用AI實現動畫角色的姿勢遷移,Adobe等提出新型「木偶動畫」
相比于依靠創作者手繪的動畫,木偶動畫的制作是個非常繁瑣的過程,我們需要將一個動作分解成若干個環節,逐幀拍攝再連續放映為影片。近日,Adobe 和康奈爾大學提出了一種名為「變形木偶模板」的動畫制作方法,可實現基于少量卡通角色樣本生成新角色動作,和木偶動畫的制作方法倒是有異曲同工之妙。
近日,Adobe 和康奈爾大學的研究人員提出一種基于學習的動畫制作方法——基于卡通角色的少量圖像樣本就可生成新動畫。
傳統動畫制作中,每一幀都是由創作者親手繪制完成的,因而輸入的圖像缺乏共同結構、配準或標簽。研究人員將動畫角色的動作變化演繹為一個層級 2.5D 模板網格的變形,并設計了一種新型架構,來學習預測能夠匹配模板和目標圖像的網格變形,從而實現由多樣化的角色動作集合中抽象出共同的低維結構。研究人員將可微渲染和網格感知(mesh-aware)模型結合起來對齊通用模板,哪怕只有少量卡通角色圖像可以用來訓練也沒關系。
除了動作,卡通角色的外觀也會因為陰影、離面運動(out-of-plane motion)和圖片藝術效果而呈現細微的差異。研究人員使用圖像平移網絡(image translation network)來捕捉這些細微變化,并改進了網格渲染結果。他們還為了生成更高質量的卡通角色新動畫搭建了一個端到端的模型,這個模型可用于合成中間幀和創建數據驅動的變形,其模板擬合(template fitting)步驟在檢測圖像配準方面的效果明顯優于當前的通用技術。
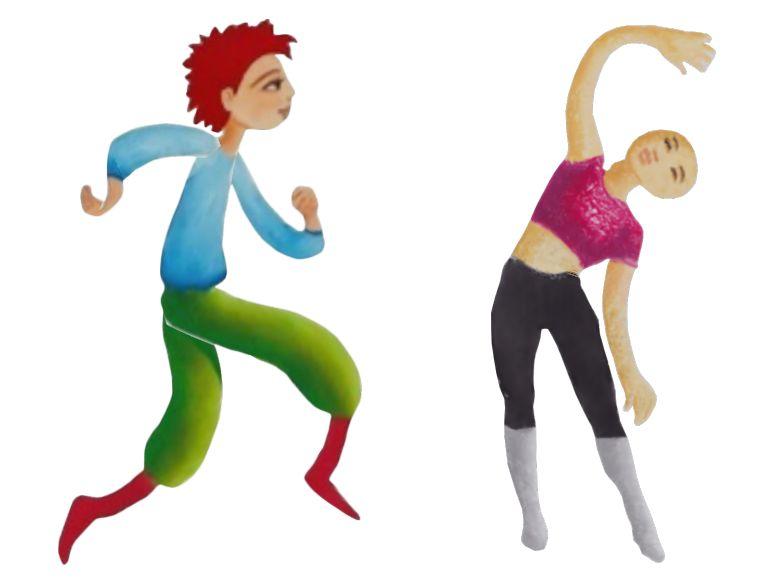
Adobe 新方法生成圖像的 1024 × 1024 版本示例。
卡通角色動畫制作的難點
傳統的角色動畫制作過程較為繁瑣,需要多名創作者合力,并且要非常細致地完成每一幀動作的繪制。
在《起風了:1000日的創作記錄》中,宮崎駿透露,這幾秒鐘的鏡頭耗時1年零3個月。
人類在觀察多個動作序列后,很容易想象出這個角色在做其他姿勢時的細節樣貌,但這對于算法而言沒那么容易:關節接合、藝術效果和視角變化等都會對圖像外觀產生大量細微差別,這些極大增加了提取底層角色結構的復雜度。人類的自然圖像尚且可以依賴大量標注或數據來提取共同結構,但這種方法不適用于卡通角色,因為拓撲結構、幾何和繪畫風格不具備那么強的一致性。
Adobe 的解決之道
