













年入百萬數據科學家在線摸魚?
年薪百萬數據科學家
上班時間在線摸魚!?
怎么回事!
請聽小編為您分解
▼
近幾年
AI行業發展得如火如荼
數據科學家也跟著吃上了“香餑餑”
江湖傳言
剛畢業的AI博士起薪50W
2年經驗的薪水100W+
貌似一當上數據科學家
分分鐘就能實現財富自由
數據科學家是否
真的像傳言那般光鮮亮麗呢?
今天我們有幸采訪到了李博士
來看下數據科學家的工作狀態吧
離開熟悉的科研機構后,李博士被一家AI初創企業以七位數年薪收入麾下,擔任機器視覺部門的數據科學家。
上班第一周,熟悉了新環境和同事后,李博士連上公司分配的GPU服務器,開始一個圖像分割模型訓練。
啟動任務后,李博士沒有像人們想象地那樣開始在各種機器前忙碌,而是起身接了一杯咖啡,隨即悠悠然坐進軟椅,轉向論文研究工作。
咦?什么情況?數據科學家在線摸魚?
當然不是!
其實這也是李博士的無奈之舉,他痛心疾首地說道:“算力是AI發展的一大阻礙啊!”按照以往經驗,在當前CNN模型的復雜度和訓練數據量條件下,要3-4天才看得到訓練結果,結果出來之前除了等待別無他法。
這不禁讓我們聯想起90年代之前的大學,同學們先到計算中心排隊,然后將自己的應用程序輸到機房計算機中,此后要用相當長的時間來等待計算結果。

