傳統數據庫不適合現代企業架構了?
在 2011 年,Marc Andressen 寫了一篇文章,題目是《為什么軟件正在吞噬整個世界》。其中心思想是如果流程可以通過軟件來實現,那么就一定會實現。這已經成為一種投資理論簡略的表達方式,這種理論隱藏在硅谷目前獨角獸初創企業浪潮的背后。它還是我們如今看到的更廣泛的技術趨勢背后的統一思想,這些技術包括機器學習、物聯網、無處不在的 SaaS 以及云計算。這些趨勢都在用不同的方法使軟件變得更豐富和功能強大,并在企業間擴大其影響范圍。
我認為,伴隨而來的變化容易被忽視但同樣重要。這不僅僅是企業使用更多的軟件,而且越來越多的企業通過軟件重新定義。也即,企業執行的核心過程(從生產產品的方式到與客戶交互的方式、交付服務的方式)正變得越來越多地在軟件中指定、監控和執行。這已經是大多數硅谷技術公司的事實情況,但是,這種轉變正在蔓延到所有類型的公司,無論其提供什么產品或服務。
為了澄清我的意思,讓我們來看一個例子:消費銀行的貸款批準流程。這是一個在計算機出現以前就存在的業務流程。傳統上,這是一個需要幾個星期才能完成的流程,其中涉及銀行代理人、抵押貸款官員和信貸官員等,各自以手動過程進行協作。如今,該流程趨向于以半自動化的方式執行,這些功能都有一些獨立的軟件應用程序,可以幫助使用者更有效地執行。
然而現在,在很多銀行中這個操作正在變為一個完全自動化的流程,其中信貸軟件、風險軟件和 CRM 軟件之間相互通信并在幾秒內提供決策。這里,銀行貸款業務部門基本上變為軟件了。當然,這不是說公司將只變為軟件(即使在最以軟件為中心的公司中還是有很多人的),只是整個業務在用軟件定義過程。
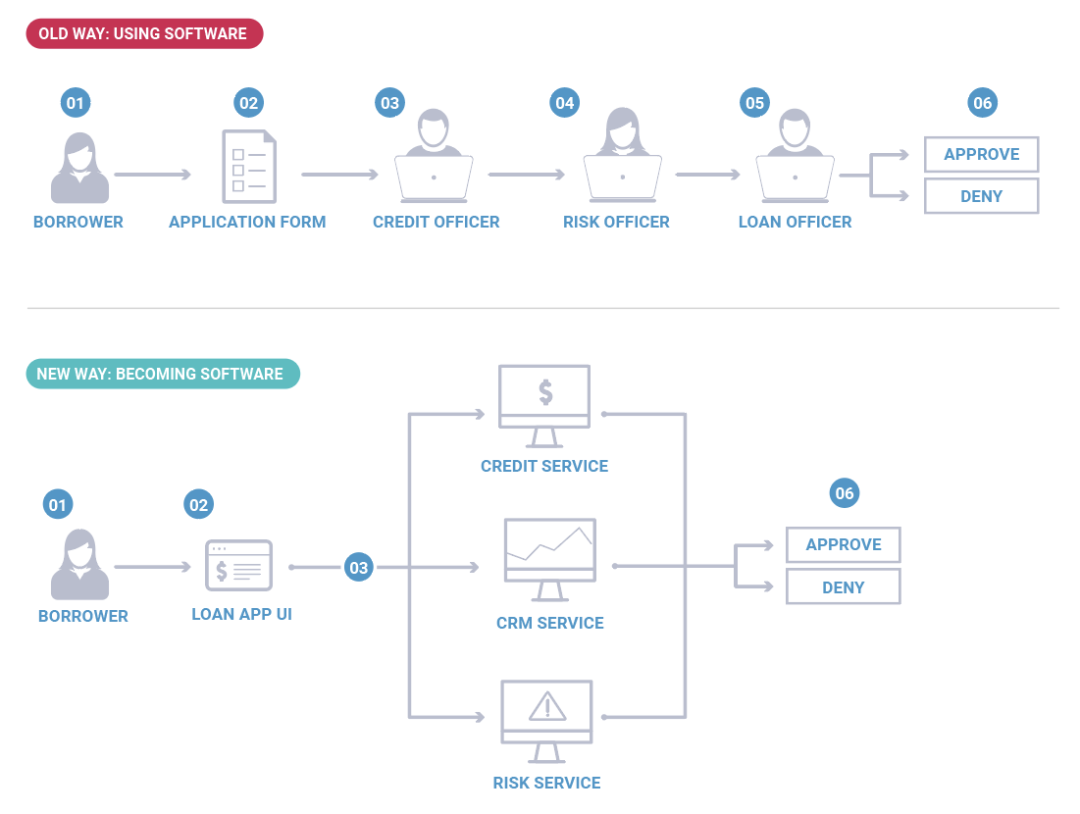
企業不只是把軟件用作人工流程生產力的輔助手段,他們正在用代碼構建整個業務部分。
這個轉變具有很多重要的意義,但是,我關注的是,這對軟件本身的角色和設計有什么意義。在這個新興的世界上,應用程序的目的不太可能是為 UI 提供服務來幫助人們開展業務,更可能的是觸發操作或對軟件的其他部分作出反應以直接開展業務。盡管這很容易理解,但是,它引發了一個大問題。
傳統的數據庫架構是否適合這個新興的世界?
