復制粘貼一時爽:傳播最廣的一段Java代碼曝出Bug
復制粘貼一時爽,頻出 bug 火葬場。對開發者而言,Stack Overflow 和 GitHub 是最為熟悉不過的兩大平臺,這些平臺充斥著大量開源項目信息和解決各類問題的代碼片段。最近,一位叫做 Aioobe 的開發者在一項調查中發現了一段自己十年前寫的代碼,這段代碼成為了 Stack Overflow 上復制次數最多、傳播范圍最廣的答案,GitHub 的眾多項目中也存在這段代碼。然而,這位開發者表示這段代碼其實是有 bug 的,并于近日更新了答案并作出說明。
這段代碼是干啥的?
2010 年的時候,我整天泡在 Stack Overflow 上回答問題,希望可以提高自己的知名度。當時,有一個問題吸引了我的注意:如何以人類可讀的格式輸出字節數?舉個例子,將“123456789 字節”轉換為“123.5 MB”的格式輸出。
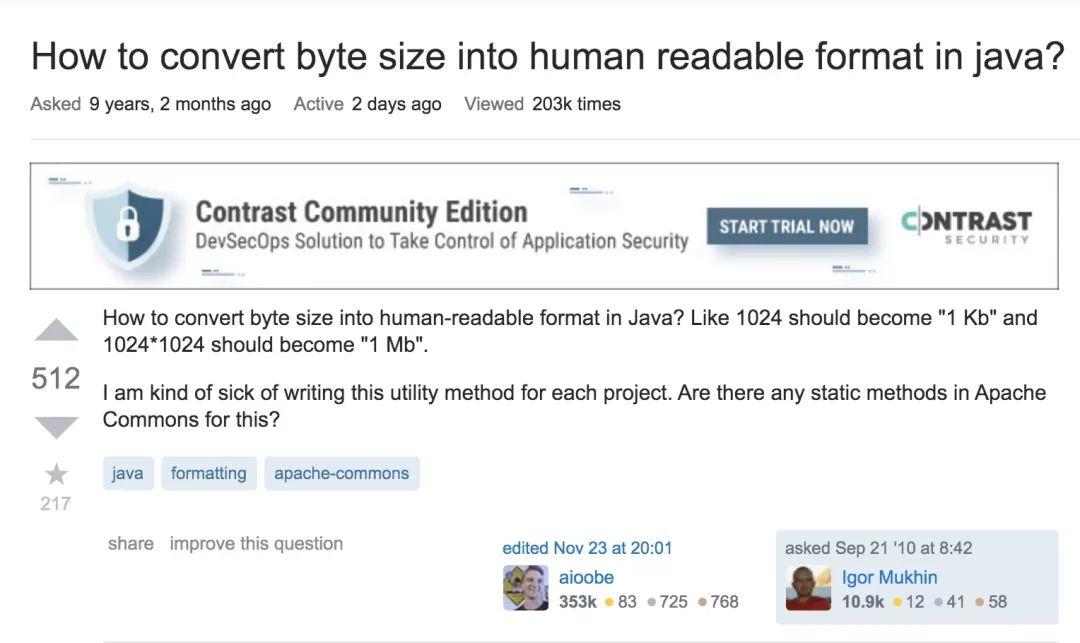
這是現在的截圖,但問題確實是這個
這里的隱含范式在于所得到的字符串值應該在 1 到 999.9 之間,后面再跟上一個大小合適的單位。當時已經有人給了一條回應。答案中的代碼以循環為基礎,基本思路非常簡單:嘗試所有單位,從最大(EB,即 1018 字節)到最小(B,即 1 字節),而后使用一種顯示數量小于實際字節數量的單位。用偽代碼寫出來,基本是這么個意思:
- suffixes = [ "EB", "PB", "TB", "GB", "MB", "kB", "B" ]
- magnitudes = [ 1018, 1015, 1012, 109, 106, 103, 100 ]
- i = 0
- while (i < magnitudes.length && magnitudes[i] > byteCount)
- i++
- printf("%.1f %s", byteCount / magnitudes[i], suffixes[i])
一般來說,如果發布的正確答案已經獲得了正分數,那后發者很難追上。在 Stack Overflow 上,這就叫“拔槍最快的贏”。不過,我認為這個答案有缺陷,所以準備重新改改。我意識到,無論是 KB、MB 還是 GB,所有單位的本質實際都是 1000 的冪(當然,按 IEC 標準來講是 1024),意味著應該可以使用對數而非循環來計算正確的量級單位。
基于以上思路,我發布了下列內容:
- public static String humanReadableByteCount(long bytes, boolean si) {
- int unit = si ? 1000 : 1024;
- if (bytes < unit) return bytes + " B";
- int exp = (int) (Math.log(bytes) / Math.log(unit));
- String pre = (si ? "kMGTPE" : "KMGTPE").charAt(exp-1) + (si ? "" : "i");
- return String.format("%.1f %sB", bytes / Math.pow(unit, exp), pre);
- }
當然,這段代碼可讀性不高,而且 log/pow 也可能在一定程度上影響執行效率,但至少這里沒有循環,幾乎不涉及分支,我覺得還是比較整潔的。
這里面使用的數學方法非常簡單。字節計數表示為 byeCount=1000s , 其中的 s 代表小數點后的位數(以二進制表示,則使用 1024 為基數),求解 s,即可得出 s=log1000(byteCount)。
API 里沒有現成的 log1000 可以直接使用,但我們不妨用自然對數來表示,即 s = log(byteCount) / log(1000)。接下來,我們取 s 的底(即取整數),因為假如我們得出的結果超過 1 MB(但不足 1 GB),則希望繼續使用 MB 作為表示單位。
此時,如果 s=1,則單位為 KB;如果 s=2,則單位為 MB;依此類推,我們將 byteCount 值除以 1000s ,然后取對應的單位。
接下來,我能做的就是等待,看看社區是否喜歡這個答案。那時候的我,絕對想不到它會成為 Stack Overflow 上復制最多的代碼片段。
BUG 在哪?
