時(shí)域音頻分離模型登GitHub熱榜,效果超傳統(tǒng)頻域方法
本文經(jīng)AI新媒體量子位(公眾號(hào)ID:QbitAI)授權(quán)轉(zhuǎn)載,轉(zhuǎn)載請(qǐng)聯(lián)系出處。
用AI對(duì)歌曲音軌的分離研究很多,不過(guò)大多數(shù)都是在頻域上進(jìn)行的。這類方法先把聲音進(jìn)行傅立葉變換,再?gòu)念l譜空間中把人聲、樂(lè)曲聲分別抽離出來(lái)。
比如,上個(gè)月在GitHub上大熱的Spleeter,就是這樣。
但是由于要計(jì)算頻譜,這類工具存在著延遲較長(zhǎng)的缺點(diǎn)。雖然之前也有一些對(duì)聲音波形進(jìn)行處理的方法,但實(shí)際效果與頻域處理方法相差甚遠(yuǎn)。
最近,F(xiàn)acebook AI研究院提供了兩種波形域方法的PyTorch實(shí)現(xiàn),分別是Demucs和Conv-Tasnet,而且測(cè)試結(jié)果均優(yōu)于其他常見(jiàn)的頻域方法,目前登上了GitHub日榜
效果對(duì)比
話不多說(shuō),我們先來(lái)聽(tīng)聽(tīng)這段30s音頻的分離實(shí)測(cè)效果。
vocals.mp3
00:30.069
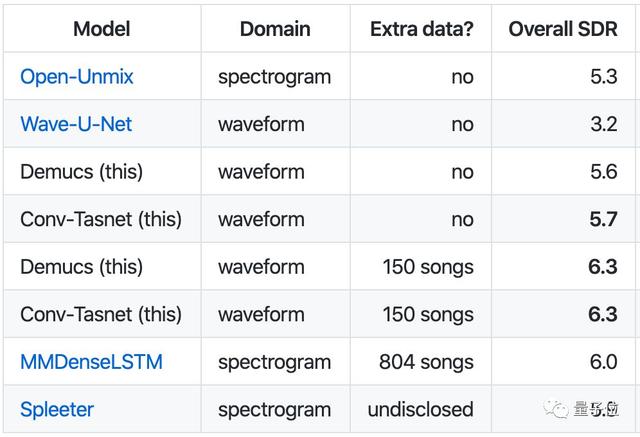
這兩種方法在MusDB上的訓(xùn)練結(jié)果已經(jīng)接近了頻域方法的最優(yōu)結(jié)果,加入150首額外的訓(xùn)練數(shù)據(jù)后,總體信號(hào)失真比(overall SDR)達(dá)到了6.3,超過(guò)了其他所有方法。
安裝與使用方法
先將代碼下載到本地,根據(jù)自己用CPU還是GPU來(lái)選擇不同的安裝環(huán)境:
- conda env update -f environment-cpu.yml # if you don’t have GPUs
- conda env update -f environment-cuda.yml # if you have GPUs
- conda activate demucs
在代碼庫(kù)的根目錄下運(yùn)行以下代碼(Windows用戶需將python3換為python.exe):
- python3 -m demucs.separate --dl -n demucs PATH_TO_AUDIO_FILE_1 [PATH_TO_AUDIO_FILE_2 ...] # for Demucs
- python3 -m demucs.separate --dl -n tasnet PATH_TO_AUDIO_FILE_1 ... # for Conv-Tasnet
- # Demucs with randomized equivariant stabilization (10x slower, suitable for GPU, 0.2 extra SDR)
- python3 -m demucs.separate --dl -n demucs --shifts=10 PATH_TO_AUDIO_FILE_1