畢竟,數據庫一直是應用程序開發中最成功的基礎結構層。然而,所有的數據庫,從最完善的關系數據庫到最新的鍵值存儲,都遵循一種范式,在該范式中,數據是被動存儲的,數據庫等待命令對它進行檢索或修改。被遺忘的是,這種范式的興起是由一種特定類型的面向用戶的應用程序來驅動的,在這種應用程序中,用戶可以查看 UI 并啟動將其轉換為數據庫查詢的操作。在我們上面提到的例子中,很顯然構建了一個關系數據庫以支持有助于在這為期 1 到 2 周的貸款批準流程中人為因素的應用程序,但是,是否適合把包括實時貸款批準流程在內的全套軟件組合在一起,而該實時貸款批準流程是基于不斷變化的數據進行持持續查詢而建立的?
實際上,值得注意的是,隨著 RDBMS(CRM、HRIS、ERP 等等)的興起,所有的應用程序都是在軟件時代作為人類生產力輔助工具出現的。CRM 應用程序使銷售團隊更有效率,HRIS 讓 HR 團隊更有效率等等。這些應用程序都是軟件工程師所謂的“CRUD”應用程序。它們幫助用戶創建、更新及刪除數據庫記錄,并在該流程上管理業務邏輯。這其中固有的假設是,在網絡的另一端有人在驅動和執行該業務過程。這些應用程序的目標是給人們看一些東西(他們會查看結果),給應用程序輸入更多的數據。
該模式與公司采用軟件的方式相匹配:一點一點地增加由人執行的組織和過程。但是,數據基礎設施本身并不知道如何互連或對公司內部其他地方發生的事情做出反應。這導致產生了圍繞數據庫構建的所有類型的解決方案,其中包括集成層、ETL 產品、消息傳遞系統,以及大量代碼,這些代碼是大規模軟件集成的標志。
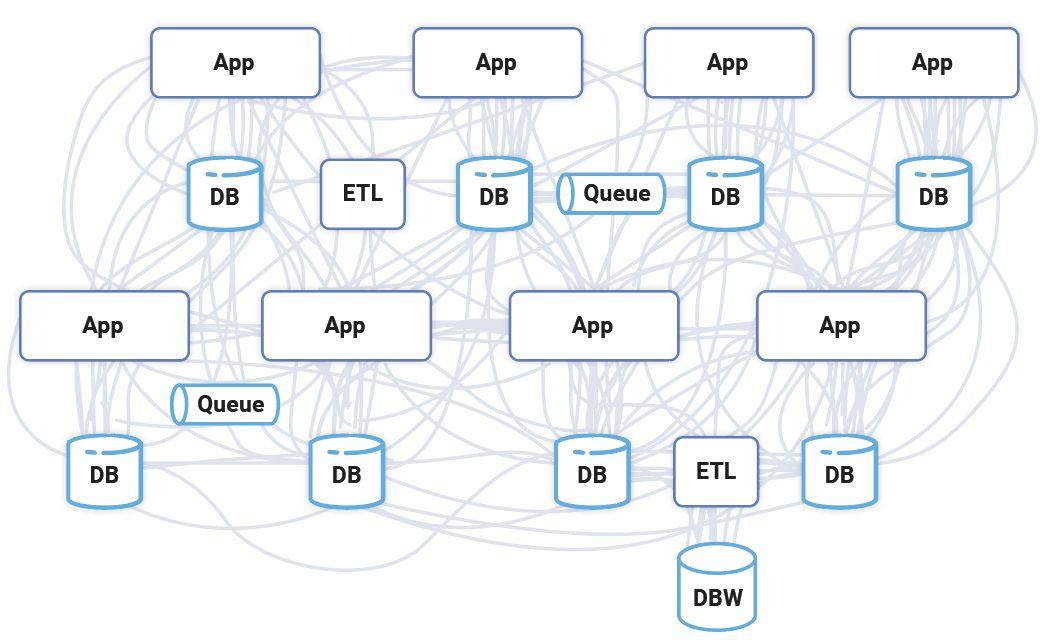
由于數據庫沒有為數據流建模,因此,公司內部系統之間的互連是一團亂麻。
事件流的興起
當軟件的主要角色不是為 UI 提供服務,而是直接觸發操作或對軟件的其他部分做出反應時,那么,我們的數據平臺需要什么新功能呢?
我認為,要從事件和事件流的概念開始來回答這個問題。什么是事件?發生的任何事情,包括用戶登錄嘗試、購買行為、價格的變化等等。什么是事件流?一系列不斷更新的事件,代表了過去發生的事情和現在正在發生的事情。
事件流為傳統數據庫的數據提供了一種非常不同的思考范式。基于事件構建的系統不再被動地存儲數據集和等待來自 UI 驅動的應用程序的命令。與之相反,它的設計目的是支持貫穿整個業務中的數據流以及實時響應和處理發生在業務中的每個事件的反應。這似乎與數據庫的領域相去甚遠,但是,我認為,數據庫的一般概念對未來的發展來說過于狹隘。
