













Python數據分析必知必會:TGI指數
這是Python數據分析實戰的第一個案例,詳細解讀TGI指數,并用Python代碼實現基礎的TGI偏好分析。
經常有一些專業的數據分析報告,會提到TGI指數,例如“基于某某TGI指數,我們發現某類用戶更偏好XX”。對于不熟悉TGI定義的同學,看到類似的話一定是云山霧罩。這次,我們就來聊一聊什么是TGI指數以及怎么樣結合案例數據實現簡單的TGI偏好分析。
內事不決網上搜,對于TGI指數,百科是這樣解釋的——TGI指數,全稱Target Group Index,可以反映目標群體在特定研究范圍內強勢或者弱勢。
很好,這個解釋官方中透漏著專業,專業中彌漫著晦澀,晦澀的讓人似懂非懂。粗暴翻譯下來,TGI指數是反應偏好的一種指標。這樣還是不夠清楚,我們結合公式理解一下。
TGI指數計算公式 = 目標群體中具有某一特征的群體所占比例 / 總體中具有相同特征的群體所占比例 * 標準數100
是不是更暈了?暈就對了!不暈我們還聊啥呢?
01 指標拆解
TGI計算公式中,有三個關鍵點需要進一步拆解:某一特征,總體,目標群體。
隨便舉個栗子,假設我們要研究A公司脫發TGI指數:
某一特征,就是我們想要分析的某種行為或者狀態,這里是脫發(或者說受脫發困擾)
總體,是我們研究的所有對象,即A公司所有人
目標群體,是總體中我們感興趣的一個分組,假設我們關注的分組是數據部,那目標群體就是數據部
于是乎,公式中分子“目標群體中具有某一特征的群體所占比例”可以理解為“數據部脫發人數占數據部的比例”,假設數據部有15個人,有9個人受脫發困擾,那數據部脫發人數占比就是9/15,等于60%。
而分母“總體中具有相同特征的群體所占比例”,等同于“全公司受脫發困擾人數占公司總人數的比例”,假設公司一共500人,有120人受脫發困擾,那這個比例是24%。
所以,數據部脫發TGI指數,可以用60% / 24% * 100 = 250,其他部門脫發TGI指數計算邏輯是一樣的,用本部門脫發人數占比 / 公司脫發人數占比 * 100即可。
TGI指數大于100,代表著某類用戶更具有相應的傾向或者偏好,數值越大則傾向和偏好越強;小于100,則說明該類用戶相關傾向較弱(和平均相比);而等于100則表示在平均水平。
剛才的例子中,我們瞎掰的數據部脫發TGI指數是250,遠遠高于100,看來搞數據的脫發風險極高,數據才是真正的發際線推手。
下面,我們通過一個案例來鞏固概念理解,順便和潘大師(Pandas)過過招。
02 TGI實例分析
項目背景
BOSS拋來一份訂單明細,“小Z啊,我們最近要推出一款客單比較高的產品,打算在一些城市先試銷,你看看這個數據,哪些城市的人有高客單偏好,幫我篩選5個吧”。
小Z趕緊打開表格,看看數據到底長什么樣子:
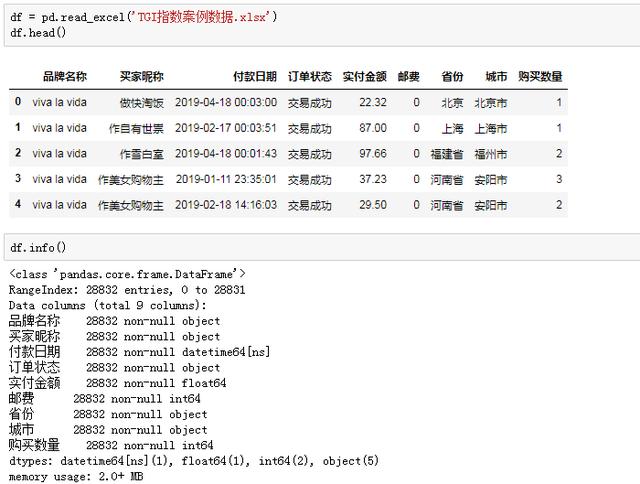
訂單數據包括品牌名、買家姓名、付款時間、訂單狀態和地域等字段,一共28832條數據,沒有空值。
粗略看了幾眼源數據,小Z趕緊明確數據需求:“領導,那客單比較高的定義是什么?”
