TimeSformer 是首個完全基于 Transformer 的視頻架構。近年來,Transformer 已成為自然語言處理(NLP)領域中許多應用的主導方法,包括機器翻譯、通用語言理解等。
TimeSformer 在一些具有挑戰性的動作識別基準(包括 Kinetics-400 動作識別數據集)上實現了最佳的性能。此外,與 3D 卷積神經網絡(CNN)相比,TimeSformer 的訓練速度大約快了 3 倍,而推斷所需的計算量不足其十分之一。
論文鏈接:
https://arxiv.org/pdf/2102.05095.pdf
此外,TimeSformer 的可擴展性使得在更長的視頻片段上訓練更大的模型成為可能。這為 AI 系統理解視頻中更復雜的人類行為打開了大門,對需要理解人類復雜行為的 AI 應用來說是極為有益的。
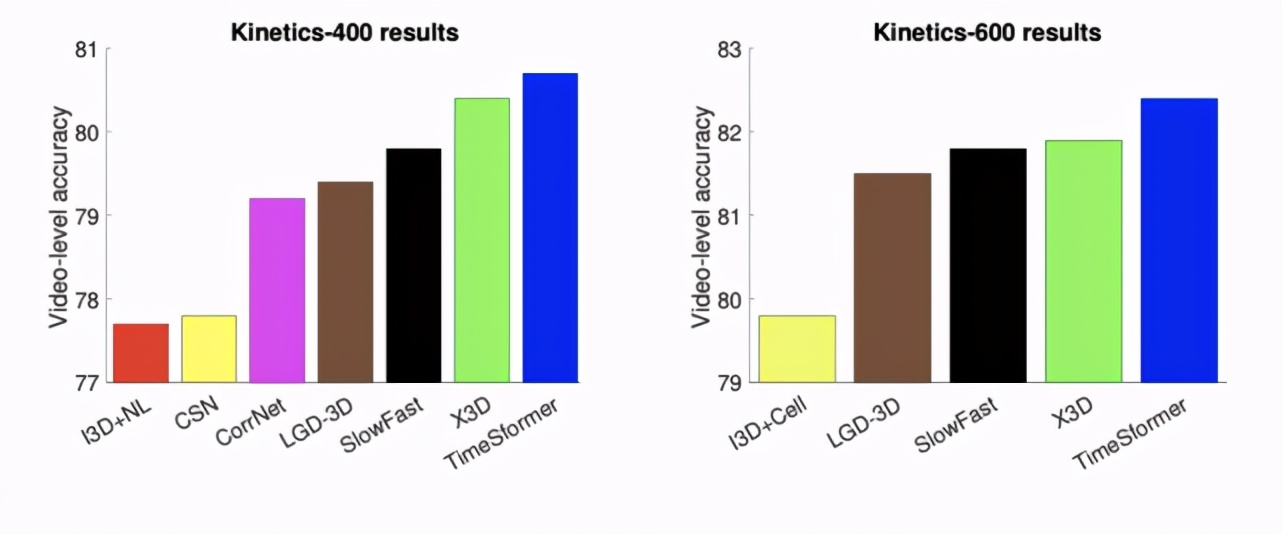
在 Kinetics-400(左) 和 Kinetics-600(右) 兩個動作識別基準上,TimeSformer 與當前具有 SOTA 性能的 3D 卷積神經網絡的視頻分類準確率比較結果。TimeSformer 在這兩個數據集上都達到了最優的準確率。
TimeSformer:全新的視頻理解架構
傳統的視頻分類模型利用了 3D 卷積濾波器。然而這樣的濾波器在捕獲局部時空區域內的短程模式方面是有效的,但是它們不能對超出其接受域的時空依賴關系進行建模。
TimeSformer 僅建立在 Transformer 模型中使用的自注意力機制上,這使得捕獲整個視頻的時空依賴關系成為可能。為了將 Transformer 應用到視頻中,該模型將輸入視頻解釋為從每個幀中提取的圖像 patch 的時間 - 空間序列。
這種格式類似于 NLP 中使用的格式,在 NLP 中,Transformer 將句子視為從每個單詞中計算出的特征向量序列。正如 NLP Transformer 通過將每個單詞與句子中的其他單詞進行比較來推斷其含義一樣,該模型通過顯式地將每個 patch 與視頻中的其他 patch 進行比較來捕獲每個 patch 的含義。這也是所謂的自注意力機制,這使得捕獲相鄰 patch 之間的短程依賴性以及遠距離 patch 之間的遠程關聯成為可能。
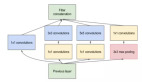
傳統的 3D 卷積神經網絡計算成本比較高昂,因為它們需要在視頻中所有的空間 - 時間位置上使用大量的濾波器。而 TimeSformer 具有較低的計算成本,因為它:(1)將視頻分解成一組不重疊的 patch;(2)采用自注意力,避免對所有 patch 對進行詳盡的比較。研究者將此方案稱為分割空間 - 時間注意力,其思想是依次應用時間注意力和空間注意力。