Apache Kafka 及其用途
通過分享我自己的背景知識,我將概述一些事件用例。Confluent 的創始人最初在 LinkedIn 工作的時候創建了這個開源項目 Apache Kafka,近年來,Kafka 已經成為事件流運動的基礎技術。我們的動機很簡單:盡管 LinkedIn 所有的數據是通過一天 24 小時永不停止的流程不斷生成的,但是,利用這些數據的基礎設施限于每天結束時緩慢的大型批處理數據轉儲和簡單的查找。“一天結束后的批處理”概念似乎是過去穿孔卡片和大型機時代的遺產。事實上,對于一個全球性的企業來說,每天沒有結束的概念。
很顯然,當我們投入這個挑戰時,這個問題沒有現成的解決方案。此外,在構建了支持實時網站的 NoSQL 后,我們知道,分布式系統研究和技術的復興為我們提供了一套工具,以過去不可能的方式來解決這個問題。我們注意到“流處理”的學術文獻,流處理是一個研究領域,可以把數據庫的存儲和數據處理技術擴展到靜態表之外,并把它們應用于這類持續、永不停息的數據流,這種數據流是像 LinkedIn 那樣的數字業務的核心。
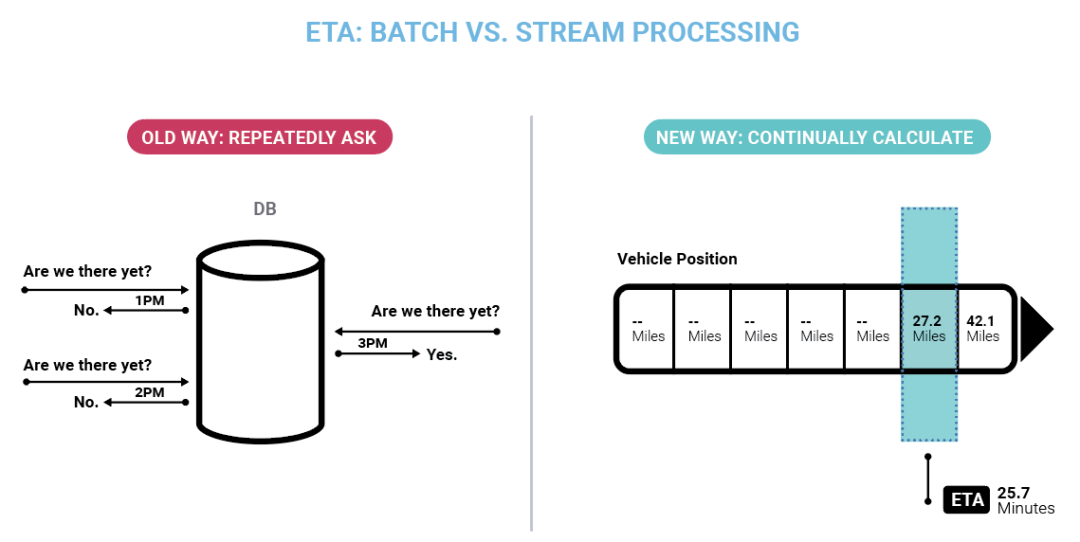
我們都熟悉這個古老的問題:“我們到了嗎?”傳統數據庫有點像個孩子,要回答這個問題除了不斷詢問,別無選擇。借助流處理,ETA 變成一個連續的計算,總是和問題的位置保持同步。
在社交網絡中,一個事件可以代表一次點擊、一封電郵、一次登錄、一個新的連接,或者一次個人資料的更新。把這些數據作為不斷發生的流來對待,可以讓 LinkedIn 所有的其他系統都可以訪問這些數據。
我們的早期用例涉及為 LinkedIn 的社交圖片、搜索、Hadoop、數據倉庫環境,以及像推薦系統、新聞提要、廣告系統的面向用戶的應用程序及其他產品功能提供填充數據。隨著時間的流逝,Kafka 的使用擴展到安全系統、低級應用程序監控、電郵、新聞提要以及數以百計的其他應用程序。這些都發生在這樣一個大規模要求的背景下:每天都有數以萬億計的消息流經 Kafka,并且數以千計的工程師圍繞著它工作。
