如何提升代碼搜索效果?GitHub團隊打造代碼搜索領域的GLUE數據集
想提升代碼搜索效果?首先你得知道怎么才算提升。GitHub 團隊創建 CodeSearchNet 語料庫,旨在為代碼搜索領域提供基準數據集,提升代碼搜索結果的質量。
搜索代碼進行重用、調用,或者借此查看別人處理問題的方式,是軟件開發者日常工作中最常見的任務之一。然而,代碼搜索引擎的效果通常不太好,和常規的 web 搜索引擎不同,它無法充分理解你的需求。GitHub 團隊嘗試使用現代機器學習技術改善代碼搜索結果,但很快意識到一個問題:他們無法衡量改善效果。自然語言處理領域有 GLUE 基準,而代碼搜索評估領域并沒有適合的標準數據集。
因此 GitHub 與 Weights & Biases 公司展開合作,并于昨日推出 CodeSearchNet Challenge 評估環境和排行榜。與此同時,GitHub 還發布了一個大型數據集,以幫助數據科學家構建適合該任務的模型,并提供了多個代表當前最優水平的基線模型。該排行榜使用一個 query 標注數據集來評估代碼搜索工具的質量。
- 論文地址:https://arxiv.org/abs/1909.09436
- 語料庫及基線模型地址:https://github.com/github/CodeSearchNet
- 挑戰賽地址:https://app.wandb.ai/github/codesearchnet/benchmark
CodeSearchNet 語料庫
使用專家標注創建足以訓練高容量模型的大型數據集成本高昂,不切實際,因此 GitHub 創建了一個質量較低的代理數據集。GitHub 遵循文獻 [5, 6, 9, 11] 中的做法,將開源軟件中的函數與其對應文檔中的自然語言進行匹配。但是,這樣做需要執行大量預處理步驟和啟發式方法。
通過對常見錯誤案例進行深入分析,GitHub 團隊總結出一些通用法則和決策。
CodeSearchNet 語料庫收集過程
GitHub 團隊從開源 non-fork GitHub repo 中收集語料,使用 libraries.io 確認所有項目均被至少一個其他項目使用,并按照「流行度」(popularity)對其進行排序(流行度根據 star 和 fork 數而定)。然后,刪除沒有 license 或者 license 未明確允許重新分發的項目。之后,GitHub 團隊使用其通用解析器 TreeSitter 對所有 Go、Java、JavaScript、Python、PHP 和 Ruby 函數(或方法)執行分詞操作,并使用啟發式正則表達式對函數對應的文檔文本進行分詞處理。
篩選