當使用時間注意力時,每個 patch(例如在下圖中,藍色的正方形)只與其他幀中相同空間位置的 patch(綠色正方形)進行比較。如果視頻包含 T 幀,則每個 patch 只進行 T 次時間上的比較。當使用空間注意力時,每個 patch 僅與同一幀內的 patch(紅色 patch)進行比較。
因此,如果 N 是每幀中的 patch 數,則分割空間 - 時間注意力只對每個 patch 執行一共(T+N)次比較,而不是聯合空間 - 時間注意力的方法所需的(T×N)次比較。此外,該研究發現與聯合空間 - 時間注意力相比,分割空間 - 時間注意力不僅更有效,而且更準確。

TimeSformer 的可擴展性讓它能夠在極長的片段(例如,102 秒時長的 96 幀序列)上運行,以執行超長程時間建模,這明顯不同于當前的 3D CNN。后者僅限于處理至多幾秒鐘的片段。而識別長時間活動是一種重要需求。
例如,假設有一個制作法式吐司的視頻。一次分析幾秒鐘的 AI 模型可能會識別出一些原子動作(例如打雞蛋或將牛奶倒入碗中)。但對每個單獨動作進行分類,對于分類復雜活動是遠遠不夠的。TimeSformer 則可以在更長的時間范圍內分析視頻,從而揭示出原子動作之間明確的依賴關系(例如將牛奶和已經打好的雞蛋混合)。
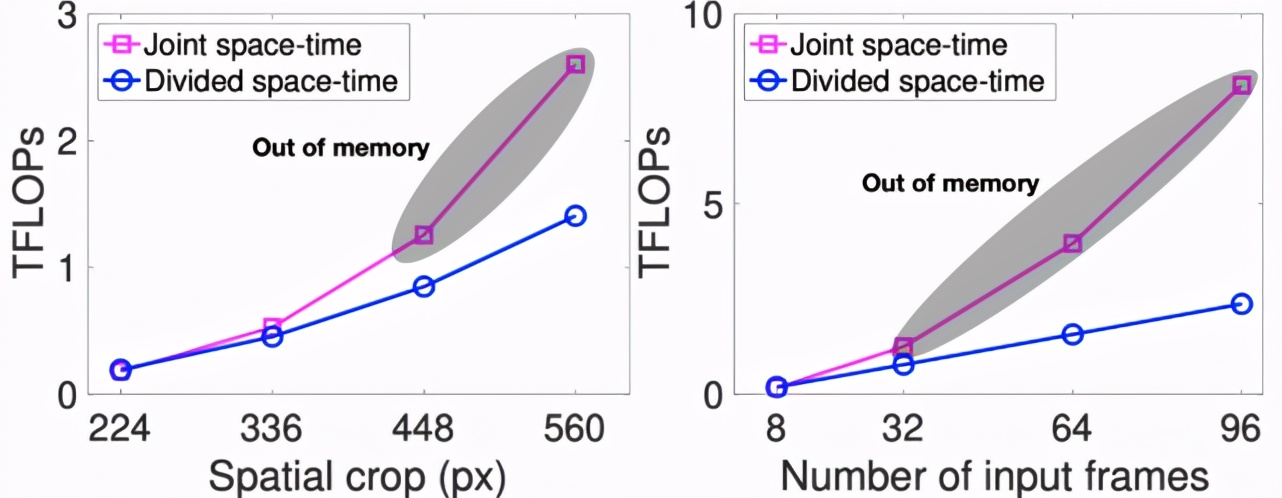
TimeSformer 的高效讓在高空間分辨率(例如高達 560x560 像素的幀)和長視頻(包括高達 96 幀)上訓練模型成為可能。

上圖展示了由 TimeSformer 學習的自注意力熱圖的可視化。第一行是原始幀,第二行通過自注意力給出的視頻分類重要性來加權每個像素的顏色(被認為不重要的像素會變暗)。TimeSformer 學習參與視頻中的相關區域,以執行復雜的時空推理。
促進更多領域的發展
為了訓練視頻理解模型,目前最好的 3D CNN 只能使用幾秒長的視頻片段。使用 TimeSformer 可以在更長的視頻片段(長達幾分鐘)上進行訓練。這可能會極大地促進研究工作,以教會機器理解視頻中復雜的長動作。對于許多旨在了解人類行為的 AI 應用程序(例如 AI 助手)而言,這是重要的一步。
此外,TimeSformer 的低推理成本是邁向未來實時視頻處理應用的重要一步,例如 AR/VR,以及為可穿戴攝像機視頻提供服務的智能助手。研究者相信該方法的成本降低將使更多的研究人員致力于解決視頻分析問題,從而加快該領域的研究進展。