在我們開源 Kafka 后,它在 LinkedIn 外開始了廣泛的傳播,在 Netflix、Uber、Pinterest、Twitter、Airbnb 等公司出現了類似的架構。
隨著我于 2014 年離開 LinkedIn,創辦了 Confluent 后,Kafka 和事件流已經開始引起硅谷科技公司以外的廣泛關注,并從簡單數據管道轉變為直接為實時應用程序提供支持。
如今,全球最大的銀行中有一些把 Kafka 和 Confluent 用于欺詐檢測、支付系統、風險系統和微服務架構。Kafka 是 Euronext 下一代證券交易平臺的核心,用于處理歐洲市場數十億筆交易。
在零售行業,Walmart、Target 和 Nordstrom 等公司已經采用了 Kafka。項目包括實時庫存管理,另外還有電子商務和實體設施的整合。零售業傳統上建立于每日緩慢的批處理的基礎之上,但是,來自電子商務的競爭已經推動了一體化和實時化。
包括 Tesla 和 Audi 在內的多家汽車公司已經為其下一代聯網的汽車構建了物聯網平臺,把汽車數據建模為實時事件流。他們并不是唯一這么做的。火車、船舶、倉儲和重型機械也都開始在事件流中捕獲數據了。
從硅谷開始的現象現在成了主流,成千上萬的組織都在使用 Kafka,其中包括 60% 的財富 100 強公司。
事件流作為中樞神經系統
這些公司中的大多數最初采用 Kafka 是為了一個特定用例啟用單個可擴展的實時應用程序或數據管道。這種最初的用法往往可以在公司內部迅速傳播到其他應用程序。
這種迅速傳播的原因是,事件流都是有多個讀者的:一個事件流可以有任意數量的“訂閱者”,可以對它進行處理、做出反應或回復。
以零售業為例,零售商可能首先捕獲單個用例在商店中發生的銷售流,比如,加快倉庫管理。每個事件可能表示和一次銷售有關的數據:售出的商品、售出商品的商店等等。但是,盡管使用可能從單個應用程序開始,相同的銷售流對于定價、報告、折扣系統以及數十個其他用例至關重要的。實際上,在全球零售業務中,有數百個甚至數千個軟件系統管理著業務的核心流程,包括庫存管理、倉庫操作、發貨、價格變動、分析及采購。有多少個核心流程受產品銷售這個簡單事件的影響?答案是很多或大多數,因為銷售商品是零售行業中最基本的活動之一。
這是采用的良性循環。第一個應用程序帶來其關鍵數據流。新的應用程序加入平臺以訪問這些數據流,并帶來它們自己的數據流。數據流帶來應用程序,而應用程序又帶來更多的數據流。
