如何提升 Java 代碼的可讀性
我們經常感嘆“面試造火箭,進廠擰螺絲”,日常開發中大部分工作都是寫簡單的業務代碼。實際上,寫好業務代碼也是有技術難度的,并不是所有人都能寫出可讀性較高的業務代碼。
可讀性高的代碼能夠降低后續的維護成本,提升后續開發的效率。
接下來和大家分享下我的經驗,這些方法能夠在一定程度上提升代碼的可讀性。
命名
Martin Fowler曾經在一篇文章中曾經引用過Phil Karlton的話:There are only two hard things in Computer Science: cache invalidation and naming things. “
在 CS 領域中,有兩件事是非常難的,一個是緩存失效,一個是命名。”
一致性
大項目中都是分工合作,不同領域由不同團隊負責,同一領域也可能由多個人一起開發,因此即使對同一個事物命名,不同人也有不同的理解,因此對于關鍵業務名稱的命名需要統一,使整個鏈路保持一致性。
這個責任最好由項目PM擔起,在寫技術方案的時候,統一關鍵業務事物的命名。
有意義且簡短
首先需要保證命名有意義,只要命名合理,不要擔心方法名稱太長,但方法名稱過長常常又意味著該方法干的事太多了,則需要思考是否可以拆分方法,這也反映了"職責單一"設計原則。
保證命名有意義的前提之下,盡量保證命名的簡短,刪除一些不影響表達的單詞,或者采用縮寫。舉幾個例子:
ActivityRuleRepository.findActivityRuleById() 可以簡寫成ActivityRuleRepository.findById(),因為上下文已經說明白了這個一個查詢活動規則的Repository接口。
void updateRuleForRevision(String ruleString) 簡寫成void updateRule4Revision(String ruleStr)
ActivityRule convert2ActivityRule(String ruleStr) 借鑒toString的簡寫方式,簡寫成ActivityRule toActivityRule(String ruleStr)
遵循命名規范
Java的命名規范參考《阿里巴巴開發規約》中的命名規約,下面摘抄幾條命名規范復習下:
所有編程相關的命名均不能以下劃線或美元符號開始,也不能以下劃線或美元符號結束。
所有編程相關的命名嚴禁使用拼音與英文混合的方式,更不允許直接使用中文的方式。
代碼和注釋中都要避免使用(任何人類語言的)涉及性別、種族、地域、特定人群等的歧視性詞語。
類名使用UpperCamelCase風格,以下情形例外:DO / BO / DTO / VO / AO / UID等。
方法名、參數名、成員變量、局部變量都統一使用lowerCamelCase風格。
常量命名應該全部大寫,單詞間用下劃線隔開,力求語義表達完整清楚,不要嫌名字長。
POJO類中的任何布爾類型的變量,都不要加is前綴,否則部分框架解析會引起序列化錯誤。
區分作用范圍
作用范圍可以分為應用、包、類、方法、代碼塊,在大的作用域范圍應該盡量使用完整有意義的命名,但是在方法和代碼塊內可以考慮使用短名稱,因為變量作用范圍有局限性,上下文一眼可知,變量的含義也就無需過多說明。
如果小作用范圍依然使用長命名會導致很容易超過列寬,即使折行也難以閱讀。如下所示,方法內采用簡短的命名方式。
- void updateRule4Revision(String ruleStr) { ActivityRule rule = toActivityRule(ruleStr); int oldVersion = rule.getVersion(); rule.setVersion(++oldVersion); activityRuleRepository.save(rule);}
體現副作用
如果方法實現會產生副作用,該副作用需要體現在方法名稱,舉個可能不太恰當的例子,下面的方法在驗證規則的同時去激活規則的狀態,如果規則已經是激活狀態則狀態沒有變化,如果規則不是激活狀態則狀態被改變。
一般我們應該保持方法的單一職責,但是有些特殊情況導致了妥協,那么一定要在方法命名上面體現。
- boolean verifyRuleAndActivateStatus(Rule rule) { // verify rule ...... rule.activateStatus() ......}
閱讀優秀的開源代碼
英語不是我們的母語,這導致我們命名更加困難,我們可以通過閱讀優秀的開源代碼提升詞匯量,熟悉英語母語開發者的命名思維習慣。
