













2019機(jī)器學(xué)習(xí)框架之爭:與Tensorflow競爭白熱化,進(jìn)擊的PyTorch贏在哪里?
大數(shù)據(jù)文摘出品
來源:thegradient
編譯:張大筆茹、曹培信、劉俊寰、牛婉揚(yáng)、Andy
2019年,機(jī)器學(xué)習(xí)框架之爭進(jìn)入了新階段:PyTorch與TensorFlow成為最后兩大玩家,PyTorch占據(jù)學(xué)術(shù)界領(lǐng)軍地位,TensorFlow在工業(yè)界力量依然強(qiáng)大,兩個(gè)框架都在向?qū)Ψ浇梃b,但是都不太理想。
最后誰能勝出?還得看誰更好的回答幾個(gè)關(guān)鍵問題。
來自康奈爾大學(xué)的Horace He剛剛在Gradient發(fā)布了一篇長文探討2019年的兩大機(jī)器學(xué)習(xí)框架之爭,他論述了PyTorch和TensorFlow各自的優(yōu)劣和發(fā)展趨勢,但是很明顯更看好PyTorch,特別是其在學(xué)術(shù)領(lǐng)域起到的驅(qū)動(dòng)作用。
剛好,今天也是PyTorch 1.3發(fā)布的日子,最新的版本增加了更多工業(yè)方面的能力,量化還有終端支持。PyTorch官方稱還將啟動(dòng)許多其他工具和庫,以支持模型的可解釋性,并將多模式研究投入生產(chǎn)。
PyTorch 1.3發(fā)布官方鏈接:
https://PyTorch.org/blog/PyTorch-1-dot-3-adds-mobile-privacy-quantization-and-named-tensors/
機(jī)器學(xué)習(xí)的未來你更看好PyTorch還是TensorFlow呢?也歡迎留言告訴我們。
以下是全文:
自2012年深度學(xué)習(xí)重新獲得突出地位以來,許多機(jī)器學(xué)習(xí)框架也相應(yīng)成為研究人員和行業(yè)從業(yè)者的新寵。
從Caffe和Theano的早期學(xué)術(shù)成果,到業(yè)界支持的大規(guī)模PyTorch和TensorFlow,面對如此多的選擇,人們很難知道最好的框架是什么。

如果從Reddit看,你可能會(huì)認(rèn)為PyTorch風(fēng)頭正盛。但如果你瀏覽的是機(jī)器學(xué)習(xí)大咖Francois Chollet的Twitter,你可能會(huì)認(rèn)為TensorFlow/Keras是主流框架。
2019年,機(jī)器學(xué)習(xí)框架之戰(zhàn)主要是PyTorch和TensorFlow的對峙。
根據(jù)我的分析,在學(xué)術(shù)領(lǐng)域,研究人員正逐漸放棄TensorFlow,扎堆涌向PyTorch。與此同時(shí),在工業(yè)領(lǐng)域,TensorFlow是首選平臺(tái),但這種情況可能不會(huì)持續(xù)很久。
一、PyTorch在研究領(lǐng)域日益占據(jù)主導(dǎo)地位
首先當(dāng)然是先用數(shù)據(jù)說話。
下圖顯示了頂級研究會(huì)議接受論文中,使用TensorFlow或Pythorch的比率。可以發(fā)現(xiàn),所有的折線都向上傾,并且在2019年,主要會(huì)議的論文中,多數(shù)使用的都是PyTorch。

如果覺得僅靠會(huì)議論文數(shù)據(jù)還不夠,這里還有一張圖來證明PyTorch在研究社區(qū)獲得關(guān)注的速度。
下圖顯示了PyTorch和TensorFlow在各類會(huì)議上被提及的次數(shù)圖。

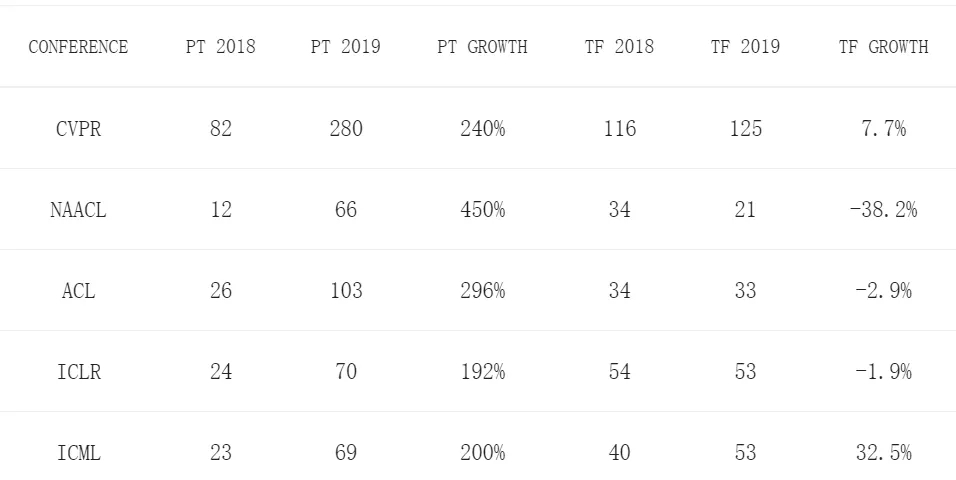
2018年,PyTorch獲得的關(guān)注還比較少。但現(xiàn)在,大多數(shù)人都在使用PyTorch:69%的CVPR、75%以上的NAACL和ACL、50%以上的ICLR和ICML使用的也是PyTorch。