其核心思想是,事件流可以作為已發生事件的記錄加以處理,并且,任何系統或應用程序都可以實時利用它來對數據流做出反應、響應或進行處理。
這有著非常重要的意義。在公司內部,通常是一團亂麻似的相互連接的系統,每個應用程序都臨時與另外一個連接。這是非常昂貴耗時的方法。事件流提供了一種替代方法:可以有一個中央平臺,支持實時處理、查詢和計算。每個應用程序都可以發布與其業務部分相關的流,并以完全解耦的方式依賴其他流。
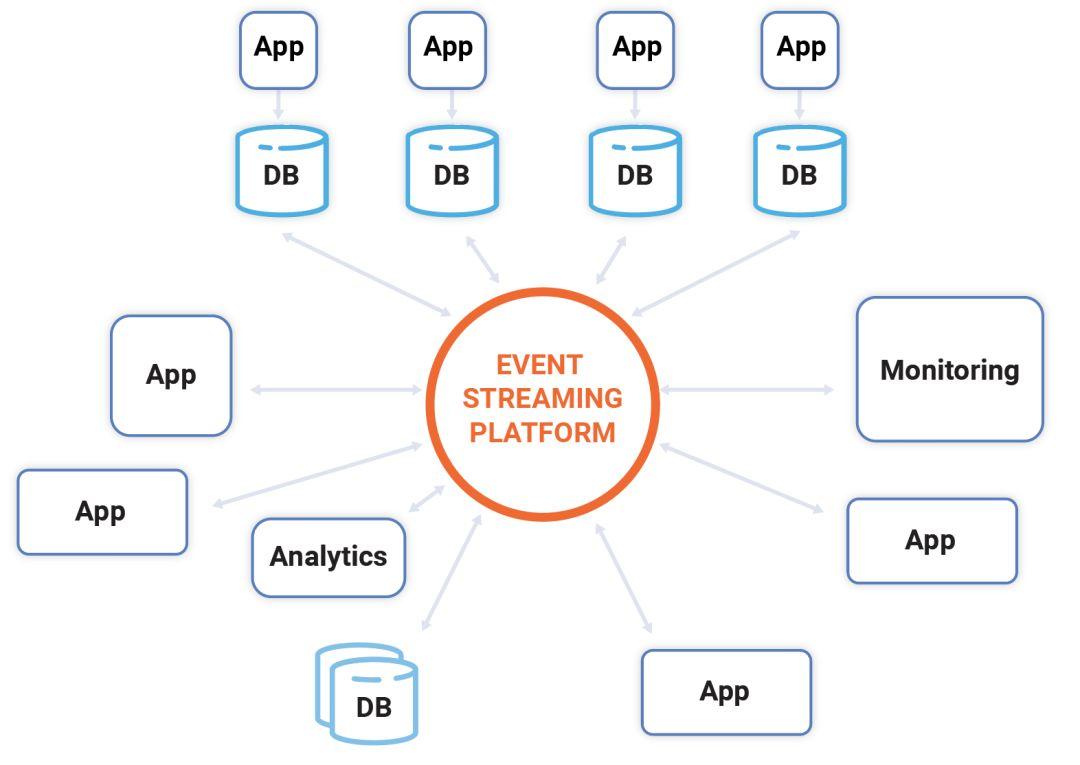
為了驅動內部連接,事件流平臺充當新興軟件定義的公司的中樞神經系統。我們可以把單獨的、以 UI 為中心、離線的應用程序看作一種軟件世界的單細胞生物。通過很多這類單細胞動物的簡單堆疊不可能形成一個綜合的數字公司,就像一條狗不能從一堆沒有差異的阿米巴變形蟲中創造出來一樣。一個多細胞動物有神經系統,協調所有單個細胞成為一個整體,可以對其在任何組成部分中所經歷的任何事情做出反應、計劃和即時行動。數字公司需要相當于這種神經系統的軟件,以連接其所有的系統、應用程序和流程。
這讓我們相信,這個新興的事件流平臺將會是現代企業中最具戰略意義的單一數據平臺。
事件流平臺:數據庫和數據流必須結合在一起
正確地做這件事不僅僅是管道膠帶公司為特別集成構建的生產問題。就現狀來說,這是不夠的,更別說新興的潮流了。所需的是實時數據平臺,可以把數據庫的全部存儲和查詢處理能力整合到一個現代的、水平可擴展的數據平臺中。
對這個平臺的需求不僅僅是對這些事件流進行讀寫。事件流不只是關于正在發生的事情短暫的、有損的數據噴射,它是對業務從過去到現在的過程中所發生事情的完整的、可靠的、持久的記錄。為了充分利用事件流,需要一個用于存儲、查詢、處理和轉換這些流的實時數據平臺,而不只是一個短暫的事件數據的“啞巴管道”。
把數據庫的存儲和處理能力與實時數據結合起來似乎有點古怪。如果我們把數據庫看作一種含有一大堆被動數據的容器,那么,事件流看起來離數據庫的領域還很遠。但是,流處理的想法顛覆了這一點。如果我們把在公司內部發生的任何東西的流看作“數據”,并允許持續“查詢”對它的處理、響應和反應,會發生什么事呢?這導致了根本不同的數據庫功能框架。
在傳統的數據庫中,數據是被動地放置的,等待應用程序或人來發出其要響應的查詢。在流處理中,這個過程倒過來了:數據是持續的,活動的事件流,饋送到被動的查詢中,該查詢只是對數據流做出反應和處理。