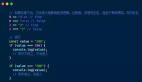
也并不是所有的開源項目的代碼可讀性都很高,有些為了追求極致的性能損失了部分可讀性,如果不知道學習哪個開源項目,那就學習spring-boot項目,下面截圖是spring-boot項目中的代碼,命名方式值得學習。
使用Optional
優雅判空
NullPointerException是Java程序員無法言語的痛,為了避免空指針異常,我們通常需要做非常多的防御性編程,if判空是最簡單的方式,但是充斥大量著if判空的代碼會淹沒核心代碼邏輯,導致可讀性差。
下面舉一個例子:
Optional優化前:
- public Long parseUmpActivityId(PlayApplyContext applyContext) { if (applyContext == null || applyContext.getPlayDetailDO() == null || StringUtil.isBlank(applyContext.getPlayDetailDO().getDetail())) { return null; } Map<String, String> playDetailMap = toPlayDetailMap(applyContext.getPlayDetailDO().getDetail()); if (playDetailMap == null) { return null; } String umpActivityIdStr = playDetailMap.get(Constant.UMP_ACTIVITY_ID); if (StringUtils.isBlank(umpActivityIdStr)) { return null; } return Long.parseLong(umpActivityIdStr);
Optional優化后:
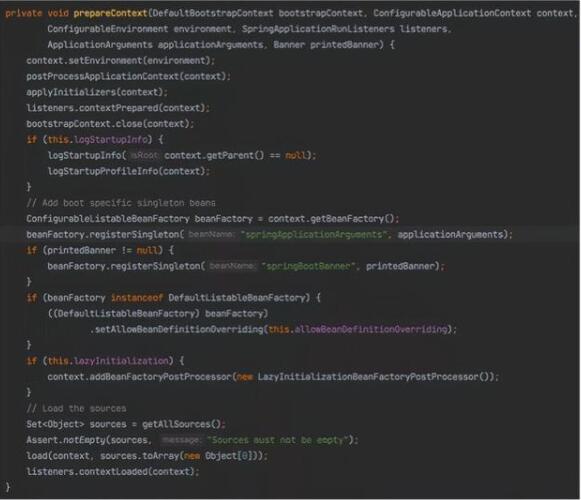
- public Long parseUmpActivityId(PlayApplyContext applyContext) { return Optional.ofNullable(applyContext) .map(PlayApplyContext::getPlayDetailDO) .map(PlayDetailDO::getDetail) .map(this::toPlayDetailMap) .map(m -> m.get(Constant.UMP_ACTIVITY_ID)) .filter(StringUtils::isNotBlank) .map(Long::parseLong) .orElse(null);}
分支判斷
Optional的orElse具有分支判斷的能力,可以在一些情況下代替if,提升代碼的可讀性,如下場景所示,經過三目運算符的優化依然可讀性不強,Optional優化后才具有較高可讀性。
優化前
- ...... Result<Long> result = apply(juItem); if (result == null || !result.isSuccess()) { if (result != null && result.getMsg() != null) { return Result.buildErrorResult(result.getMsg()); } return Result.buildErrorResult("創建失敗"); } ......
三目運算符優化后:
- ...... Result<Long> result = apply(juItem); if (result == null || !result.isSuccess()) { return Result.buildErrorResult( result != null && result.getMsg() != null ? result.getMsg() : "創建失敗"); } ......
Optional優化后:
- ...... Result<Long> result = apply(juItem); if (result == null || !result.isSuccess()) { return Result.buildErrorResult( Optional.ofNullable(result).map(Result::getMsg).orElse("創建失敗")); } ......
陷阱
在使用Optional的orElse時候可能會誤入陷阱,舉一個具體的例子,如下所示的代碼存在問題嗎?
