













有了GPT-4之后,機(jī)器人把轉(zhuǎn)筆、盤核桃都學(xué)會了
在學(xué)習(xí)方面,GPT-4 是一個厲害的學(xué)生。在消化了大量人類數(shù)據(jù)后,它掌握了各門知識,甚至在聊天中能給數(shù)學(xué)家陶哲軒帶來啟發(fā)。
與此同時,它也成為了一名優(yōu)秀的老師,而且不光是教書本知識,還能教機(jī)器人轉(zhuǎn)筆。

這個機(jī)器人名叫 Eureka,是來自英偉達(dá)、賓夕法尼亞大學(xué)、加州理工學(xué)院和得克薩斯大學(xué)奧斯汀分校的一項(xiàng)研究。這項(xiàng)研究結(jié)合了大型語言模型和強(qiáng)化學(xué)習(xí)的研究成果:用 GPT-4 來完善獎勵函數(shù),用強(qiáng)化學(xué)習(xí)來訓(xùn)練機(jī)器人控制器。
借助 GPT-4 寫代碼的能力,Eureka 擁有了出色的獎勵函數(shù)設(shè)計(jì)能力,它自主生成的獎勵在 83% 的任務(wù)中優(yōu)于人類專家的獎勵。這種能力可以讓機(jī)器人完成很多之前不容易完成的任務(wù),比如轉(zhuǎn)筆、打開抽屜和柜子、拋球接球和盤球、操作剪刀等。不過,這一切暫時都是在虛擬環(huán)境中完成的。



此外,Eureka 還實(shí)現(xiàn)了一種新型的 in-context RLHF,它能夠?qū)⑷祟惒僮鲉T的自然語言反饋納入其中,以引導(dǎo)和對齊獎勵函數(shù)。它可以為機(jī)器人工程師提供強(qiáng)大的輔助功能,幫助工程師設(shè)計(jì)復(fù)雜的運(yùn)動行為。英偉達(dá)高級 AI 科學(xué)家 Jim Fan 也是該論文的作者之一,他將這項(xiàng)研究比喻為「物理模擬器 API 空間中的旅行者號(美國研制并建造的外層星系空間探測器)」。

值得一提的是,這項(xiàng)研究是完全開源的,開源地址如下:

- 論文鏈接:https://arxiv.org/pdf/2310.12931.pdf
- 項(xiàng)目鏈接:https://eureka-research.github.io/
- 代碼鏈接:https://github.com/eureka-research/Eureka
論文概覽
大型語言模型(LLM)在機(jī)器人任務(wù)的高級語義規(guī)劃方面表現(xiàn)出色(比如谷歌的 SayCan、RT-2 機(jī)器人),但它們是否可以用于學(xué)習(xí)復(fù)雜的低級操作任務(wù),如轉(zhuǎn)筆,仍然是一個懸而未決的問題。現(xiàn)有的嘗試需要大量的領(lǐng)域?qū)I(yè)知識來構(gòu)建任務(wù)提示或只學(xué)習(xí)簡單的技能,遠(yuǎn)遠(yuǎn)達(dá)不到人類水平的靈活性。