在某些方面,數據庫已經在內部設計中展示了其在表和事件流上的二元性,即使不是其外部特征也是如此。大多數數據庫都是圍繞提交日志構建的,提交日志充當數據修改事件的持久流。通常,這些日志僅僅是傳統數據庫中的實現細節,查詢無法訪問。然而,在事件流的世界,這些日志及其填充的表需要成為一等公民。
但是,集成這兩件事的理由不只是基于數據庫內部。基本上,應用程序是用存儲在表中的數據對世界上發生的事件做出反應 。在我們的零售示例中,銷售事件會影響庫存事件(數據庫表中的狀態),從而影響重新訂購事件(另一個事件!)。整個業務流程可以由這些應用程序和數據庫交互的菊花鏈形成,創建新事件的同時也改變這個世界的狀態(減少庫存數量,更新余額等等)。
傳統數據庫只支持這個問題的一半,剩下的一半嵌入應用程序代碼。KSQL 等現代流處理系統正在把這些抽象集合到一起,以開始完成數據庫需要跨事件和傳統存儲數據表進行的操作,但是,事件與數據庫的統一只是一個剛開始的運動。
Confluent 的使命
Confluent 的使命是構建這個事件流平臺,幫助企業圍繞這個事件流平臺開始重構自身。創始人和很多早期員工甚至在公司誕生之前就已經開始為這個項目工作了,并一直工作至今。
我們構建該平臺的方法是由下而上。通過幫助 Kafka 的核心可靠地進行大規模的存儲、讀寫事件流開始。然后,我們將堆棧移到連接器和 KSQL 上,讓事件流變得容易及易于使用,我們認為這對于構建新的主流開發范式是至關重要的。
我們已經在主要的公共云供應商以軟件產品和完全托管的云服務形式讓這個堆棧變得可用。這使事件流平臺可用跨越企業運營的整個環境,并在所有環境中集成數據和事件。
整個生態系統有大量機會在這個新的基礎設施上進行構建:從實時監控和分析,到物聯網、微服務、機器學習管道和架構,數據移動和集成。
隨著這個新的平臺和生態系統的興起,我們認為,它可以成為正在通過軟件定義和執行其業務的轉型公司的主要部分。隨著它成長為這個角色,我認為,無論是在其范圍還是戰略重要性上,事件流平臺將會和關系數據庫平起平坐。在 Confluent,我們的目標是使之實現。
作者介紹
Jay Kreps,Confluent 的首席執行官,也是 Apache Kafka 的聯合創始人之一。他曾是 LinkedIn 的資深架構師。