PyTorch在視覺和語言會(huì)議方面的優(yōu)勢最為明顯,分別以2:1和3:1的比例超過了TensorFlow。此外可以看到,在ICLR和ICML等通用機(jī)器學(xué)習(xí)會(huì)議上,PyTorch也比TensorFlow更受歡迎。
雖然有人認(rèn)為PyTorch還是一個(gè)全新的框架,并試圖在TensorFlow主導(dǎo)的世界中分得一杯羹,但是數(shù)據(jù)告訴我們并非如此。除了ICML,在NAACL、ICLR和ACL等會(huì)議上,TensorFlow今年的論文整體上都比去年少。
也就是說,慌的不是PyTorch,而是TensorFlow。
1. 為什么研究人員喜歡PyTorch?
簡單。PyTorch類似于numpy,非常Python化,很容易就能與Python生態(tài)系統(tǒng)的其余部分集成。例如,可以在PyTorch模型中任何地方添加pdb斷點(diǎn)。而在TensorFlow中,調(diào)試模型需要一個(gè)活動(dòng)會(huì)話,整個(gè)過程非常麻煩。
API。大多數(shù)研究人員更喜歡PyTorch的API而不是TensorFlow的API。部分原因是因?yàn)镻yTorch的設(shè)計(jì)更好,還有部分是因?yàn)門ensorFlow切換其API接口過于頻繁(比如“layers”-“slim”-“estimators”-“tf.keras”),這阻礙了其自身的發(fā)展。
表現(xiàn)。盡管PyTorch的動(dòng)態(tài)圖給出的優(yōu)化機(jī)會(huì)很少,但許多傳聞稱PyTorch的速度不比TensorFlow慢多少。目前尚不清楚這是否屬實(shí),但至少,TensorFlow在這一方面還沒有獲得決定性的優(yōu)勢。
2. TensorFlow 未來的研究方向是什么?
即使TensorFlow在功能上與PyTorch不相上下,但PyTorch已經(jīng)覆蓋了機(jī)器學(xué)習(xí)社區(qū)的大部分。這意味著PyTorch實(shí)現(xiàn)將更容易找到,作者將更有動(dòng)力用PyTorch發(fā)布代碼,而且你的合作者也很可能會(huì)更喜歡PyTorch。因此,任何向TensorFlow 2.0的回遷可能會(huì)很慢。
TensorFlow在Google/Deepmind中有一批忠實(shí)的用戶,但不知道Google最終是否會(huì)在這一點(diǎn)上動(dòng)搖。現(xiàn)在,很多Google想招募的研究人員已經(jīng)開始喜歡上PyTorch了,我也聽到抱怨說Google內(nèi)部很多研究人員希望使用TensorFlow之外的框架。
此外,PyTorch的統(tǒng)治地位很可能會(huì)切斷谷歌研究人員與其他研究社區(qū)的聯(lián)系。他們不僅難以在外部研究的基礎(chǔ)上進(jìn)行構(gòu)建,而且外部研究人員也不太可能在谷歌發(fā)布的代碼基礎(chǔ)上進(jìn)行構(gòu)建。
TensorFlow 2.0是否能重新俘獲回之前的粉絲還有待觀察。盡管eager模式很吸引人,但對于Keras API而言并非如此。
二、用于產(chǎn)業(yè)的PyTorch和TensorFlow
雖然PyTorch目前在研究領(lǐng)域占據(jù)主導(dǎo)地位,但稍微注意一下就會(huì)發(fā)現(xiàn)TensorFlow仍然是占據(jù)主導(dǎo)地位的框架。
例如,根據(jù)2018年到2019年的數(shù)據(jù),TensorFlow在招聘的頁面上有1541個(gè)新工作崗位,而PyTorch有1437個(gè),TensorFlow在Medium上有3230個(gè)新文章,而PyTorch有1200篇,TensorFlow在GitHub有13.7K標(biāo)星,而PyTorch有7.2K。
那為什么PyTorch現(xiàn)在已經(jīng)如此受研究人員歡迎了,但它在工業(yè)上還沒有同樣的成功呢?