谷歌的 RT-2 機(jī)器人。
另一方面,強(qiáng)化學(xué)習(xí)(RL)在靈活性以及其他許多方面取得了令人印象深刻的成果(比如 OpenAI 會玩魔方的機(jī)械手),但需要人類設(shè)計(jì)師仔細(xì)構(gòu)建獎勵函數(shù),準(zhǔn)確地編纂并提供所需行為的學(xué)習(xí)信號。由于許多現(xiàn)實(shí)世界的強(qiáng)化學(xué)習(xí)任務(wù)只提供難以用于學(xué)習(xí)的稀疏獎勵,因此在實(shí)踐中需要獎勵塑造(reward shaping),以提供漸進(jìn)的學(xué)習(xí)信號。盡管獎勵函數(shù)非常重要,但眾所周知,它很難設(shè)計(jì)。最近的一項(xiàng)調(diào)查發(fā)現(xiàn),92% 的強(qiáng)化學(xué)習(xí)受訪研究人員和從業(yè)者表示,他們在設(shè)計(jì)獎勵時進(jìn)行了人工試錯,89% 的人表示他們設(shè)計(jì)的獎勵是次優(yōu)的,會導(dǎo)致非預(yù)期行為。
鑒于獎勵設(shè)計(jì)如此重要,我們不禁要問,是否有可能利用最先進(jìn)的編碼 LLM(如 GPT-4)來開發(fā)一種通用的獎勵編程算法?這些 LLM 在代碼編寫、零樣本生成以及 in-context learning 等方面表現(xiàn)出色,曾經(jīng)大大提升了編程智能體的性能。理想情況下,這種獎勵設(shè)計(jì)算法應(yīng)具有人類水平的獎勵生成能力,可擴(kuò)展到廣泛的任務(wù)范圍,在沒有人類監(jiān)督的情況下自動完成乏味的試錯過程,同時與人類監(jiān)督兼容,以確保安全性和一致性。
這篇論文提出了一種由 LLM 驅(qū)動的獎勵設(shè)計(jì)算法 EUREKA(全稱是 Evolution-driven Universal REward Kit for Agent)。該算法達(dá)成了以下成就:
1、在 29 種不同的開源 RL 環(huán)境中,獎勵設(shè)計(jì)的性能達(dá)到了人類水平,這些環(huán)境包括 10 種不同的機(jī)器人形態(tài)(四足機(jī)器人、四旋翼機(jī)器人、雙足機(jī)器人、機(jī)械手以及幾種靈巧手,見圖 1。在沒有任何特定任務(wù)提示或獎勵模板的情況下,EUREKA 自主生成的獎勵在 83% 的任務(wù)中優(yōu)于人類專家的獎勵,并實(shí)現(xiàn)了 52% 的平均歸一化改進(jìn)。

2、解決了以前無法通過人工獎勵工程實(shí)現(xiàn)的靈巧操作任務(wù)。以轉(zhuǎn)筆問題為例,在這種情況下,一只有五根手指的手需要按照預(yù)先設(shè)定的旋轉(zhuǎn)配置快速旋轉(zhuǎn)鋼筆,并盡可能多地旋轉(zhuǎn)幾個周期。通過將 EUREKA 與課程學(xué)習(xí)相結(jié)合,研究者首次在模擬擬人「Shadow Hand」上演示了快速轉(zhuǎn)筆的操作(見圖 1 底部)。
3、為基于人類反饋的強(qiáng)化學(xué)習(xí)(RLHF)提供了一種新的無梯度上下文學(xué)習(xí)方法,可以基于各種形式的人類輸入生成更高效、與人類對齊程度更高的獎勵函數(shù)。論文表明,EUREKA 可以從現(xiàn)有的人類獎勵函數(shù)中獲益并加以改進(jìn)。同樣,研究者還展示了 EUREKA 利用人類文本反饋來輔助設(shè)計(jì)獎勵函數(shù)的能力,這有助于捕捉到人類的細(xì)微偏好。
與之前使用 LLM 輔助獎勵設(shè)計(jì)的 L2R 工作不同,EUREKA 完全沒有特定任務(wù)提示、獎勵模板以及少量示例。在實(shí)驗(yàn)中,EUREKA 的表現(xiàn)明顯優(yōu)于 L2R,這得益于它能夠生成和完善自由形式、表達(dá)能力強(qiáng)的獎勵程序。
EUREKA 的通用性得益于三個關(guān)鍵的算法設(shè)計(jì)選擇:將環(huán)境作為上下文、進(jìn)化搜索和獎勵反思(reward reflection)。
首先,通過將環(huán)境源代碼作為上下文,EUREKA 可以從主干編碼 LLM(GPT-4)中零樣本生成可執(zhí)行的獎勵函數(shù)。然后,EUREKA 通過執(zhí)行進(jìn)化搜索,迭代地提出獎勵候選批次,并在 LLM 上下文窗口中精煉最有希望的獎勵,從而大大提高了獎勵的質(zhì)量。這種 in-context 的改進(jìn)通過獎勵反思來實(shí)現(xiàn),獎勵反思是基于策略訓(xùn)練統(tǒng)計(jì)數(shù)據(jù)的獎勵質(zhì)量文本總結(jié),可實(shí)現(xiàn)自動和有針對性的獎勵編輯。
圖 3 為 EUREKA 零樣本獎勵示例,以及優(yōu)化過程中積累的各項(xiàng)改進(jìn)。為了確保 EUREKA 能夠?qū)⑵洫剟钏阉鲾U(kuò)展到最大潛力,EUREKA 在 IsaacGym 上使用 GPU 加速的分布式強(qiáng)化學(xué)習(xí)來評估中間獎勵,這在策略學(xué)習(xí)速度上提供了高達(dá)三個數(shù)量級的提升,使 EUREKA 成為一個廣泛的算法,隨著計(jì)算量的增加而自然擴(kuò)展。