半個多世紀以來,摩爾定律讓計算性能取得了飛躍,現在一臺智能手機的計算能力,已經可以趕上80年代的超級計算機了。而今天,對計算力的渴望,我們和半個世紀以前的人們依然沒有什么區別。
AI領域的計算力渴望
2018年,OpenAI發布了一份關于AI計算能力增長趨勢的分析報告,報告顯示:自2012年以來,AI訓練中所使用的計算力每3.43個月增長一倍,過去6年時間里,這個指標已經增長了30萬倍以上——這便是OpenAI針對AI計算領域提出的新摩爾定律。
每當有數據科學家質疑AI計算平臺的性能時,從事計算工作的朋友們就會很委屈:沒有計算力上做出的成績,怎么會有這波AI應用的熱潮?如果沒有吳恩達2011年將GPU應用于谷歌大腦所取得的成功,人工智能的第三次熱潮恐怕還要晚幾年才能到來。
但是,AI就像是一個正在長身體的小寶寶,天天哭著找媽媽要奶吃。相較傳統的機器學習算法,深度學習對計算力的要求更高。
比如,2012年摘得ImageNet圖像分類大賽冠軍的AlexNet網絡,包含8層神經網絡,6000萬個參數;2015年奪冠的ResNet網絡,深度已經達到了152層;另外,一個圖像分類模型VGG-16,參數量也達到了1.38億;而現在有些語言識別模型,參數量已經超過10億!
為應對AI算力要求,當前國內AI基礎架構普遍采用的是Scale-up GPU架構,即在單臺服務器上部署4張、8張甚至更多張GPU卡,每個任務使用設備中的全部或者部分資源。這種架構的優點就是實施簡單,操作容易。
但是,隨著模型復雜度加深、計算力要求提高,單機多卡模式越來越力不從心。另外,一味增加單機GPU密度,也會加大數據中心的供電和散熱壓力,此時一旦出現服務器問題障,就很可能造成業務故障。
面對種種問題,難道AI算力再上一步發展的空間就沒有了嗎?
這里,我們還是要相信IT基礎架構建設者的智慧。在過去的2019年春天,可以看到國內AI計算領域有了很多不一樣的改變:精細化、集群化、多元化——三把“利劍”齊發力,AI計算正朝著人們所期望的高性能、可擴展模式邁進。
第一把利劍:精細化
精細化是指不改變現有計算架構,“深挖洞,廣積糧”,提高單個芯片計算性能,以達到更高的整體性能。
目前,僅僅依靠提高GPU的浮點計算和顯存帶寬指標來實現算力提升已經有些困難,大家開始嘗試降低AI訓練和推理過程中的精度要求。
例如,在Nvidia V100和T4上提供TensorCore混合精度特性,TensorCore讓最耗費計算性能的矩陣乘法在FP16半精度工作,矩陣加法和最終輸出結果仍可以在FP32工作。與經典的FP32單精度訓練相比,混合精度降低了對帶寬與顯存容量的需求,使訓練性能實現倍增。
同樣,在推理領域,Int8或其他低精度推理方式正在被更多數據科學家嘗試。深度學習端到端pipeline優化,可以平衡計算、存儲IO、網絡傳輸性能,使數據以更快速度流動和計算。
相關機制主要包含框架的多線程、預讀機制,NVME SSD小文件IO優化、PCI-Eswitch或NVLink提升參數同步網絡性能,以及使用GPU進行圖像數據預處理的新技術(DALI)等。
在這方面,戴爾易安信針對AI GPU計算專門設計的服務器C4140(1U機箱支持4塊全寬GPU)和DSS 8440(4U機箱支持10塊全寬GPU),集成了很多針對深度學習參數快速同步和小文件IO的硬件優化技術,可以為AI研究提供良好的算力支持。
戴爾易安信DSS 8440
雖然精細化可以讓芯片發揮最佳計算性能,不過單節點挖潛畢竟是有上限的,既然云計算、HPC、大數據等Scale-out模式如火如荼,是不是可以讓AI計算也插上集群計算的翅膀呢?
答案是肯定的。
第二把利劍:集群化
所謂集群化,就是讓更多處理器參與到計算加速中,以滿足深度學習對算力的需求。
當前主流的深度學習框架,像TensorFlow、PyTorch、MXNet、Caffe2等,均已提供對GPU集群分布式訓練的支持。當然,GPU分布式訓練比單機訓練要復雜,需要端到端設計來保證多機多卡訓練的性能。
如果把AI計算集群比作一輛汽車,加速芯片就相當于汽車的發動機,網絡如同傳統系統,存儲好比是汽車的油箱,而調度軟件就起著方向盤的作用。
每一個Batch訓練中,GPU都需要在極短的時間內完成億級別參數同步,對網絡帶寬和延遲要求極高。實踐證明,相比傳統的TCP/IP網絡傳輸,采用基于RDMA或者RoCE的GPU Direct computing技術,可以大幅有效地提升參數同步的網絡傳輸性能。
IO側,NLP、機器視覺和語音識別中,需要大量使用KB級小文件進行訓練,GPU處理速度又很快,集群環境將數據放到共享文件存儲系統中,因而對存儲系統小文件IO處理性能有著非常高的要求。
而Lots of small files的文件讀寫方式,恰恰是眾多存儲系統性能的“命門”。
依托多年非結構化數據存儲的經驗積累,戴爾易安信針對深度學習小文件性能優化,提供Isilon Scale-out NAS、Lustre并行文件系統、基于AI/HPC環境優化的NFS存儲系統(NSS)三個存儲利器,可滿足不同環境規模、容量和性能要求。

在2018年完成的一項測試中,以戴爾易安信Isilon F800全閃存存儲作為72塊Nvidia V100 32GB GPU集群的后端存儲,進行主流圖像分類模型訓練,這個測試中,GPU使用率可以達到97%,訓練數據放置于GPU服務器,本地SSD硬盤與共享存儲對訓練性能的影響只有2%,基本做到存儲性能無瓶頸。
此外,GPU分布式集群訓練中,除了更高性能的計算、存儲與網絡架構,如果能在軟件層面上做一些優化,比如優化GPU參數同步效率,那么軟硬結合將事半功倍。戴爾易安信將最新軟件優化機制與高性能基礎架構硬件結合,可以實現最好的分布式訓練性能。