顯而易見的第一個(gè)答案就是使用習(xí)慣。TensorFlow比PyTorch早幾年問世,而產(chǎn)業(yè)接受新技術(shù)的速度要比研究人員慢。
另一個(gè)原因就是TensorFlow在產(chǎn)業(yè)適應(yīng)方面優(yōu)于PyTorch,什么意思呢?要回答這個(gè)問題,我們需要知道研究人員和工業(yè)界的需求有何不同。
研究人員關(guān)心的是他們在研究中迭代的速度有多快,這通常是在相對較小的數(shù)據(jù)集(可以在一臺(tái)機(jī)器上運(yùn)行的數(shù)據(jù)集)上,并在8個(gè)GPU上就可以運(yùn)行。這通常不是出于對性能的考慮,而是更關(guān)注可以快速實(shí)現(xiàn)自己的想法。
而工業(yè)界則認(rèn)為性能是最優(yōu)先考慮的。雖然運(yùn)行時(shí)速度提高10%對研究人員來意義不大,但這可以直接為公司節(jié)省數(shù)百萬美元。
另一個(gè)區(qū)別是部署。研究人員一般在自己的機(jī)器上或某個(gè)專門用于運(yùn)行研究工作的服務(wù)器集群上進(jìn)行實(shí)驗(yàn)。但是在產(chǎn)業(yè)上,部署則有一連串的限制與要求。
- 沒有Python。運(yùn)行Python對服務(wù)器的開銷太大了;
- 移動(dòng)。你不能在移動(dòng)終端二進(jìn)制文件中嵌入Python解釋器;
- 服務(wù)。需要包羅萬象的功能:不用停機(jī)更新的模型,在模型之間無縫切換,批處理在預(yù)測時(shí)間,等等。
TensorFlow就是特別針對這些需求構(gòu)建的,并為所有這些問題提供了解決方案:網(wǎng)絡(luò)圖格式和執(zhí)行引擎本身不需要Python,而TensorFlow Lite和TensorFlow Serving可以分別處理移動(dòng)終端和服務(wù)器需求。
從歷史上看,PyTorch在滿足這些需求方面做得還不夠,因此大多數(shù)公司目前在生產(chǎn)中都還是使用 TensorFlow。
三、架構(gòu)「融合」
2018年末,兩件大事徹底改變了這一局面:
PyTorch引入了JIT編譯器和“TorchScript”,從而引入了基于圖的特性;
TensorFlow宣布他們將在2.0版本中默認(rèn)轉(zhuǎn)移到Eager模式。
顯然,這些舉措都是為了解決PyTorch和TensorFlow各自的弱點(diǎn)。那么這些特性到底是什么,它們能提供什么呢?