如圖 2 所示。研究者致力于開源所有提示、環(huán)境和生成的獎勵函數(shù),以促進(jìn)基于 LLM 的獎勵設(shè)計(jì)的進(jìn)一步研究。

方法介紹
EUREKA 可以自主的編寫?yīng)剟钏惴ǎ唧w是如何實(shí)現(xiàn)的,我們接著往下看。
EUREKA 由三個算法組件組成:1)將環(huán)境作為上下文,從而支持零樣本生成可執(zhí)行獎勵;2)進(jìn)化搜索,迭代地提出和完善獎勵候選;3)獎勵反思,支持細(xì)粒度的獎勵改進(jìn)。
環(huán)境作為上下文
本文建議直接提供原始環(huán)境代碼作為上下文。僅通過最少的指令,EUREKA 就可以在不同的環(huán)境中零樣本地生成獎勵。EUREKA 輸出示例如圖 3 所示。EUREKA 在提供的環(huán)境代碼中熟練地組合了現(xiàn)有的觀察變量 (例如,指尖位置),并產(chǎn)生了一個有效的獎勵代碼 —— 所有這些都沒有任何特定于環(huán)境的提示工程或獎勵模板。
然而,在第一次嘗試時,生成的獎勵可能并不總是可執(zhí)行的,即使它是可執(zhí)行的,也可能是次優(yōu)的。這就出現(xiàn)了一個疑問,即如何有效地克服單樣本獎勵生成的次優(yōu)性?

進(jìn)化搜索
接著,論文介紹了進(jìn)化搜索是如何解決上述提到的次優(yōu)解決方案等問題的。他們是這樣完善的,即在每次迭代中,EUREKA 對 LLM 的幾個獨(dú)立輸出進(jìn)行采樣(算法 1 中的第 5 行)。由于每次迭代(generations)都是獨(dú)立同分布的,這樣一來隨著樣本數(shù)量的增加,迭代中所有獎勵函數(shù)出現(xiàn)錯誤的概率呈指數(shù)下降。


獎勵反思
為了提供更復(fù)雜、更有針對性的獎勵分析,本文建議構(gòu)建自動反饋來總結(jié)文本中的策略訓(xùn)練動態(tài)。具體來說,考慮到 EUREKA 獎勵函數(shù)需要獎勵程序中的各個組件(例如圖 3 中的獎勵組件),因而本文在整個訓(xùn)練過程中跟蹤中間策略檢查點(diǎn)處所有獎勵組件的標(biāo)量值。
構(gòu)建這種獎勵反思過程雖然很簡單,但由于獎勵優(yōu)化算法存在依賴性,因而這種構(gòu)建方式就顯得很重要。也就是說,獎勵函數(shù)是否有效受到 RL 算法的特定選擇的影響,并且即使在給定超參數(shù)差異的相同優(yōu)化器下,相同的獎勵也可能表現(xiàn)得非常不同。通過詳細(xì)說明 RL 算法如何優(yōu)化各個獎勵組件,獎勵反思使 EUREKA 能夠產(chǎn)生更有針對性的獎勵編輯并合成獎勵函數(shù),從而更好地與固定 RL 算法協(xié)同。