“就我們產品線和歷史數據來看,單次購買大于50元就算高客單的客戶了”。
確認了高客單之后,我們的目標非常明確:按照高客單偏好給城市做個排序。這里的偏好,可以用TGI指數來衡量,我們再次復習下TGI三個核心點:
- 特征,高客單,即客戶單次購買超過50元
- 目標群體,就是各個城市,這里我們可以分別計算出所有城市客戶的高客單偏好
- 至于總體,就非常直白了,計算所涉及到的所有客戶即為總體
解題的關鍵在于,計算出不同城市,高客單人數及所占的比例。
單個用戶打標
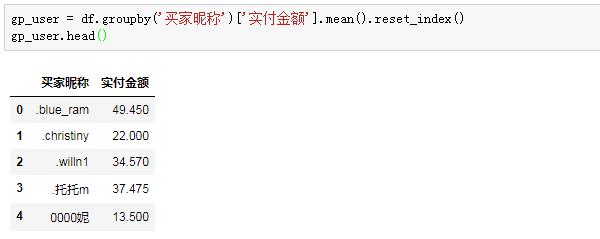
第一步,我們先判斷每個用戶是否屬于高客單的人群,所以先按用戶昵稱進行分組,看每位用戶的平均支付金額。這里用平均,是因為有的客戶多次購買,而每次下單金額也不一樣,故平均之。
接著,定義一個判斷函數,如果單個用戶平均支付金額大于50,就打上“高客單”的類別,否則為低客單,再用apply函數調用:
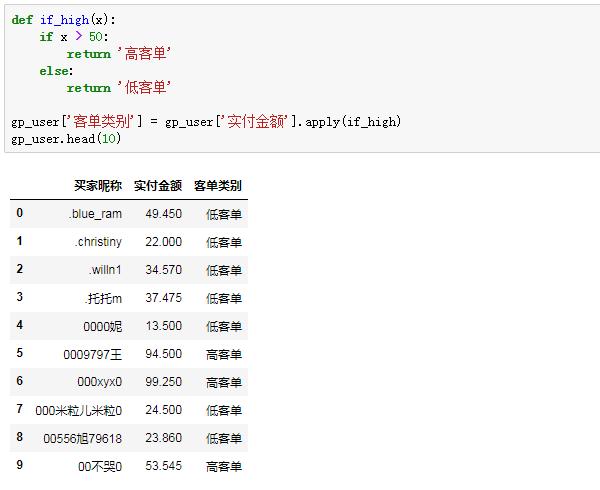
到這里基于高低客單的用戶初步打標已經完成。
匹配城市
單個用戶的金額和客單標簽已經搞定,下一步就是補充每個用戶的地域字段,一句pd.merge函數就能搞定。由于源數據是未去重的,我們得先按昵稱去重,不然匹配的結果會有許多重復的數據:
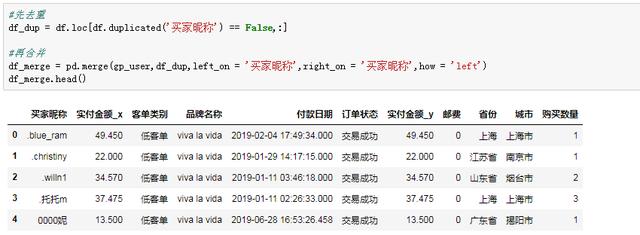
高客單TGI指數計算
要計算每個城市高客單TGI指數,需要得到每個城市高客單、低客單的人數分別是多少。如果用EXCEL的數據透視表處理起來就很簡單,直接把省份和城市拖拽到行的位置,客單類別拖到列的位置,值隨便選一個字段,只要是統計就好。
不要慌,這一套操作,Python實現起來也灰常容易,pivot_table透視表函數一行就搞定:
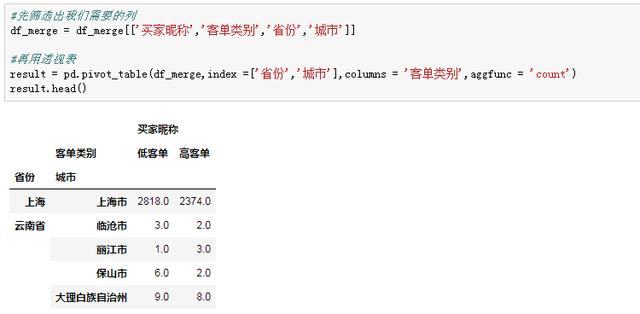