正是為了解決這一難題,Adobe 提出了一種依靠「變形木偶模板(deformable puppet template)」去基于少量圖像樣本生成動畫角色新外觀的方法。
研究人員先假設所有的角色姿勢都可以通過扭曲變形模板來生成,開發出一個變形網絡(deformation network),以及這個網絡編碼圖像和解碼模板的變形參數;然后在可微渲染層中使用這些參數,渲染出與輸入幀相匹配的圖像。重建損失可在所有階段中進行反向傳播,從而學習如何對所有訓練幀登記該模板。
不過,渲染結果的姿勢雖然合理,但這個結果相對于創作者繪制成的圖像還是有些遜色,因為它們僅僅扭曲了一個參考輸入,沒有捕捉到陰影、藝術效果等因素造成的輕微外觀差別。為了進一步改善渲染結果的視覺質量,研究人員使用圖像平移網絡來合成最終外觀。
這項研究用到的是學界和工業界常用的層級 2.5D 變形模型(layered 2.5D deformable model),再匹配上多種傳統人工繪制動畫風格。如此一來,相對于需要大量專業知識才能使用的 3D 建模模板,用戶會輕松許多。假如用戶想生成木偶,選擇單個幀,再將前景角色分割成多個身體構成組件,然后就可以使用標準三角剖分(triangulation)工具將其轉化為網格。
在六個動畫角色的制作任務中,研究人員使用 70%-30% 的訓練-測試分割比例去評估了這個新方法:
首先,評估模型重建輸入幀的效果,發現其輸出的結果比當前最優的光流和自編碼器技術更加準確。
其次,評估登記模板(registered template)估計出的配準質量,發現其效果優于圖像配準方法。
最后,證明該模型可用于數據驅動的動畫制作,即合成動畫幀由訓練時獲取的角色外觀決定。研究人員構建了合成中間幀和根據用戶指定變形制作動畫的原型應用,根據角色生成合理變形后的新圖像。相比于計算機圖形學基于能量的傳統優化技術,這一數據驅動方法得到的角色姿勢更加逼真,也更加接近創作者繪畫水準。
方法
這項研究的目標是學習一個變形模型,基于一組無標注圖像集合生成卡通角色。首先,用戶通過分割一個參考幀來創建層級變形模板木偶;然后訓練一個兩階神經網絡:第一階段學習如何扭曲木偶模板來重新設計角色外觀,從而將變形木偶與輸入序列中的每一幀進行匹配;第二階段改進變形木偶的渲染結果,實現上個 2D 扭曲階段無法呈現的紋理變化和動作效果。
層級變形木偶
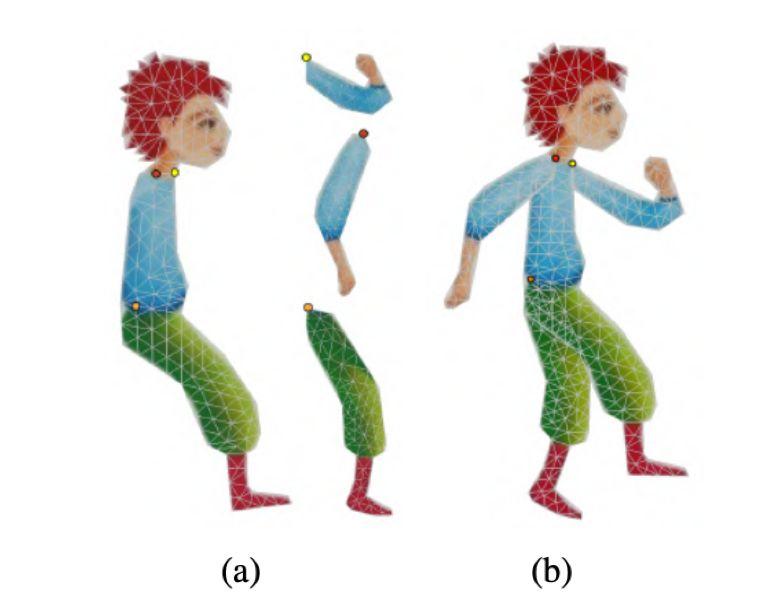