1. PyTorch TorchScript
PyTorch JIT是PyTorch的一個(gè)中間表示(intermediate representation,IR) ,稱為TorchScript。Torchscript是PyTorch的“圖”表示。你可以通過使用跟蹤或腳本模式將常規(guī)PyTorch模型轉(zhuǎn)換為TorchScript。跟蹤接受一個(gè)函數(shù)和一個(gè)輸入,記錄用該輸入執(zhí)行的操作,并構(gòu)造IR。
雖然很簡單,但是跟蹤也有它的缺點(diǎn)。例如,它不能捕獲未執(zhí)行的控制流。例如,如果它執(zhí)行了true塊,它就不能捕獲條件塊的false塊。
Script模式接受一個(gè)函數(shù)/類,重新解釋Python代碼并直接輸出TorchScript IR。這允許它支持任意代碼,但是它實(shí)際上需要重新解釋Python。

一旦PyTorch模型進(jìn)入了這個(gè)IR,我們就可以獲得圖模式的所有優(yōu)勢。我們既可以在C++中部署PyTorch模型,而不依賴Python,或者對其進(jìn)行優(yōu)化。
2. TensorFlow Eager
在API級別上,TensorFlow Eager模式基本上與PyTorch Eager模式相同,后者最初由Chainer推出,這為TensorFlow提供了PyTorchEager模式的大部分優(yōu)勢(易用性、可調(diào)試性等等)
然而,這也給TensorFlow帶來了同樣的缺點(diǎn)。TensorFlow Eager模型不能導(dǎo)出到非python環(huán)境中,也不能進(jìn)行優(yōu)化,不能在移動(dòng)設(shè)備上運(yùn)行。
這將TensorFlow置于與PyTorch相同的位置,它們的解析方式基本相同——你可以跟蹤代碼(tf.function)或重新解釋Python代碼(Autograph)。
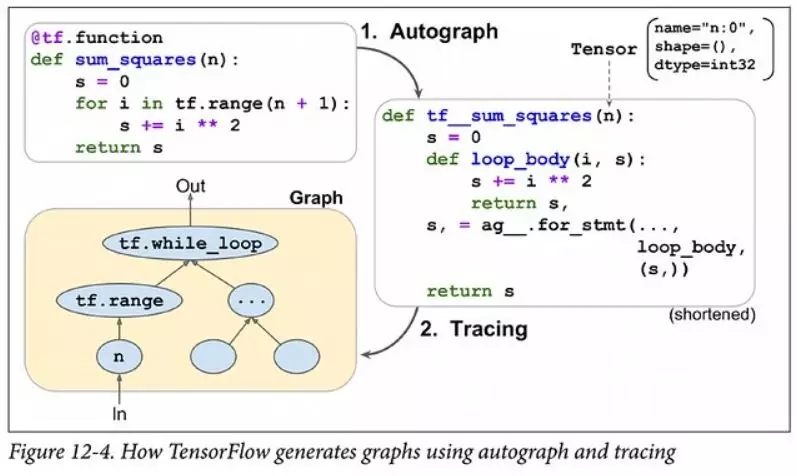
因此,TensorFlow的Eager模式并不能真正做到“兩全其美”。雖然可以使用 tf.function注釋將eager code轉(zhuǎn)換為靜態(tài)圖,但這永遠(yuǎn)不會(huì)是一個(gè)無縫轉(zhuǎn)換的流程(PyTorch的TorchScript也有類似的問題)。跟蹤基本上是有限的,重新解釋Python代碼實(shí)際上需要重寫Python編譯器的大部分內(nèi)容。
當(dāng)然,通過限制在深度學(xué)習(xí)中使用的Python子集,范圍可以大大簡化。
在默認(rèn)啟用Eager模式時(shí),TensorFlow將強(qiáng)迫用戶做出選擇——為了便于使用而Eager執(zhí)行,并且需要為部署而重寫,或者根本不使用急于執(zhí)行。
雖然這與PyTorch的情況相同,但PyTorch的TorchScript的可選擇加入特性可能比TensorFlow的“默認(rèn)Eager”更容易接受。
四、機(jī)器學(xué)習(xí)框架的現(xiàn)狀
PyTorch在研究領(lǐng)域領(lǐng)先,并試圖擴(kuò)展到工業(yè)領(lǐng)域。而TensorFlow正試圖在不犧牲太多產(chǎn)業(yè)優(yōu)勢的情況下,更多的參與到研究領(lǐng)域。
PyTorch要在行業(yè)中產(chǎn)生有意義的影響肯定還需要很長時(shí)間,畢竟TensorFlow在產(chǎn)業(yè)界的影響力已經(jīng)根深蒂固。然而,從TensorFlow 1.0到2.0的轉(zhuǎn)換為企業(yè)評估PyTorch提供了一個(gè)絕佳的機(jī)會(huì)。
至于未來,將取決于誰能最好地解決以下問題。
- 研究者偏好對產(chǎn)業(yè)的影響有多大?隨著當(dāng)前一批博士研究生開始畢業(yè),他們也許會(huì)帶上用慣的PyTorch。這種勢頭是否足夠明顯,以至于公司會(huì)選擇PyTorch用于招聘的條件?同時(shí)畢業(yè)生會(huì)在PyTorch的基礎(chǔ)上創(chuàng)業(yè)嗎?