其中—dl將自動(dòng)下載預(yù)訓(xùn)練模型,-n后的參數(shù)代表選用的預(yù)訓(xùn)練模型類型:
demucs:表示在MusDB上進(jìn)行訓(xùn)練的Demucs;
demucs_extra:使用額外數(shù)據(jù)訓(xùn)練的Demucs;
tasnet:表示在MusDB上進(jìn)行訓(xùn)練的Conv-Tasnet;
tasnet_extra:使用額外數(shù)據(jù)訓(xùn)練的Conv-Tasnet。
在—shifts=SHIFTS執(zhí)行多個(gè)預(yù)測(cè)與輸入和平均他們的隨機(jī)位移(又名隨機(jī)等變穩(wěn)定)。這使預(yù)測(cè)SHIFTS時(shí)間變慢,但將Demucs的精度提高了SDR的0.2點(diǎn)。它對(duì)Conv-Tasnet的影響有限,因?yàn)樵撃P捅举|(zhì)上幾乎是等時(shí)的。原始紙張使用10的值,盡管5產(chǎn)生的增益幾乎相同。默認(rèn)情況下禁用它。
原理簡(jiǎn)介
Demucs是Facebook人工智能研究院在今年9月提出的弱監(jiān)督訓(xùn)練模型,基于受Wave-U-Net和SING啟發(fā)的U-Net卷積架構(gòu)。
研究人員引入了一個(gè)簡(jiǎn)單的卷積和遞歸模型,使其比Wave-U-Net的比信號(hào)失真比提高了1.6個(gè)點(diǎn)。
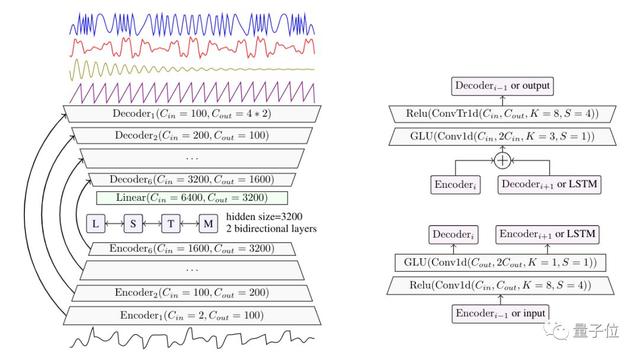
上圖是Demucs的完整框架結(jié)構(gòu),右側(cè)是編碼器和解碼器層的詳細(xì)表示。
與之前的Wave-U-Net相比,Demucs的創(chuàng)新之處在于編碼器和解碼器中的GLU激活函數(shù),以及其中的雙向LSTM和倍增的通道數(shù)量。
Conv-TasNet是哥大的一名中國(guó)博士生Yi Luo提出的一種端到端時(shí)域語(yǔ)音分離的深度學(xué)習(xí)框架。
Conv-TasNet使用線性編碼器來(lái)生成語(yǔ)音波形的表示形式,該波形針對(duì)分離單個(gè)音軌進(jìn)行了優(yōu)化。音軌的分離則是通過(guò)將一組加權(quán)函數(shù)(mask)用于編碼器輸出來(lái)實(shí)現(xiàn)。
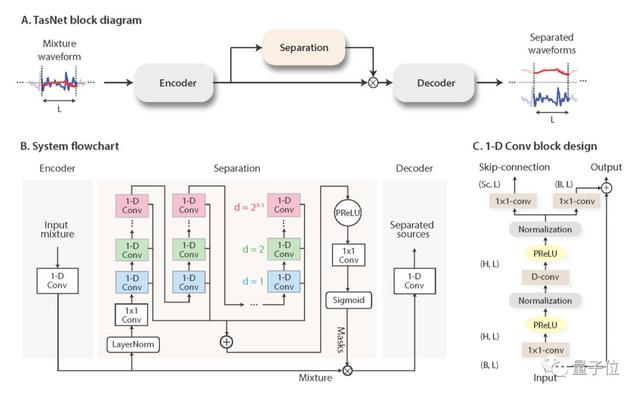
然后使用線性解碼器將修改后的編碼器表示形式反轉(zhuǎn)回波形。由卷積的一維擴(kuò)張卷積塊組成的時(shí)間卷積網(wǎng)絡(luò)(TCN)查找mask,使網(wǎng)絡(luò)可以對(duì)語(yǔ)音信號(hào)的長(zhǎng)期依賴性進(jìn)行建模,同時(shí)保持較小的模型尺寸。
Conv-TasNet具有顯著較小的模型尺寸和較短的延遲,是脫機(jī)和實(shí)時(shí)語(yǔ)音分離應(yīng)用程序的合適解決方案。
傳送門
項(xiàng)目地址:
https://github.com/facebookresearch/demucs
測(cè)試結(jié)果論文:
https://hal.archives-ouvertes.fr/hal-02379796/document