這段代碼的作用是,當傳入參數中activity不為空則取傳入的activity,否則通過接口根據活動ID查詢,避免了無謂的查詢。
- Result applyActivity(Params params) { Activity activity = Optional.ofNullable(params) .map(Params::getActivity) .orElse(activityManager.findById(params.getActivityId())); ......}
以上代碼存在兩個問題,第一,params.getActivityId()可能出現空指針異常,第二,activityManager.findById一定會被調用,無法達到預期的效果。
而這兩個問題的根本原因都是因為orElse方法傳入的是語句執行之后的結果。
所以在orElse方法中最好不要傳入執行語句,而應該是默認值。
上面應該這種情況正確應該使用orElseGet,orElseGet傳入的是函數。
正確換行
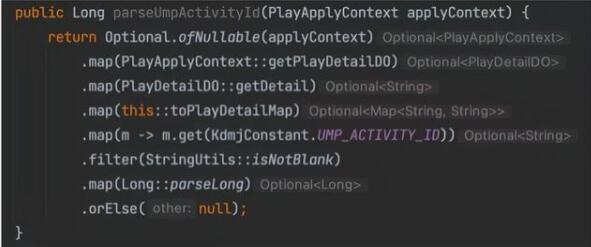
Optional方式編程很大程度提升了代碼的可讀性,寫代碼如行云流水一般,為了更好的閱讀,需要采用正確的換行方式,最好是一行一條Optional語句,如下圖所示,這樣換行的好處就是,一行做一件事情,閱讀流暢。
而且最重要的是IDEA在每條語句后面提示了返回結果的類型,這個提示不僅僅對閱讀有幫助,對編寫代碼也有很大幫助。這個原則同樣適用于Lambda表達式的編寫。
當然,對于非常簡單鏈式語句可以打破以上原則,比如context.setActivityId(Optional.ofNullable(activityId).orElse(0L));
使用Lambda
關于Lambda表達式編程的好處和用法想必大部分人都清楚,正確使用Lambda表達式可以很大程度提升代碼的可讀性,但是不正確使用Lambda表達式會給可讀性帶來更大的災難。
拒絕匿名函數
如下函數的功能是根據活動信息獲取活動中的所有報名記錄,采用了普通的for循環編寫,嵌套比較深,代碼含義不是很明確,有優化的空間,接下來采用Lambda表達式進行優化。
- private List<Record> obtainRecords(List<Campaign> campaignList) { List<Record> recordList = Lists.newArrayList(); for (Campaign campaign : campaignList) { if (campaign.getStartTime() != null && campaign.getStartTime().getTime() < System.currentTimeMillis() && campaign.getStatus() > 0) { Params params = new Params(); params.setCampaignId(campaign.getId()); params.setStartTime(campaign.getStartTime()); params.setStatus(campaign.getStatus()); List<Record> originRecordList = campaignRecordFacade.query(params); for (Record record : originRecordList) { if ((record.getStatus() <= INIT && PLAY_TYPE.equals(record.getType())) || record.getStatus() == AUDIT_PASS) { recordList.add(record); } } } } return recordList;}
采用Lambda表達式重新編寫后如下所示,一定程度上提升了代碼的可讀性,是否還具有提升空間呢。
其中匿名函數占據了大部分代碼邏輯,導致主流程不清晰,在使用Lambda表達式的時候應該盡量不要使用匿名函數。
- private List<Record> obtainRecords(List<Campaign> campaignList) { return campaignList.stream() .filter(campaign -> campaign.getStartTime() != null && campaign.getStartTime().getTime() < System.currentTimeMillis() && campaign.getStatus() > 0) .map(campaign -> { Params params = new Params(); params.setCampaignId(campaign.getId()); params.setStartTime(campaign.getStartTime()); params.setStatus(campaign.getStatus()); return campaignRecordFacade.query(params); }) .flatMap(Collection::stream) .filter(record -> (record.getStatus() <= INIT && PLAY_TYPE.equals(record.getType())) || record.getStatus() == AUDIT_PASS) .collect(Collectors.toList());}
去除匿名函數優化后如下所示,主流程非常清晰,沒有閱讀障礙,函數名解釋了所做的具體事情,通過閱讀函數名而不是具體的代碼去了解這塊做了什么事情,具體閱讀某個函數時,只需要保證代碼邏輯符合函數名表達的含義。
- private List<Record> obtainRecords(List<Campaign> campaignList) { return campaignList.stream() .filter(this::isValidAndAlreadyStarted) .map(this::queryRecords) .flatMap(Collection::stream) .filter(this::isInitializedPlayOrAuditPass) .collect(Collectors.toList());}private boolean isValidAndAlreadyStarted(Campaign campaign) { return campaign.getStartTime() != null && campaign.getStartTime().getTime() < System.currentTimeMillis() && campaign.getStatus() > 0;}private List<Record> queryRecords(Campaign campaign) { Params params = new Params(); params.setCampaignId(campaign.getId()); params.setStartTime(campaign.getStartTime()); params.setStatus(campaign.getStatus()); return campaignRecordFacade.query(params);}private boolean isInitializedPlayOrAuditPass(Record record) { return (record.getStatus() <= INIT && PLAY_TYPE.equals(record.getType())) || record.getStatus() == AUDIT_PASS;}
結合Optional使用
