4 分鐘!OpenAI 的機器手學會單手解魔方了,完全自學無需編程
OpenAI 的機器手學會單手解魔方了,而且還原一個三階魔方全程只花了 4 分鐘,其靈巧程度讓人自嘆不如。
給你一個魔方,只允許使用一只手,還時不時有人給你搗亂,你能在 4 分鐘內還原它嗎?我不能,兩只手都不行。
OpenAI 的仿人機器手 Dactyl 做到了。現在它轉魔方的視頻被瘋狂刷屏,網友紛紛表示:人工智能機器人的一個新里程碑誕生了!這是機器人在機體靈活性以及機器學習軟件方面的飛躍!

視頻中我們看到,這只機器手雖然動作看起來有點笨拙,讓人老是懸著一顆心仿佛魔方時刻都可能掉下來,但每一步動作最終都非常準確。

視頻的后半部分研究人員加大了難度:用布遮擋、使用工具干擾,機器手依然在忘我的玩著魔方。

對于一個成年人來說,單手操控三階魔方其實也不是一件容易的事情。而一只機器手能夠達成這樣的成就,真的讓人印象深刻!
MIT 著名機器人專家和教授 Leslie Kaelbling 表示根本沒想到它居然能夠完成這項操作!密歇根大學機器操控專家 Dmitry Berenson 對此也給予肯定,并大加贊揚。
OpenAI 訓練類人機器手來解魔方的嘗試,早在 2017 年 5 月就開始了。之所以對解魔方情有獨鐘,是因為研究人員認為,如果能成功訓練這樣一只機器手來完成復雜的操作任務,就能為通用型機器人奠定基礎。在 2017 年 7 月,OpenAI 在模擬環境中解決了魔方。但直到 2018 年 7 月,機器手解魔方仍然只能操作一個方塊。現在,這個目標終于達成,請觀看下面視頻,機器手在約 4 分鐘的時間里成功還原了一個三階魔方。
這是機器手解魔方的完整過程,視頻未經任何編輯單手解魔方對人類來說都是一項具有挑戰性的任務,孩子們需要幾年的時間才能掌握所需的靈活性。機器手也仍沒完美掌握,成功率只有 60%。
接下來,我們將詳細描述 OpenAI 機器手解魔方的方法。
一、單手解魔方:OpenAI 新算法能無限生成仿真環境
OpenAI 使用強化學習和 Kociemba 算法訓練神經網絡來模擬解決魔方問題。我們專注于一個機器目前難以掌握的問題:感知和靈巧的操作。因此,我們訓練神經網絡來實現由 Kociemba 算法生成的還原所需的旋轉和翻轉。

域隨機化使得僅在模擬中訓練的網絡可以轉移到真實的機器人上
任務中面臨的最大挑戰是在模擬環境中創建足夠多樣化的環境來捕捉真實世界的物理環境。對于像魔方和機器手這樣復雜的物體來說,很難測量和建模摩擦、彈性和動力學等因素,而僅靠domain randomization是不夠的。
為了克服這一問題,我們開發了一種新的方法,稱為自動域隨機化(Automatic Domain Randomization,ADR),該算法能夠無休止地在仿真中生成越來越困難的環境。
這樣,我們就不必對現實世界做一個精確的建模,而且在模擬中學習到的神經網絡可以遷移應用于現實世界。
ADR 從一個單一的、非隨機的環境開始,在該環境中,神經網絡學習解魔方。隨著神經網絡性能的提高并達到性能閾值,域隨機化的量也隨之增加。這使得任務更加困難,因為神經網絡現在必須學會將其推廣到更隨機的環境中。網絡不斷學習,直到再次超過性能閾值,然后更多隨機化,重復這個過程。
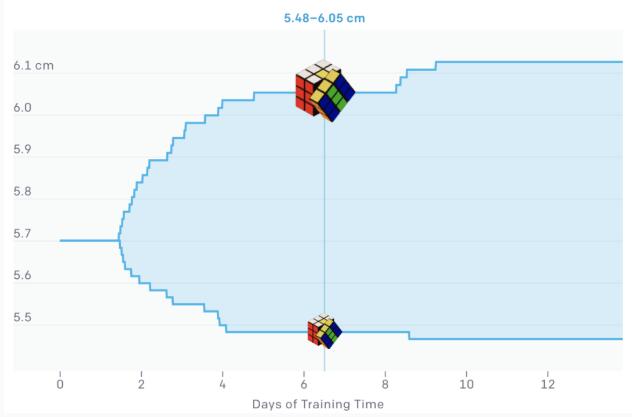
ADR 適應魔方的大小隨機化的參數之一是魔方的大小(上圖)
ADR 從一個固定大小的魔方開始,隨著訓練的進行,逐漸增加隨機化的范圍。我們將同樣的技術應用于所有其他參數,如魔方的重量、機器人手指的摩擦力和手的視覺表面材料等。因此,神經網絡必須學會在所有這些越來越困難的條件下解魔方。
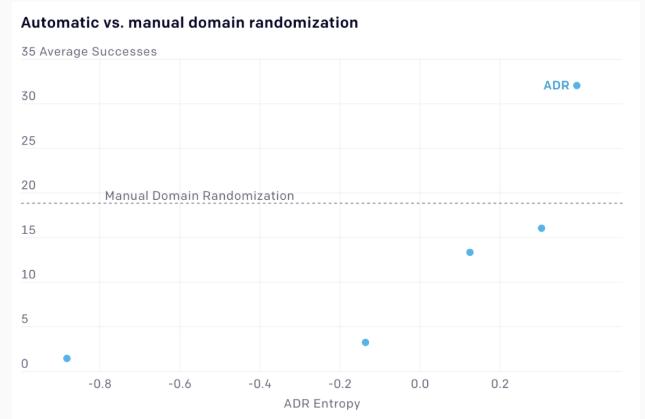
自動與手動的域隨機化
Domain randomization 要求我們手動指定隨機化范圍,這很困難,因為太多的隨機化會使學習變得困難,但太少的隨機化則會阻礙遷移到真正的機器人。ADR 通過自動擴展隨時間變化的隨機范圍來解決這個問題,不需要人工干預。ADR 消除了對領域知識的需求,使我們的方法更容易應用于新任務。與手動域隨機化相比,ADR 還使任務始終具有挑戰性,訓練從不收斂。
在魔方塊翻轉任務中,我們將 ADR 與手動域隨機化進行了比較,這個任務已經有了一個強大的基線。在開始階段,ADR 在真實機器人上的成功次數較少。但隨著 ADR 增大熵值(熵值是環境復雜性的度量),性能最終會比基線性能翻倍,無需人工調整。
穩健性測試
利用 ADR,我們能夠在仿真環境中訓練神經網絡,再用到真實機器手上解魔方。這是因為 ADR 將網絡暴露于無窮無盡的隨機模擬中。正是由于訓練過程中的這種復雜性,使網絡可以從模擬世界轉移到現實世界,因為它必須學會快速識別和適應它所面對的任何物理世界。

