc[off_peak_hours, 'energy_kwh'] * 12
我們來看一下結果如何。
- >>> apply_tariff_isin(df)
- Best of 3 trials with 100 function calls per trial:
- Function `apply_tariff_isin` ran in average of 0.010 seconds.
提示,上面.isin()方法返回的是一個布爾值數組,如下:
- [False, False, False, ..., True, True, True]
布爾值標識了DataFrame索引datetimes是否落在了指定的小時范圍內。然后把這些布爾數組傳遞給DataFrame的.loc,將獲得一個與這些小時匹配的DataFrame切片。然后再將切片乘以適當的費率,這就是一種快速的矢量化操作了。
上面的方法完全取代了我們最開始自定義的函數apply_tariff(),代碼大大減少,同時速度起飛。
運行時間比Pythonic的for循環快315倍,比iterrows快71倍,比apply快27倍!
還能更快?
太刺激了,我們繼續加速。
在上面apply_tariff_isin中,我們通過調用df.loc和df.index.hour.isin三次來進行一些手動調整。如果我們有更精細的時間范圍,你可能會說這個解決方案是不可擴展的。但在這種情況下,我們可以使用pandas的pd.cut()函數來自動完成切割:
- @timeit(repeat=3, number=100)
- def apply_tariff_cut(df):
- cents_per_kwh = pd.cut(x=df.index.hour,
- bins=[0, 7, 17, 24],
- include_lowest=True,
- labels=[12, 20, 28]).astype(int)
- df['cost_cents'] = cents_per_kwh * df['energy_kwh']
上面代碼pd.cut()會根據bin列表應用分組。
其中include_lowest參數表示第一個間隔是否應該是包含左邊的。
這是一種完全矢量化的方法,它在時間方面是最快的:
- >>> apply_tariff_cut(df)
- Best of 3 trials with 100 function calls per trial:
- Function `apply_tariff_cut` ran in average of 0.003 seconds.
到目前為止,使用pandas處理的時間上基本快達到極限了!只需要花費不到一秒的時間即可處理完整的10年的小時數據集。
但是,最后一個其它選擇,就是使用 NumPy,還可以更快!
使用Numpy繼續加速
使用pandas時不應忘記的一點是Pandas的Series和DataFrames是在NumPy庫之上設計的。并且,pandas可以與NumPy陣列和操作無縫銜接。
下面我們使用NumPy的 digitize()函數更進一步。它類似于上面pandas的cut(),因為數據將被分箱,但這次它將由一個索引數組表示,這些索引表示每小時所屬的bin。然后將這些索引應用于價格數組:
- @timeit(repeat=3, number=100)
- def apply_tariff_digitize(df):
- prices = np.array([12, 20, 28])
- bins = np.digitize(df.index.hour.values, bins=[7, 17, 24])
- df['cost_cents'] = prices[bins] * df['energy_kwh'].values
與cut函數一樣,這種語法非常簡潔易讀。
- >>> apply_tariff_digitize(df)
- Best of 3 trials with 100 function calls per trial:
- Function `apply_tariff_digitize` ran in average of 0.002 seconds.
0.002秒! 雖然仍有性能提升,但已經很邊緣化了。