實(shí)驗(yàn)
實(shí)驗(yàn)部分對 Eureka 進(jìn)行了全面的評估,包括生成獎勵函數(shù)的能力、解決新任務(wù)的能力以及對人類各種輸入的整合能力。
實(shí)驗(yàn)環(huán)境包括 10 個不同的機(jī)器人以及 29 個任務(wù),其中,這 29 個任務(wù)由 IsaacGym 模擬器實(shí)現(xiàn)。實(shí)驗(yàn)采用了 IsaacGym (Isaac) 的 9 個原始環(huán)境,涵蓋從四足、雙足、四旋翼、機(jī)械手到機(jī)器人的靈巧手的各種機(jī)器人形態(tài)。除此以外,本文還通過納入 Dexterity 基準(zhǔn)測試中的 20 項(xiàng)任務(wù)來確保評估的深度。

Eureka 可以產(chǎn)生超人類水平的獎勵函數(shù)。在 29 項(xiàng)任務(wù)中,Eureka 給出的獎勵函數(shù)在 83% 的任務(wù)上比專家編寫的獎勵表現(xiàn)得更好,平均提高了 52%。特別是,Eureka 在高維 Dexterity 基準(zhǔn)測試環(huán)境中實(shí)現(xiàn)了更大的收益。
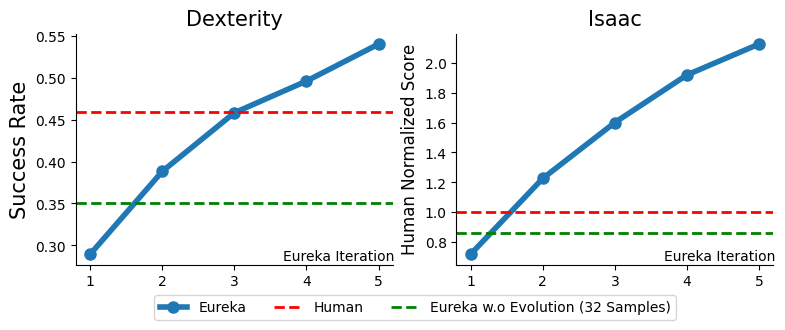
Eureka 能夠進(jìn)化獎勵搜索,使獎勵隨著時間的推移而不斷改善。Eureka 通過結(jié)合大規(guī)模的獎勵搜索和詳細(xì)的獎勵反思反饋,逐步產(chǎn)生更好的獎勵,最終超過人類的水平。
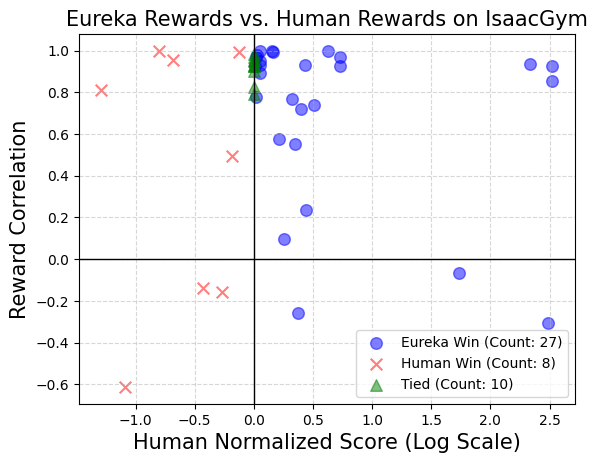
Eureka 還能產(chǎn)生新穎的獎勵。本文通過計(jì)算所有 Isaac 任務(wù)上的 Eureka 獎勵和人類獎勵之間的相關(guān)性來評估 Eureka 獎勵的新穎性。如圖所示,Eureka 主要生成弱相關(guān)的獎勵函數(shù),其表現(xiàn)優(yōu)于人類的獎勵函數(shù)。此外,本文還觀察到任務(wù)越難,Eureka 獎勵的相關(guān)性就越小。在某些情況下,Eureka 獎勵甚至與人類獎勵呈負(fù)相關(guān),但表現(xiàn)卻明顯優(yōu)于人類獎勵。

