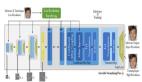
兼顧圖像超分辨率、圖像再縮放,ETH提出新型統一框架HCFlow
近年來,歸一化流(Normalizing Flow)模型在圖像超分辨率(image SR)[SRFlow, ECCV2020]和圖像再縮放(image rescaling)[IRN, ECCV2020]任務上取得了驚人的效果。盡管這兩個任務有本質的不同,但都具有高度的相似性。基于以上兩個工作,來自蘇黎世聯邦理工學院計算機視覺實驗室的研究者提出了 HCFlow,使用一個統一的框架處理圖像超分辨率和圖像再縮放,并在通用圖像超分辨率、人臉圖像超分辨率和圖像再縮放上等任務上取得了最佳結果。該論文已被 ICCV2021 接收。

- 論文地址: https://arxiv.org/abs/2108.05301
- Github 地址: https://github.com/JingyunLiang/HCFlow
摘要
近期,歸一化流(Normalizing Flow)模型在底層視覺領域取得了驚人的效果。在圖像超分辨率上(image SR),可以用來從低分辨率圖像中預測出細節不同的高質量高分辨率(diverse photo-realistic)圖像。在圖像再縮放(image rescaling)上,可以用來聯合建模下采樣和上采樣過程,從而提升性能。
本文提出了一個統一的框架 HCFlow,可以用于處理這兩個問題。具體而言,HCFlow 通過對低分辨率圖像和丟失的高頻信息進行概率建模,在高分辨率和低分辨率圖像之間學習一個雙射(bijection)。其中,高頻信息的建模過程以一種多層級的方式條件依賴于低分辨率圖像。在訓練中,該研究使用最大似然損失函數進行優化,并引入了感知損失函數(perceptual loss)和生成對抗損失函數(GAN loss)等進一步提升模型效果。
實驗結果表明,HCFlow 在通用圖像超分辨率、人臉圖像超分辨率和圖像再縮放等任務上取得了最佳的結果。
圖像超分辨率 v.s. 圖像再縮放
圖像超分辨率的目標是從低分辨率圖像中重建出高分辨率圖像。低分辨率圖像空間一般是給定的。例如,雙三次降采樣 (bicubic downsampling)圖像。