這樣得到的結果包含了層次化索引,受篇幅限制就不展開講,我們只要知道要索引得到“高客單”列,需要先索引“買家昵稱”,再索引“高客單”:
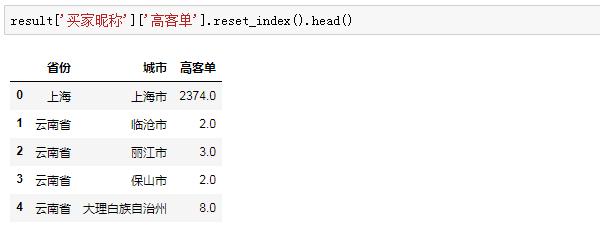
這樣,拿到了每個省市的高客單人數,然后再拿到低客單的人數,進行橫向合并:
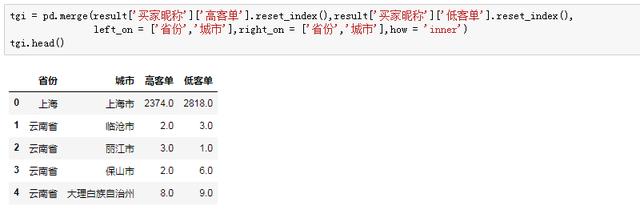
我們再看看每個城市總人數以及高客單人數占比,來完成“目標群體中具有某一特征的群體所占比例”這個分子的計算:
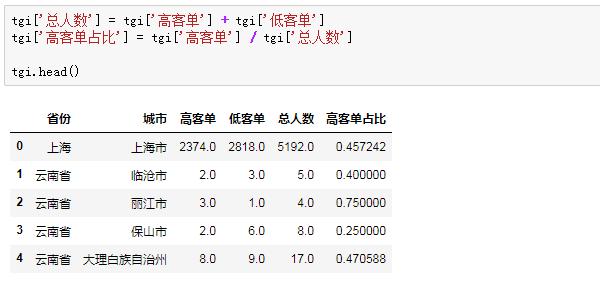
有些非常小眾的城市,高客單或者低客單人數等于1甚至沒有,而這些值尤其是空值會影響結果的計算,我們要提前檢核數據:
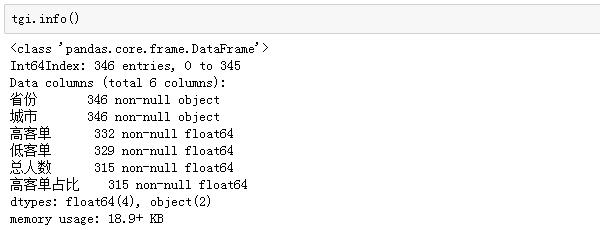
果然,高客單和低客單都有空值(可以理解為0),從而導致總人數也存在空值,而TGI指數對于空值來說意義不大,所以我們剔除掉存在空值的行:
接著統計總人數中,高客單人群的比例,來對標公式中的分母“總體中具有相同特征的群體所占比例”:

最后一步,就是TGI指數的計算,順便排個序:
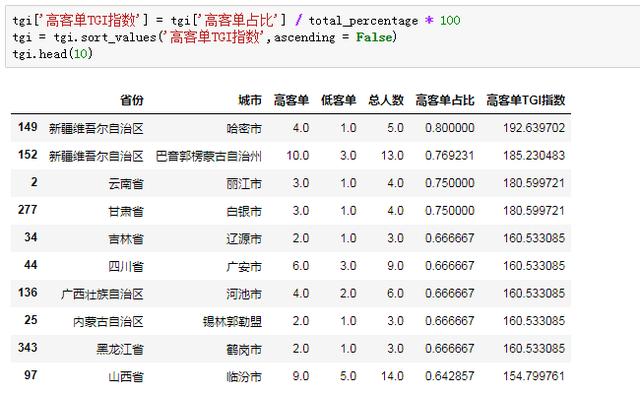
出了結果,小Z興致勃勃的打算第一時間報告老板,說時遲那時快,在按下回車之前又掃了一眼數據,發現了一個嚴重的問題:高客單TGI指數排名靠前的城市,總客戶數幾乎不超過10人,這樣的高客單人口占比,完全沒有說服力。
TGI指數能夠顯示偏好的強弱,但很容易讓人忽略具體的樣本量大小,這個是需要格外注意的。
怎么辦呢?為了加強數據整體的信度,小Z決定先對總人數進行篩選,用總人數的平均值作為閾值,只保留總人數大于平均值的城市:
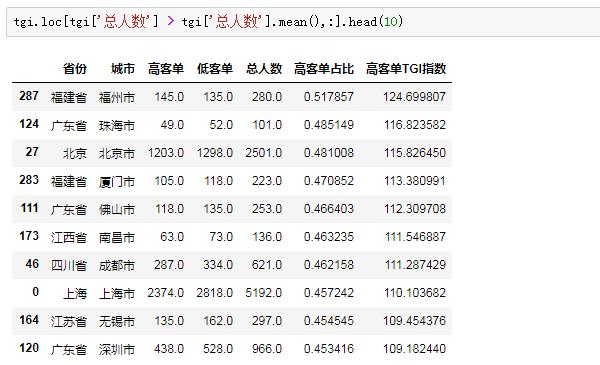
處理之后,小Z覺得這份數據合理多了。





