為了給 CodeSearchNet Challenge 生成訓練數據,GitHub 團隊首先考慮了語料庫中具備相關文檔的函數。這就得到了一組 (c_i , d_i) 對,其中 c_i 是函數,d_i 是對應的文檔。為了使數據更加適合代碼搜索任務,GitHub 團隊執行了一系列預處理步驟:
文檔 d_i 被截斷,僅保留第一個完整段落,以使文檔長度匹配搜索 query,并刪除對函數參數和返回值的深入討論。
刪除 d_i 短于三個 token 的對,因為此類注釋無法提供有效信息。
刪除 c_i 實現少于三行的對,因為它們通常包含未實現的方法、getters、setters 等。
刪除名稱中包含子字符串「test」的函數。類似地,刪除構造函數和標準擴展方法,如 Python 中的 __str__、Java 中的 toString。
識別數據集中的(近似)重復函數,僅保留其中一個副本,從而刪除數據集中的重復項。這就消除了出現多個版本自生成代碼和復制粘貼的情況。
篩選后的語料庫和數據抽取代碼詳見:https://github.com/github/CodeSearchNet
數據集詳情
該數據集包含 200 萬函數-文檔對、約 400 萬不具備對應文檔的函數(見下表 1)。GitHub 團隊將該數據集按照 80-10-10 的比例劃分為訓練集/驗證集/測試集,建議用戶按照該比例使用此數據集。
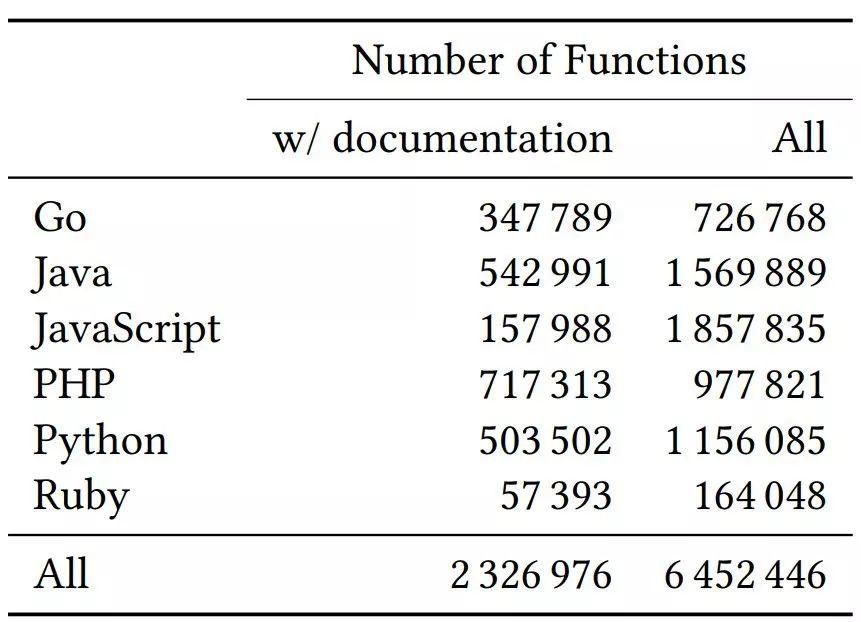
表 1:數據集詳情
局限性
該數據集噪聲很大。首先,文檔與 query 存在本質區別,它們使用的是不同的語言形式。文檔通常是代碼作者在寫代碼的同時寫成的,更傾向于使用同樣的詞匯,這與搜索 query 存在差異。其次,盡管 GitHub 團隊在創建數據集的過程中執行了數據清洗,但他們無法得知每個文檔 d_i 描述對應代碼段 c_i 的精確程度。最后,一些文檔是用非英語文本寫成的,而 CodeSearchNet Challenge 評估數據集主要關注的是英文 query。
CodeSearchNet 基線模型
基于 GitHub 之前在語義代碼搜索領域的努力,該團隊發布了一組基線模型,這些模型利用現代技術學習序列(包括 BERT 類的自注意力模型),幫助數據科學家開啟代碼搜索。
和之前的工作一樣,GitHub 團隊使用代碼和 query 的聯合嵌入來實現神經搜索系統。該架構對每個輸入(自然或編程)語言使用一個編碼器,并訓練它們使得輸入映射至一個聯合向量空間。其訓練目標是將代碼及其對應語言映射至鄰近的向量,這樣我們就可以嵌入 query 實現搜索,然后返回嵌入空間中「鄰近」的代碼段集合。