圖 1:變形木偶。a)為每一個身體部位創建單獨的網格,并標記關節(見圖中圓圈);b)將這些網格連接起來,最終網格的 UV 圖像包括分割紋理圖的平移版本。
與 3D 建模不同,層級 2D 木偶的使用方法要簡單得多,即使沒有經驗的用戶也可以使用。首先,用戶選擇一個參考幀,提供不同身體部位及其順序的輪廓,然后用標準三角剖分算法為每個部位生成網格,并在兩個部位重疊區域的質心處創建關節點;之后運行中間點網格細分(midpoint mesh subdivision),就可以調整更多細節,得到更加精細的網格了。
變形網絡
獲得變形網絡模板后,就可以學習如何使模板變形以匹配目標角色圖像的新姿勢了。
圖 2 展示了訓練架構:
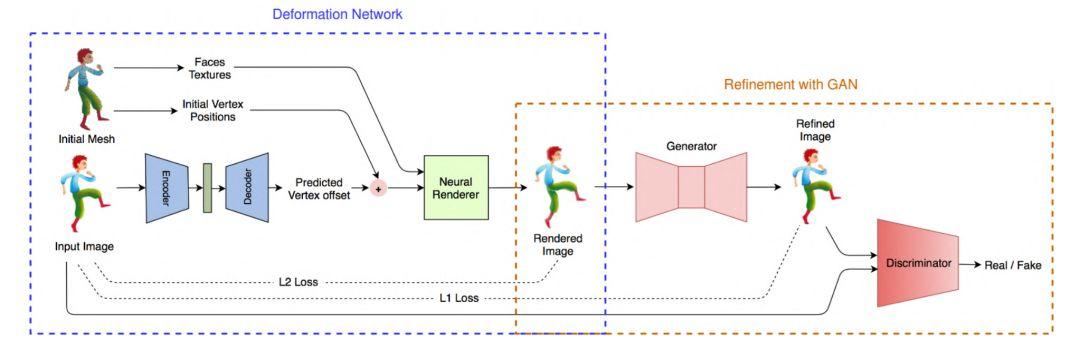
圖 2:訓練架構。編碼器-解碼器網絡學習網格變形,條件生成對抗網絡改進渲染圖像,以捕捉紋理變化。
變形網絡的輸入指的是初始網格和使用新姿勢的目標角色圖像,編碼器-解碼器網絡通過卷積濾波器將目標圖像編碼至瓶頸層,然后通過全連接層將其解碼為頂點位置偏移(vertex position offset)。這樣一來,網絡就能夠識別輸入圖像中的姿勢,并推斷出生成這一姿勢的合適模板變形。
外觀改進網絡
盡管變形網絡可以捕捉到大部分關節,但還是有一些細微的外觀效果變化(如藝術風格、陰影效果和離面運動)無法通過以上步驟來實現。
所以研究人員跟進推出了「外觀改進網絡」,對變形得到的圖像再進行細化處理。該架構和訓練步驟類似于條件生成對抗網絡。生成器對渲染圖像進行精細處理,使其更加自然貼合。
實驗結果及應用

圖 3:輸入圖像、Adobe 方法的渲染結果和最終結果,以及 PWC-Net [55] 和 DAE [52] 的結果。(輸入圖像中前三個角色由 Zuzana Studena 繪制,第四個角色由 Adobe Character Animator 繪制。)
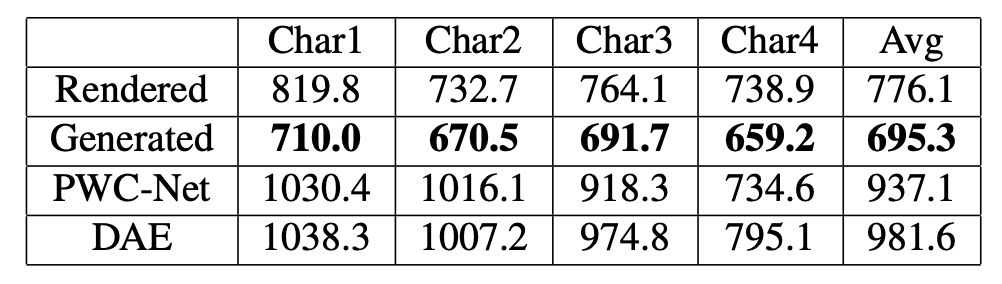
表 1:目標圖像和生成圖像之間的平均 L2 距離。該表展示了 Adobe 方法的渲染圖像和生成圖像與 PWC-Net [55]、Deforming Autoencoders [52] 的對比結果。最后一列表示六個不同角色的平均 L2 距離。
圖 4:將 Adobe 方法的輸出結果渲染為 1024 × 1024 圖像的示例。