Lambda表達式結合Optional使用可以更加簡潔,如下所示查詢報名記錄后獲取報名記錄的ID,不使用Optional的時候需要判空等其他操作,Optional讓語句更加連貫。
這里需要注意一點,Collections.emptyList()返回的是一個不可變的內部類,不允許添加元素,如果返回的結果需要添加元素,需要使用Lists.newArrayList()。
- Optional.ofNullable(playRecordReadService.query(query)) .orElse(Collections.emptyList()) .stream .fileter(this::isValid) .map(Record::getId) .collect(Collectors.toList());
用好異常
Checked Exception是Lambda表達式的天敵,因為在Lambda表達式中必須捕獲Checked Exception,這樣會導致Lambda表達式特別累贅。
針對這種情況,在系統內部最好使用Runtime Exception,如果是外部接口申明了Checked Exception,那我們應該在基礎設施層將外部接口封裝一個facade,facade只拋出Runtime Exception。
有一種系統設計,提倡系統內部接口也使用Result作為返回結果,這種設計導致了很難流暢地使用Lambda表達式,因為你的代碼里面會充斥著大量if (!result.isSuccess())的判斷,如下代碼所示,queryRecordsByCampaign是一個RPC接口,可以看到代碼邏輯非常啰嗦,核心邏輯不明確。
- Result<List<Record>> queryRecordsByCampaign(Campaign campaign) { Result<Void> checkResult = checkCampaign(campaign); if (!checkResult.isSuccess()) { return Result.buildErrorResult(checkResult.getErrorMsg()); } Result<Context> contextResult = buildContext(campaign); if (!contextResult.isSuccess()) { return Result.buildErrorResult(contextResult.getErrorMsg()); } Result<List<Record>> queryResult = queryRecords(contextResult.getValue()); if (!queryResult.isSuccess()) { return Result.buildErrorResult(queryResult.getErrorMsg()); } if (CollectionUtils.isEmpty(queryResult.getValue())) { return Result.buildSuccessResult(Lists.newArraysList()); } List<Record> records = queryResult.getValue().stream() .filter(this::isValid) .map(this::compensateRecord) .collect(Collectors.toList()); return Result.buildSuccessResult(records);}private Result<Void> checkCampaign(Campaign campaign) { if (campaign == null) { return Result.buildErrorResult("活動不能為空"); } if (campaign.getId <= 0) { return Result.buildErrorResult("活動ID非法"); } return Result.buildSuccessResult();}
另外一種系統設計,提倡系統內部使用Runtime Exception控制異常流程,RPC接口不拋任何異常,使用Result表示返回結果。
上面的代碼經過這種思想修改后的代碼如下所示,代碼簡潔明了,Optional與Lambda完美配合。
其中關于參數校驗和斷言可以參考apache工具包中的Validate設計適合自己應用的工具類,通過Validate做校驗非常簡潔,并且可以自定義ExceptionCode來區分錯誤類型。
但是,一定不要使用異常來控制正常流程。
- Result<List<Record>> queryRecordsByCampaign(Campaign campaign) { try { checkCampaign(campaign); List<Record> records = Optional.ofNullable(campaign) .map(this::buildContext) .map(this::queryRecords) .orElse(Collections.emptyList()) .stream() .filter(this::isValid) .map(this::compensateRecord) .collect(Collectors.toList()); return Result.buildSuccessResult(records); } catch (Throwable t) { log.error("an exception occurs ", t) return Result.buildErrorResult(t.getMessage()); }}private void checkCampaign(Campaign campaign) { Validate.notNull(campaign, "活動不能為空"); Validate.gtzero(campaign.getId(), "活動ID非法")}
陷阱
《阿里巴巴開發規約》中提了兩點關于使用toMap()方法的陷阱,如下所示:
在使用java.util.stream.Collectors類的toMap()方法轉為Map集合時,一定要使用含有參數類型為BinaryOperator,參數名為mergeFunction的方法,否則當出現相同key值時會拋出IllegalStateException異常。
在使用java.util.stream.Collectors類的toMap()方法轉為Map集合時,一定要注意當value為null時會拋NPE異常。
另外,我們需要注意toList()可能導致FullGC,因為集合經過map后變成的類型可能占用很大內存,流量高的時候會導致FullGC,這個時候需要采用forEach方式編程。
電商場景中最常見的大內存對象就是ItemDO,一定不要批量獲取ItemDO保存在內存中。
符合閱讀習慣
判斷長度時,if (length >= 10)優于if (10 <= length)。
判斷活動是否已經開始,if (startTime <= now && now <= endTime) 優于 if (now <= endTime && startTime <= now)。
減少if嵌套,條件判斷的時候優先判斷異常情況提前返回,if (!result.isSuccess()) { return false },成功則繼續往下走。
如果if中的條件表達式比較復雜,將復雜的條件表達式封裝成一個函數,通過函數名來解釋表達式的含義。
寫在文末
以上只是從語言特性方面列出了一些簡單的快速的提升代碼可讀性方法,其實還可以從很多方面入手,比如設計模式、架構設計、事物抽象等。
關于架構設計提升代碼可讀性方法,我比較認同“領域驅動設計”思想,充血模型能夠解決復雜業務邏輯使代碼可讀性變差的問題。
提升寫代碼的水平,是我們孜孜不倦的追求,從簡單的業務代碼出發,寫出詩一樣的代碼。