考慮 query 和代碼之間更多交互的較復雜模型當然性能更好,但是為每個 query 或代碼段生成單個向量可以實現更高效的索引和搜索。
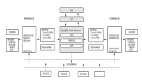
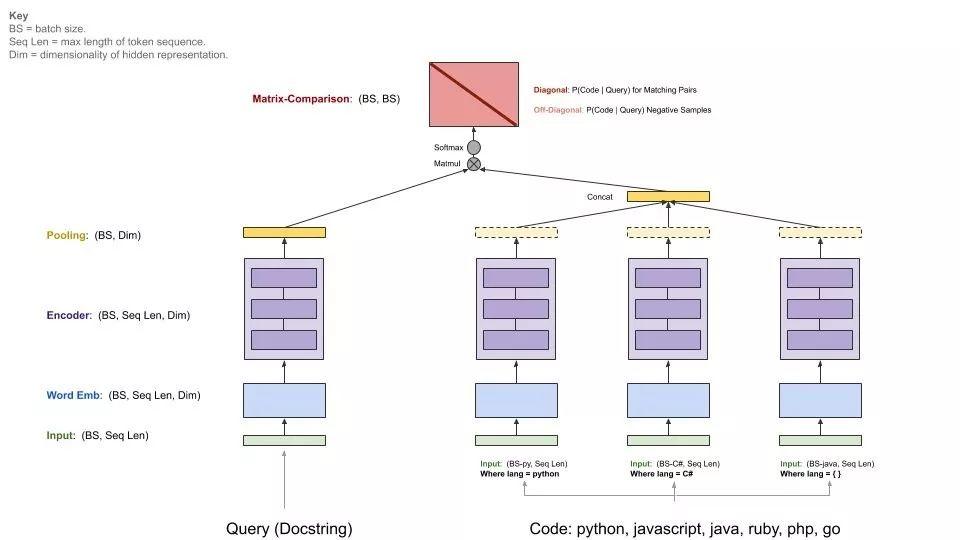
為了學習這些嵌入函數,GitHub 團隊在架構中加入了標準序列編碼器模型,如圖 3 所示。首先,根據輸入序列的語義對其執行預處理:將代碼 token 中的標識符分割為子 token(如變量 camelCase 變成了兩個子 token:camel 和 case),使用字節對編碼(byte-pair encoding,BPE)分割自然語言 token。
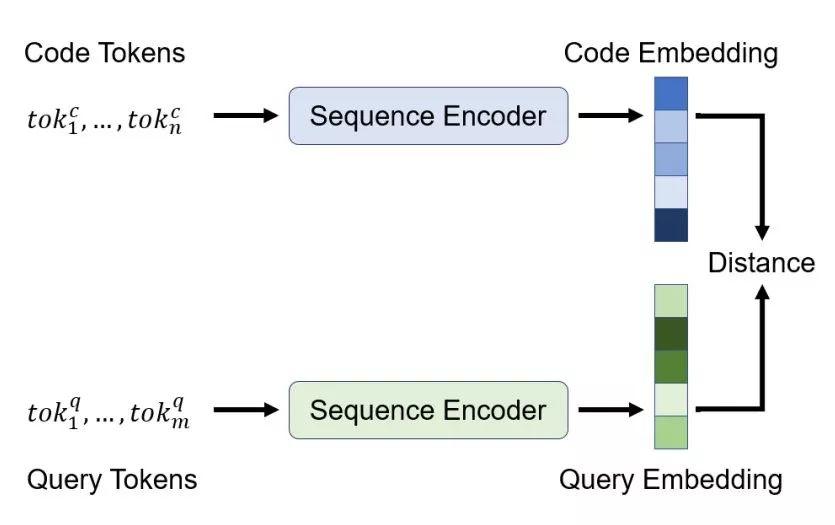
圖 3:模型架構概覽
然后使用以下架構之一處理 token 序列,以獲得(語境化的)token 嵌入。
- 神經詞袋模型:每個(子)token 都被轉換為可學習嵌入(向量表示)。
- 雙向 RNN 模型:利用 GRU 單元總結輸入序列。
- 一維卷積神經網絡:用于處理輸入 token 序列。
- 自注意力模型:其多頭注意力用于計算序列中每個 token 的表示。
之后,使用池化函數將這些 token 嵌入組合為一個序列嵌入,GitHub 團隊已經實現了 mean/max-pooling 和類注意力的加權和機制。
下圖展示了基線模型的通用架構:
CodeSearchNet 挑戰賽
為了評估代碼搜索模型,GitHub 團隊收集了一組代碼搜索 query,并讓程序員標注 query 與可能結果的關聯程度。他們首先從必應中收集了一些常見搜索 query,結合 StaQC 中的 query 一共獲得 99 個與代碼概念相關的 query(GitHub 團隊刪除了 API 文檔查詢方面的問題)。
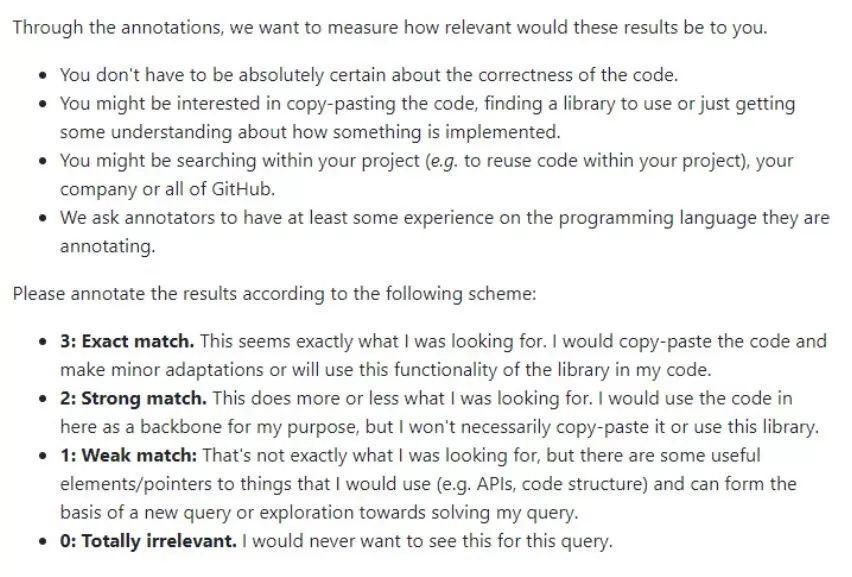
圖 1:標注者指導說明
之后,GitHub 團隊使用標準 Elasticsearch 和基線模型,從 CodeSearchNet 語料庫中為每個 query 獲得 10 個可能的結果。最后,GitHub 團隊請程序員、數據科學家和機器學習研究者按照 [0, 3] 的標準標注每個結果與 query 的關聯程度(0 表示「完全不相關」,3 表示「完全匹配」)。
未來,GitHub 團隊想在該評估數據集中納入更多語言、query 和標注。接下來幾個月,他們將持續添加新的數據,為下一個版本的 CodeSearchNet Challenge 制作擴展版數據集。