想要實(shí)現(xiàn)機(jī)器人的靈巧手能夠不停的轉(zhuǎn)筆,需要操作程序有盡可能多的循環(huán)。本文通過以下方式解決此任務(wù):(1) 指導(dǎo) Eureka 生成獎勵函數(shù),用來將筆重新定向到隨機(jī)目標(biāo)配置,然后 (2) 使用 Eureka 獎勵微調(diào)此預(yù)訓(xùn)練策略以達(dá)到所需的筆序列 - 旋轉(zhuǎn)配置。如圖所示,Eureka 微調(diào)很快就適應(yīng)了策略,成功地連續(xù)旋轉(zhuǎn)了許多周期。相比之下,預(yù)訓(xùn)練或從頭開始學(xué)習(xí)的策略都無法完成單個周期的旋轉(zhuǎn)。
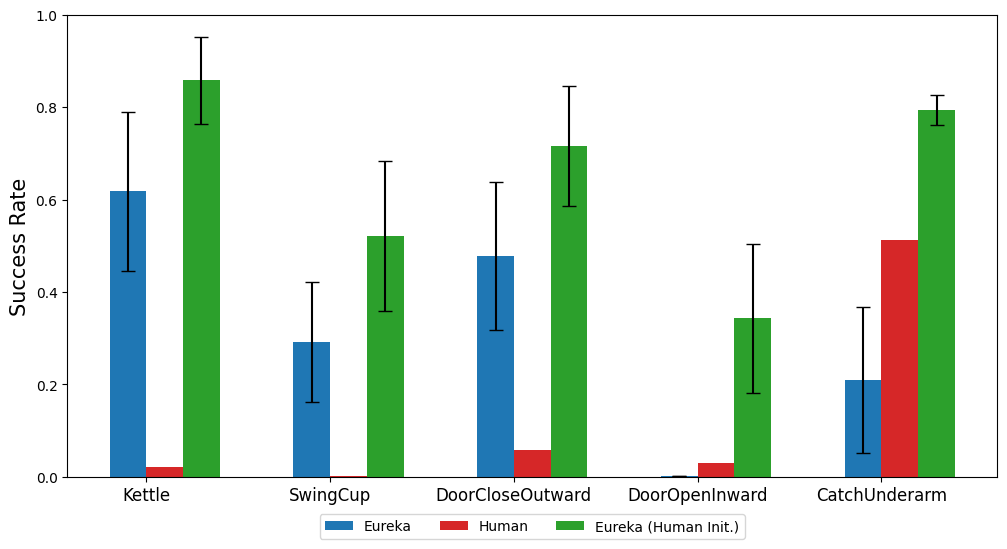
本文還研究了從人類獎勵函數(shù)初始化開始是否對 Eureka 有利。如圖所示,無論人類獎勵的質(zhì)量如何,Eureka 都會從人類獎勵中改進(jìn)并受益。

Eureka 還實(shí)現(xiàn)了 RLHF,其可以結(jié)合人類的反饋來修改獎勵,從而逐步指導(dǎo)智能體完成更安全、更符合人類的行為。示例展示了 Eureka 如何通過一些人類反饋來教人形機(jī)器人直立奔跑,這些反饋取代了之前的自動獎勵反思。

人形機(jī)器人通過 Eureka 學(xué)習(xí)跑步步態(tài)。
了解更多內(nèi)容,請參考原論文。




