- TensorFlow的Eager模式在可用性上能趕上PyTorch嗎?就網(wǎng)上的反應(yīng)來看,TensorFlow Eager嚴(yán)重受到性能/內(nèi)存方面問題的困擾,而且Autograph也有自己的問題。谷歌將花費(fèi)大量的工程努力,但TensorFlow還是背負(fù)著歷史包袱
- PyTorch滿足產(chǎn)業(yè)需求的速度有多快?PyTorch還有許多沒有解決的基本問題——沒有好的量化支持、不支持移動(dòng)等等。在這些問題得到解決之前,PyTorch甚至不會(huì)成為許多公司的選擇。PyTorch能否為企業(yè)提供一個(gè)足夠吸引人的故事來進(jìn)行轉(zhuǎn)型?注意:PyTorch已經(jīng)宣布支持量化和移動(dòng)。雖然兩者都還處于試驗(yàn)階段,但代表了PyTorch在這方面的重大進(jìn)展。
- 谷歌在行業(yè)中的孤立會(huì)傷害TensorFlow嗎?谷歌推動(dòng)TensorFlow的主要原因之一是幫助其蓬勃發(fā)展的云服務(wù)。由于谷歌試圖擁有整個(gè)機(jī)器學(xué)習(xí)垂直領(lǐng)域,這促使谷歌與之競爭的公司(如微軟、亞馬遜、Nvidia)支持只能支持PyTorch。
五、下一步怎么走?
機(jī)器學(xué)習(xí)框架在多大程度上影響了機(jī)器學(xué)習(xí)的研究呢?
它不僅使機(jī)器學(xué)習(xí)研究成為可能,更讓研究人員能夠更輕松地探索。有多少新的想法因?yàn)闆]有簡單的方法在框架中表達(dá)而被扼殺?PyTorch已經(jīng)達(dá)到了研究的本地極小值,但是值得研究的其他框架提供了什么?還有什么樣的研究機(jī)會(huì)?
1. 計(jì)算高階導(dǎo)數(shù)的問題
PyTorch和TensorFlow的核心是自動(dòng)差異化框架,它能對某個(gè)函數(shù)求導(dǎo)。實(shí)現(xiàn)自動(dòng)微分的方法有很多,大多數(shù)現(xiàn)代機(jī)器學(xué)習(xí)框架所選擇的方法被稱為“逆向模式自動(dòng)微分”,也就是通常所說的“反向傳播”。對神經(jīng)網(wǎng)絡(luò)的衍生而言,這種實(shí)現(xiàn)是非常有效的。
然而,在計(jì)算高階導(dǎo)數(shù)(Hessian/Hessian Vector Products)時(shí),就出問題了。有效地計(jì)算需要“正向模式自動(dòng)微分”,如果沒有這個(gè)功能,Hessian Vector Products的計(jì)算速度就會(huì)降低一個(gè)數(shù)量級。
Jax是由最初建造Autograd的同一批人創(chuàng)建的,它具有正向和反向模式自動(dòng)分化的功能,這使得計(jì)算高階導(dǎo)數(shù)的速度比PyTorch/TensorFlow的更快。
并且,Jax不僅能計(jì)算高階導(dǎo)數(shù),Jax開發(fā)人員將Jax視為組成任意函數(shù)轉(zhuǎn)換的框架,包括vmap(用于自動(dòng)批處理)或pmap(用于自動(dòng)并行化)。
Jax最初的使用者主要是大學(xué)畢業(yè)生(盡管沒有GPU支持,但I(xiàn)CML有11篇論文使用了它),但相信Jax很快就會(huì)找到一個(gè)類似的忠實(shí)粉絲社區(qū),用它來做各種n階導(dǎo)數(shù)。
2. 不夠靈活!