機器手解魔方時對它施加干擾
為了測試我們的方法的局限性,我們在單手解魔方的時候做了各種各樣的干擾實驗。這不僅測試了我們控制網絡的穩健性,也測試了我們的視覺網絡,在這里我們用視覺網絡來估算魔方的位置和方向。
我們發現,我們用 ADR 訓練的系統對干擾的穩健性令人驚訝,盡管我們沒有對這些干擾條件進行過訓練:在所有干擾測試中,機器手都能成功地完成大多數翻轉和旋轉面,盡管性能沒有達到最佳。
元學習
我們認為,元學習,或 learning to learn,是構建通用系統的一個重要前提,因為元學習使它們能夠快速適應環境中不斷變化的條件。ADR 背后的假設是,一個記憶增強網絡與一個充分隨機化的環境相結合,導致了 emergent meta-learning,其中網絡實現了一個學習算法,允許自己快速調整其行為以適應其所部署的環境。
為了系統地測試這一點,我們測量了神經網絡在不同的擾動下(如重新設置網絡的內存、重新設置動態、或斷開一個關節)每次翻轉魔方(旋轉魔方使不同顏色的面朝上)成功的時間。我們在仿真環境進行這些實驗,這使我們能夠在一個受控的環境中進行超過 10000 次的性能測試。
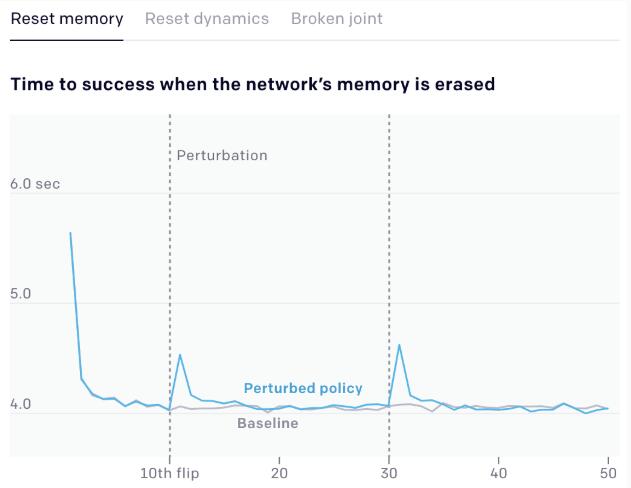
一開始,隨著神經網絡成功地完成更多的翻轉,每次連續成功的時間都在減少,因為神經網絡學會了適應。當施加干擾時(上圖中垂直的灰色線條),我們看到了成功時間的一個峰值。這是因為網絡采用的策略在變化的環境中不起作用。然后,網絡重新學習新的環境,我們再次看到成功的時間減少到先前的基線。
下圖是機器手在模擬環境中解魔方的可視化。
我們使用可解釋性工具箱中的一個構件,即非負矩陣分解,將這個高維向量壓縮成 6 組,并為每組分配一個獨特的顏色。然后在每一步中顯示當前主導組的顏色。
二、為什么說轉個魔方就稱得上實現了機器人技術的飛躍?
實際上會玩魔方的機器人并不只有 Dactyl 一個。那些專門被設計用來解魔方的機器人,甚至可以比 Dactyl 更快地處理三階、甚至更高階的魔方,那么為什么只有 Dactyl 獲得如此高的評價呢?
OpenAI 的研究科學家和機器人技術負責人彼得·韋林德(Peter Welinder)認為,原因就在于 Dactyl 不是專門用來玩魔方的!玩魔方只是一個 demo,而 Dactyl 最大的亮點在于“自學習”!
目前人工智能機器人之所以能夠在特定場景下超越人類,因為它是針對這個特定任務進行不斷的微調和優化后的結果,通過編程來盡可能高效地執行任務。但跳出機器人的“舒適區”后,它可能連人類的嬰兒都不如。
人工智能和機器人行業一直希望達成這樣的目標:制造一個機器人,它可以自己學會處理各種現實世界中的實際任務,而無需經過長時間的訓練或者有針對性的編程。是 Dactyl 讓他們看到了曙光!
Dactyl 擁有“自學習”特性,這意味著它能夠自動適應各種場景。OpenAI 希望有一天,只存在科幻電影里的經典機器人角色,能夠走出熒幕,走進千家萬戶,為人類提供服務。
OpenAI 團隊認為,Dactyl 此次成功解決魔方任務也印證了其可以在處理實際問題之前,通過仿真訓練學習新任務。