估計不少人看到這兒肯定在想,這段代碼里到底有什么 bug?再來看一遍代碼:
- public static String humanReadableByteCount(long bytes, boolean si) {
- int unit = si ? 1000 : 1024;
- if (bytes < unit) return bytes + " B";
- int exp = (int) (Math.log(bytes) / Math.log(unit));
- String pre = (si ? "kMGTPE" : "KMGTPE").charAt(exp-1) + (si ? "" : "i");
- return String.format("%.1f %sB", bytes / Math.pow(unit, exp), pre);
- }
在 EB,即 1018 之后,接下來的單位應該是 ZB,即 1021。難道是輸入量過大導致“kMGTPE”字符串的索引超出范圍?不是的,long 的最大值是 263 - 1 ≈ 9.2 × 1018,因此任何 long 值都不會超出 EB 范圍。
那么,是 SI 與二進制之間存在混雜嗎?也不是。答案的早期版本中確實有這個問題,但很快就得到了修復。
那么,是不是 exp 可以為 0 會導致 charAt(exp-1) 發生錯誤?不是的。第一個 if 語句也涵蓋了這種情況,因此 exp 值將始終至少為 1。
那就只剩最后一種情況了,輸出結果中是否存在某些奇怪的舍入錯誤?這正是我們接下來要討論的部分……
太多 9
這套解決方案一直運作良好,直到字節數量達到 1 MB。假定輸入為 999999 字節,那么結果(在 SI 模式下)將為“1000.0 kB”。盡管 999999 比 999.9 x 10001 更接近于 1000 x 10001,但根據規范,1000 的“有效位數”超出了范圍。正確的結果應該是“1.0 MB”。
無論如何,在這個帖子的所有 22 個答案中(包括使用 Apache Commons 以及 Android 庫的答案)截至本文撰稿之時都存在這個錯誤(或者其變體)。那么,我們該如何解決?
首先,我們會注意到,一旦字節數比 999.9 x 10001(999.9 k)更接近于 1 x 10002(1 MB),則指數(exp)就應由“k”變更為“M”。例如,9999950 就符合這種情況。同樣的,當我們輸入 999950000 時,我們應該從“M”切換為“G”,依此類推。為了達成這一目標,我們會計算該閾值,一旦字節數超過閾值,則增加 exp:
- if (bytes >= Math.pow(unit, exp) * (unit - 0.05))
- exp++;
調整之后,代碼即可正常工作,直到字節數接近 1 EB。以輸入為 999,949,999,999,999,999 為例,其目前的結果為 1000.0 PB,但正確結果應該是 999.9 PB。但從數學上講,代碼結果又是準確的,這又是怎么回事?這里,我們就遇到了 double(雙)精度機制的局限性。
浮點運算基礎知識
由于采用 IEEE 754 表示方式,因此近零浮點值會非常密集,但大值則非常稀疏。實際上,所有浮點值中的一半都位于 -1 與 1 之間;而在談到大雙精度浮點數時,像 Long.MAX_VALUE 那么大的值已經沒有任何意義了。
- double l1 = Double.MAX_VALUE;
- double l2 = l1 - Long.MAX_VALUE;
- System.err.println(l1 == l2); // prints true
下面來看兩項有問題的計算:
- String.format 參數中的除法;
- exp 進位閾值
我們當然可以切換為 BigDecimal,但這么干就沒意思了。另外,由于標準 API 中沒有 BigDecimal log 函數,所以問題其實仍然存在。
縮小中間值
對于第一個問題,我們可以將字節值縮小至更合理的精度范圍,同時相應調整 exp。無論如何,最終結果都會四舍五入,因此我們要做的就是不要舍棄最低有效數字。
- if (exp > 4) {
- bytes /= unit;
- exp--;
- }
調整最低有效位
對于第二個問題,我們當然關心最低有效位(999、949、99…9 與 999,950,00…0 應該以不同的單位結尾),因此必須得想個不同的解決方案。
首先,我們注意到閾值存在 12 種不同的可能值(每種模式 6 種),而且其中只有一種最終會發生故障。通過以 D0016 結尾這一跡象,可以準確識別出錯誤結果。一旦發生這種情況,我們將其調整為正確值即可。
- long th = (long) (Math.pow(unit, exp) * (unit - 0.05));