當(dāng)運(yùn)行PyTorch/TensorFlow模型時(shí),大部分工作實(shí)際上并不是在框架本身中完成的,而是由第三方內(nèi)核完成的。這些內(nèi)核通常由硬件供應(yīng)商提供,類似于MKLDNN(用于 CPU)或cuDNN(用于Nvidia GPUs),由高級框架可以利用的操作符庫組成。高級框架將計(jì)算圖表分解成塊,然后調(diào)用計(jì)算庫。這些庫代表了數(shù)千小時(shí)的工作量,并針對體系結(jié)構(gòu)和應(yīng)用程序進(jìn)行優(yōu)化以獲得最佳性能。
然而,最近非標(biāo)準(zhǔn)硬件、稀疏/量子化張量和新運(yùn)算符的流行暴露了依賴這些運(yùn)算符庫的一個(gè)缺陷:它們不夠靈活!如果你想在研究中使用像膠囊網(wǎng)絡(luò)(capsule networks)這樣的新操作怎么辦?現(xiàn)有的解決方案還不夠完善。正如本文所說,現(xiàn)有的膠囊網(wǎng)絡(luò)在GPU上的實(shí)現(xiàn)比最優(yōu)實(shí)現(xiàn)慢2個(gè)數(shù)量級。
每個(gè)新的硬件體系結(jié)構(gòu)、張量或算子的類別,都大大增加了問題的難度。目前已經(jīng)有許多處理工具,如Halide、TVM、PlaidML、TensorComprehensions、XLA、Taco等,但是正確的方法還沒找到。
如果沒有解決這個(gè)問題,我們就會(huì)面臨機(jī)器學(xué)習(xí)研究與工具過度匹配的風(fēng)險(xiǎn)。
六、機(jī)器學(xué)習(xí)框架的未來
對于TensorFlow和PyTorch的未來,他們的設(shè)計(jì)已經(jīng)趨于一致,任何一個(gè)框架都不會(huì)憑借其設(shè)計(jì)而取得最終勝利,每一方也都有自己的地盤——一方擁有研究,另一方擁有工業(yè)。
就我個(gè)人而言,在PyTorch和TensorFlow之間,我會(huì)覺得PyTorch更有勝算。因?yàn)闄C(jī)器學(xué)習(xí)仍然是一個(gè)研究驅(qū)動(dòng)的領(lǐng)域,工業(yè)界不能忽視研究成果,只要PyTorch在研究領(lǐng)域占據(jù)主導(dǎo)地位,企業(yè)就只有被迫轉(zhuǎn)型。
然而,跑得足夠快的不僅僅是框架。機(jī)器學(xué)習(xí)研究本身也處于一個(gè)巨大的變革中。不僅框架發(fā)生了變化,5年來使用的模型、硬件、范式與我們今天使用的截然不同。未來也許PyTorch和TensorFlow之間的戰(zhàn)爭將變得無關(guān)緊要,因?yàn)榱硪环N計(jì)算模型或?qū)⒄紦?jù)主導(dǎo)地位。
在所有這些相互沖突的利益中,機(jī)器學(xué)習(xí)投入了大量資金,退一步想想其實(shí)也不錯(cuò)。大多數(shù)從事機(jī)器學(xué)習(xí)軟件的工作不是為了賺錢,也不是為了協(xié)助公司的戰(zhàn)略計(jì)劃,而是想要推進(jìn)機(jī)器學(xué)習(xí)的研究,關(guān)心人工智能民主化,也或許他們只是想創(chuàng)造一些很酷的東西。
所以,不管你更喜歡TensorFlow還是PyTorch,它們的目的只有一個(gè),就是想讓機(jī)器學(xué)習(xí)做到最好。
相關(guān)報(bào)道:
https://thegradient.pub/state-of-ml-frameworks-2019-PyTorch-dominates-research-TensorFlow-dominates-industry/?nsukey=RG9rAFcvX0owsip%2BviuAbdWRIFSgV1Yvu7Oj6KhVNWWGEpmoUHaDqlPyjAOIGgCho%2B2PznlO1KQYW8u9DRdYlPaILzqUApS1GAhmL3M0gzBGeyCQhOpiftWASSZTR1xaNMzV7VwTuLvCfUyjKAw1TyuzeOQxF8yhnIiuGJcRdthH7JX%2FaOLMtMfgaiDs0TuIDe5lMlcmhRZtnAg3YP30gg%3D%3D
【本文是51CTO專欄機(jī)構(gòu)大數(shù)據(jù)文摘的原創(chuàng)譯文,微信公眾號(hào)“大數(shù)據(jù)文摘( id: BigDataDigest)”】