圖像再縮放的目標是將高分辨率圖像下采樣到視覺效果較好的低分辨率圖像,并且保證可以很好地恢復出原本的高分辨率圖像。與圖像超分任務不同,圖像再縮放中低分辨率圖像空間是可以自己定義的。它的主要應用場景是減少圖像存儲和帶寬。
方法
歸一化流簡單介紹
歸一化流(Normalizing Flow)模型致力于在目標空間(例如高分辨率圖像 x)和隱空間(例如服從高斯分布的隱變量 z)之間學習一個雙射。它的模型結構通常是由多層可逆變換組成的一個可逆神經網絡(invertible neural network):
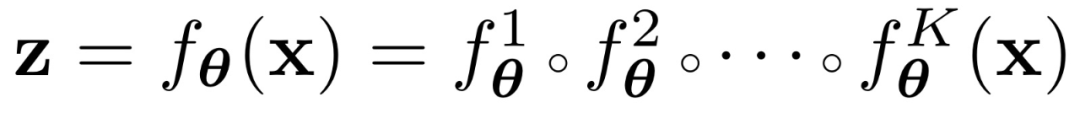
根據變量變換公式(change of variable formula)和鏈式法則,模型參數可以通過下面的最大似然損失函數進行優化:
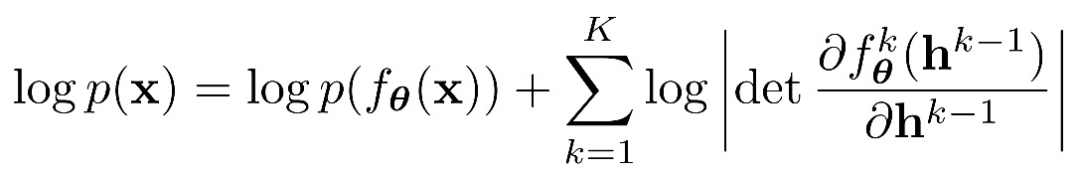
更多入門信息可以參考:
- RealNVP論文:https://arxiv.org/abs/1605.08803
- Glow論文:https://arxiv.org/abs/1807.03039
- Eric Jang博客:https://blog.evjang.com/2018/01/nf1.html
- 滑鐵盧大學CS480:https://www.youtube.com/watch?v=3KUvxIOJD0k
低分辨率圖像空間建模
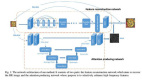
圖像超分辨率和圖像再縮放任務實際上都有一個圖像退化(降采樣)和圖像超分(上采樣)的過程。基于歸一化流模型,該研究可以在高分辨率圖像 x 和低分辨率圖像 y 以及一個編碼高頻信息的隱變量 a 之間學習一個可逆雙射變換
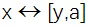
。由于直接對自然圖像進行概率建模是很難的,該研究設計了一個基于真實低分辨率圖像 y * 的條件分布模型:
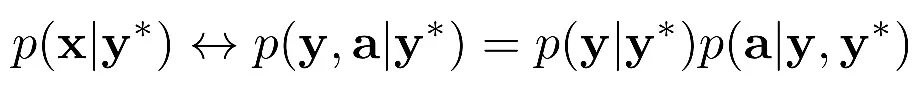
理想情況下,研究者希望 y 和 y * 越接近越好,所以他們將 p(y|y*)表示為狄拉克函數
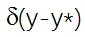
,并通過一個具有極小方差的高斯分布來近似表示 p(y|y*):
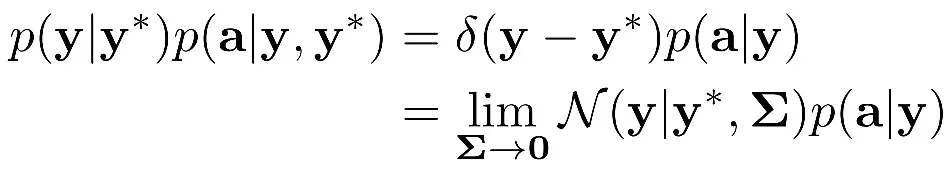