- if (exp < 6 && bytes >= th - ((th & 0xFFF) == 0xD00 ? 52 : 0))
- exp++;
由于我們在浮點結果中需要使用特定數位模式,因此下手的對象自然就是 strictfp,旨在保證其不受硬件運行代碼的影響。
負輸入
目前我還沒想到什么情況下有可能需要使用負字節數量,但考慮到 Java 不支持無符號 long,我們最好還是把這個問題考慮進來。現在,如果輸入為 -10000,那么結果為 -10000 B。這里我們引入 absBytes:
- long absBytes = bytes == Long.MIN_VALUE ? Long.MAX_VALUE : Math.abs(bytes);
這里的表達之所以如此復雜,是基于 -Long.MIN_VALUE == Long.MIN_VALUE 這一事實。現在,我們利用 absBytes 替代 bytes 執行所有與 exp 相關的計算。
最終版本
以下是代碼片段的最終版本,其中已經對最初版本做了精心調整與改進:
- // 來自: https://programming.guide/the-worlds-most-copied-so-snippet.html
- public static strictfp String humanReadableByteCount(long bytes, boolean si) {
- int unit = si ? 1000 : 1024;
- long absBytes = bytes == Long.MIN_VALUE ? Long.MAX_VALUE : Math.abs(bytes);
- if (absBytes < unit) return bytes + " B";
- int exp = (int) (Math.log(absBytes) / Math.log(unit));
- long th = (long) (Math.pow(unit, exp) * (unit - 0.05));
- if (exp < 6 && absBytes >= th - ((th & 0xfff) == 0xd00 ? 52 : 0)) exp++;
- String pre = (si ? "kMGTPE" : "KMGTPE").charAt(exp - 1) + (si ? "" : "i");
- if (exp > 4) {
- bytes /= unit;
- exp -= 1;
- }
- return String.format("%.1f %sB", bytes / Math.pow(unit, exp), pre);
- }
請注意,這段代碼最初的目標是避免由循環以及大量分支帶來的復雜性。在解決了所有極端情況之后,新代碼的可讀性要比原始版本更差。我個人是肯定不會把這段代碼復制到生產代碼中的。
這段代碼被復制到了哪里?
此前,一位名叫 Sebastian Baltes 的博士生在《Empirical Software Engineering》上發表了一篇論文,標題為《GitHub 項目中 Stack Overflow 代碼片段的用法與歸因》,文章探討的核心議題只有一個:用戶對代碼片段的引用是否遵循 Stack Overflow 的 CC BY-SA 3.0 許可,即從 Stack Overflow 上復制代碼時,用戶應保證何等程度的歸因水平?
在分析當中,作者從 Stack Overflow 數據轉儲中提取出代碼片段,并將其與公共 GitHub 存儲庫中的代碼進行匹配。下面來看論文的基本發現:
我們進行了一項大規模實證研究,分析了來自各公共 GitHub 項目中的非常規 Java 代碼片段,對其中實際上源自 Stack Overflow 的代碼片段進行了用法與歸因調查。
這篇文章給出了一份表格,而其中 ID 為 3758880 的答案正是我幾年前發布的那一條。截至目前,這條答案獲得了幾十萬次查看外加一千多個好評。只要在 GitHub 上隨便搜搜,就能找到成千上萬條 humanReadableByteCount。
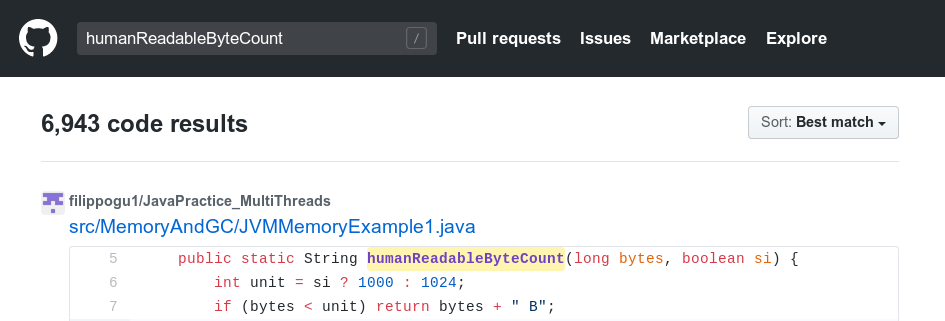
這也就意味著,這段有問題的代碼被無數的項目和開發者引用,要驗證這段代碼是否也在自己的本地存儲庫內,請執行以下操作:
- $ git grep humanReadableByteCount
心得摘要
最后,我希望告訴廣大開發者 Stack Overflow 上的代碼片段可能存在 bug,即使得到無數好評也改變不了這一事實;一定要對所有極端情況做出測試,特別是測試那些復制自 Stack Overflow 的代碼;浮點運算很復雜,也很困難,在復制代碼時,請確保了解代碼背后的邏輯和使用規范。