例如,傳統TensorFlow分布式訓練,采用參數服務器機制,各個GPU通過數據同步訓練得到的參數,需要通過參數服務器進行參數同步,再分發到集群中各GPU。而網絡傳輸參數量大的時候,參數服務器會成為性能瓶頸。
Horovod則對TensorFlow參數同步機制進行了優化,取消參數服務器,改為Ring Allreduce方式,這種方式下,所有參與計算的N個GPU排成一個“握手環路”,將訓練參數分成N份,每一次GPU只與環中上一個和下一個GPU交換1/N的參數,通過N-1個時間周期完成全部交換。
實踐證明,RingAllreduce對傳輸帶寬的利用率最高。
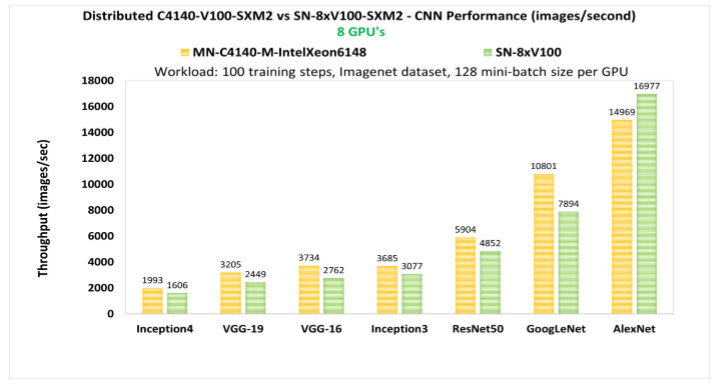
而更大規模的分布式訓練集群,32張V100構成的GPU集群,在MXNet框架下進行ResNet50圖像分類訓練,性能表現為單GPU卡性能的29.4倍;采用Caffe2框架,加速比為26.5倍。
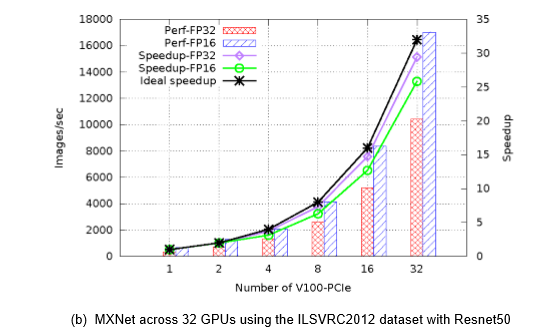
由此可見,在提高算力方面,集群化的功效非同一般。
第三把利劍:多元化
在同等算力要求下,芯片功耗也是AI研究中比較關注的地方。很多企業異構計算小組正在尋找更高性能或功耗更低的解決方案,目前,FPGA和ASIC是替代GPU的兩大熱門方向,AI異構加速也是戴爾易安信一直在研究的技術領域。
FPGA
FPGA采用硬件可編程邏輯門電路設計,具有豐富的可重配置的片上資源,運行時無需加載并解釋指令,具有高并發、低延遲、低功耗的優良特性。在嵌入式推理、云端高并發低延遲推理和視頻圖像預處理等AI領域,FPGA值得期待。
目前,戴爾易安信的計算解決方案可以支持Intel和Xilinx兩大主流FPGA加速方案。

不過,FPGA應用面臨的最大問題是開發難度,這需要工程師能夠比較熟練地掌握硬件描述語言HDL。這方面,戴爾易安信與Intel攜手,希望將2018年12月在重慶揭牌的FPGA中國創新中心,打造為加速FPGA人才培養與應用落地的基地。

ASIC
基于ASIC的AI專用芯片(如谷歌的TPU)也同樣備受關注。戴爾科技集團投資了一家AI芯片初創企業——Graphcore,Graphcore總部位于英國的,目前估值17億美金,其AI加速芯片IPU計劃于19年下半年上市。
Graphcore IPU加速卡,單張峰值性能250Tops,是Nvidia V100GPU的2倍。IPU采用同構多核架構,單片上提供2432個獨立的處理器;它大量采用片上SRAM而非傳統DRAM,參數權重存儲在處理器的高速緩存。

單臺戴爾易安信DSS 8440服務器,最多可以支持8張IPU加速卡。在早先進行的一些深度學習訓練和推理測試中,Graphcore IPU表現出了非常出色的性能:
如RNN領域最常使用的LSTM模型,IPU的訓練性能是Nvidia V100 GPU卡的10倍;LSTM推理,IPU吞吐量可以達到V100的100倍,延遲為1/10;CNN ResNet-50推理方面,IPU單卡性能可達到V100的25倍。

我們有理由相信,隨著AI計算精細化讓芯片發揮最佳計算性能,集群化讓更多處理器參與到計算加速,以及新一代更強大的AI芯片的商用,未來就緒的AI基礎架構有能力迎接AI計算新摩爾定律的挑戰。
未來,估計李博士喝咖啡品茶等待運算結果的時間將越來越短,這對李博士們而言是好事還是壞事?
大概率是好事吧!

