由于高頻信息 p(a|y)可以通過另一個歸一化流模型變換為一個高斯分布 p(z),整個模型可以定義為:
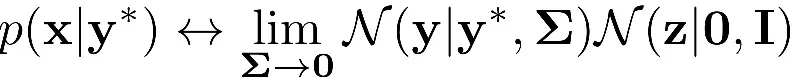
這樣,高分辨率圖像 x 就可以通過一個可逆神經網絡變換為低分辨率圖像 y 和編碼高頻信息的隱變量 z,且都服從參數已知的高斯分布。因此,我們可以方便地通過計算最大似然損失函數來優化模型。
多層級網絡結構
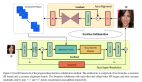
為了更好地建模低分辨率圖像和高頻信息之間的關系(即 p(a|y)),該研究進一步提出了一個多層級條件依賴建模框架。在保持整體網絡可逆性的條件下,逐步恢復高頻信息,重建出高分辨率圖像。如下圖所示,歸一化流的前向過程類似于二叉樹的深度優先遍歷,而反向過程則從最深層逐步計算至第一層。y 和 a 分別代表各層的低頻和高頻信息,數字代表計算順序,藍色箭頭代表條件依賴關系。
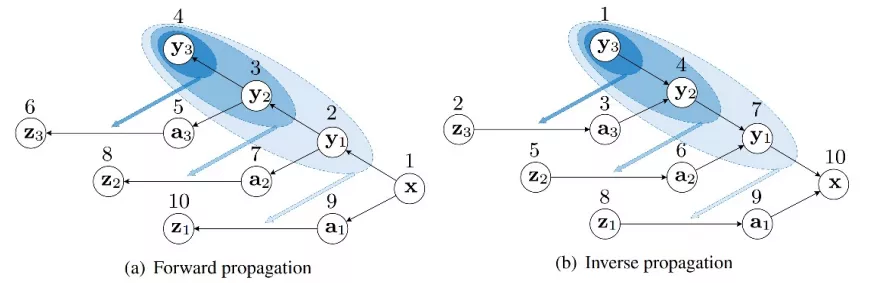
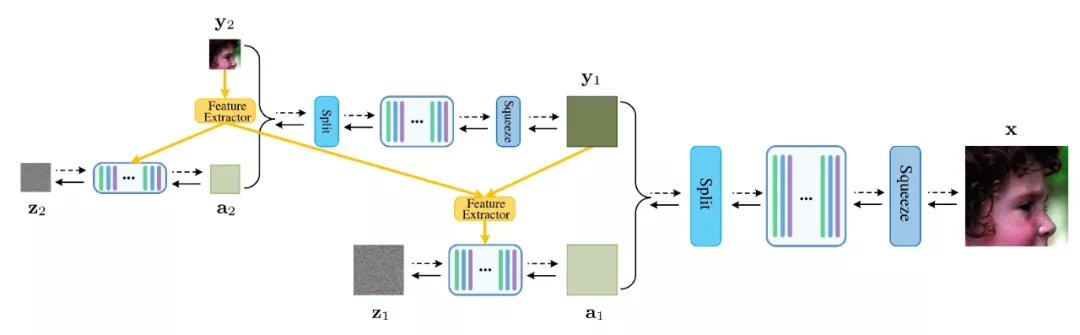
具體的網絡結構如下圖所示。
實驗
圖像超分辨率
該研究使用最大似然損失函數訓練模型,并使用 L1 損失函數,感知損失函數(perceptual loss)和生成對抗損失函數(GAN loss)進一步提升模型效果。在參數量下降 1/3 的情況下,HCFlow 在通用圖像超分辨率和人臉圖像超分辨率上,都取得了最佳的結果。在不同的隨機采樣中,可以生成細節不同的高質量高分辨率圖像。值得注意的是,與 基于 GAN 的模型類似,基于歸一化流的模型主要關注視覺效果,PSNR 通常有所下降。
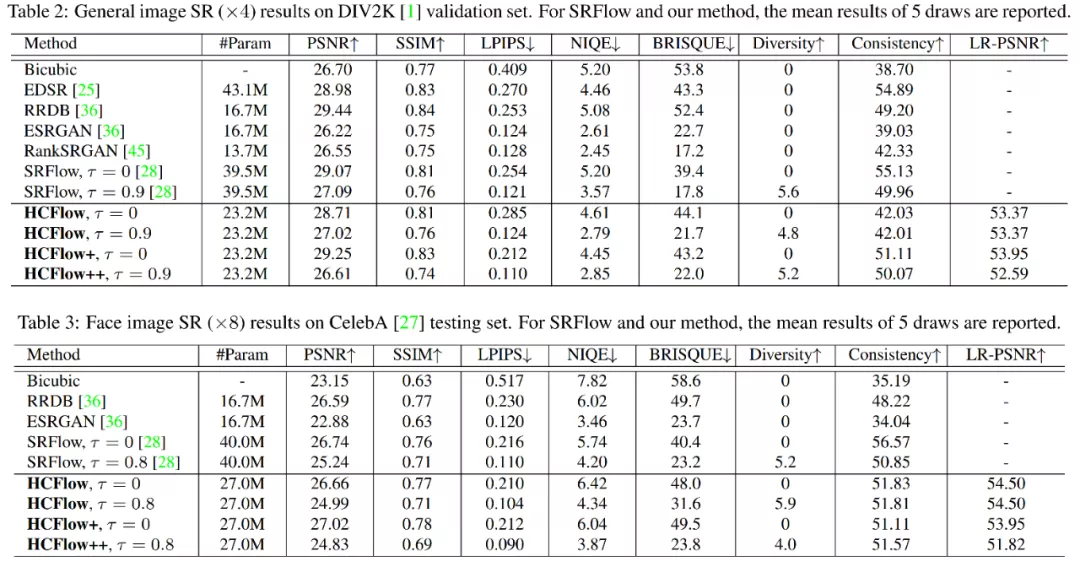


圖像再縮放
由于圖像再縮放通常不關注重建結果的多樣性,HCFlow 采用與 IRN (ECCV2020)一致的訓練策略,將前向過程和反向過程分別視為編碼和解碼過程。訓練損失函數包括在高分辨率圖像和低分辨率圖像上的 L1 損失函數,以及在隱變量上的約束。在相近的模型參數量下,取得了 0.10-0.34dB 的提升。
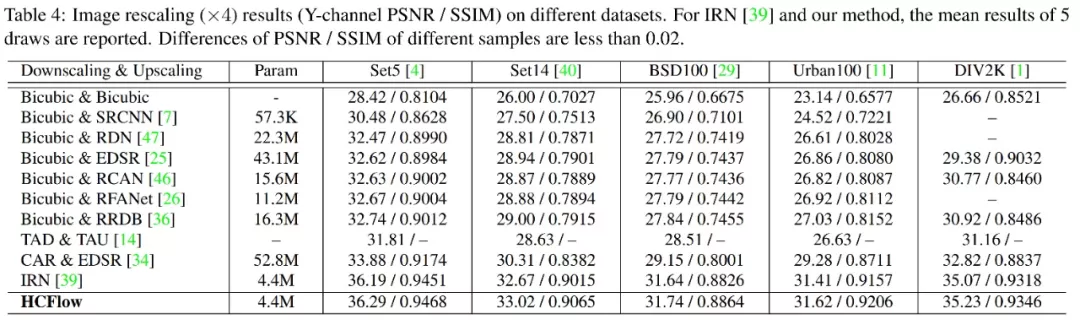

更多的模型細節請閱讀 [論文原文] 和已開源的[代碼]。