這個賽車AI不再只圖一時爽,學會了考慮長遠策略
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
玩賽車游戲的AI們現在已經不僅僅是圖快圖爽了。
他們開始考慮戰術規劃,甚至有了自己的行車風格和“偏科”項目。
比如這位只擅長轉彎的“偏科”選手,面對急彎我重拳出擊,驚險漂移,面對直線我唯唯諾諾,搖晃不停:

還有具備長遠目光,學會了戰術規劃的AI,也就是這兩位正在競速的中的綠色賽車,看似在轉彎處減緩了速度,卻得以順利通過急彎,免于直接GG的下場。

還有面對不管是多新的地圖,都能舉一反三,跑完全程的AI。
看起來就像是真的在賽車道上學會了思考一樣。
(甚至上面所說的那位偏科選手還在不懈努力后成功逆襲了)
這項訓練結果一經公布,便吸引了大批網友的圍觀:
強化學習讓AI學會“長遠考慮”
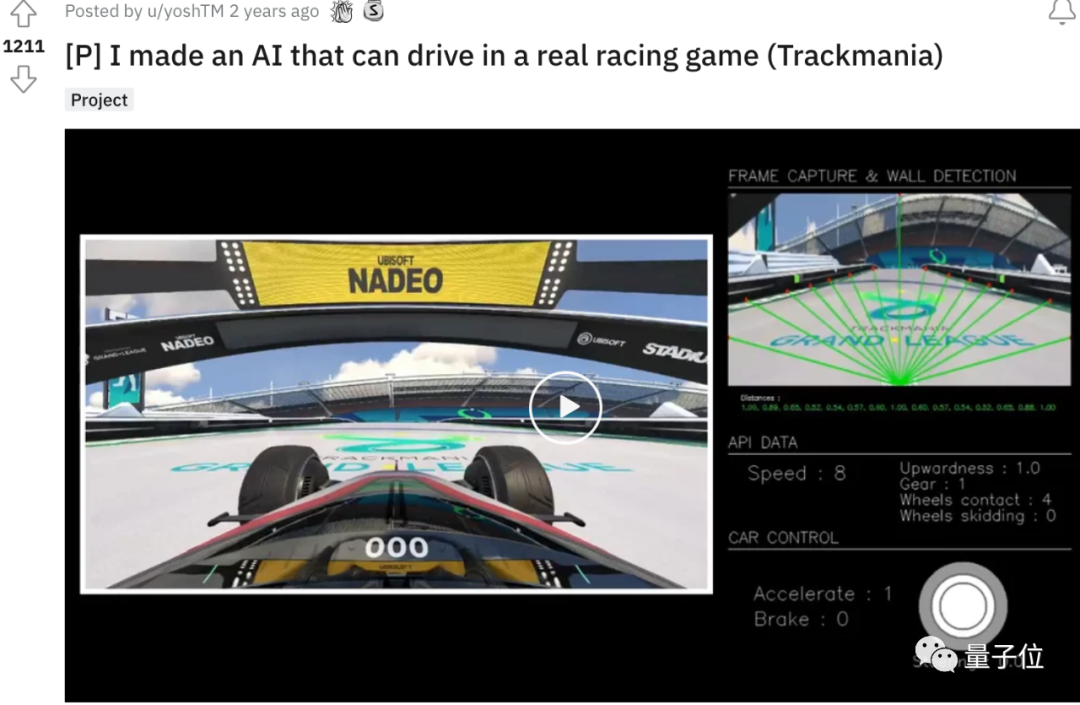
訓練賽道來自一款叫做《賽道狂飆》(Trackmania)的游戲,以可深度定制的賽道編輯器聞名于玩家群體。
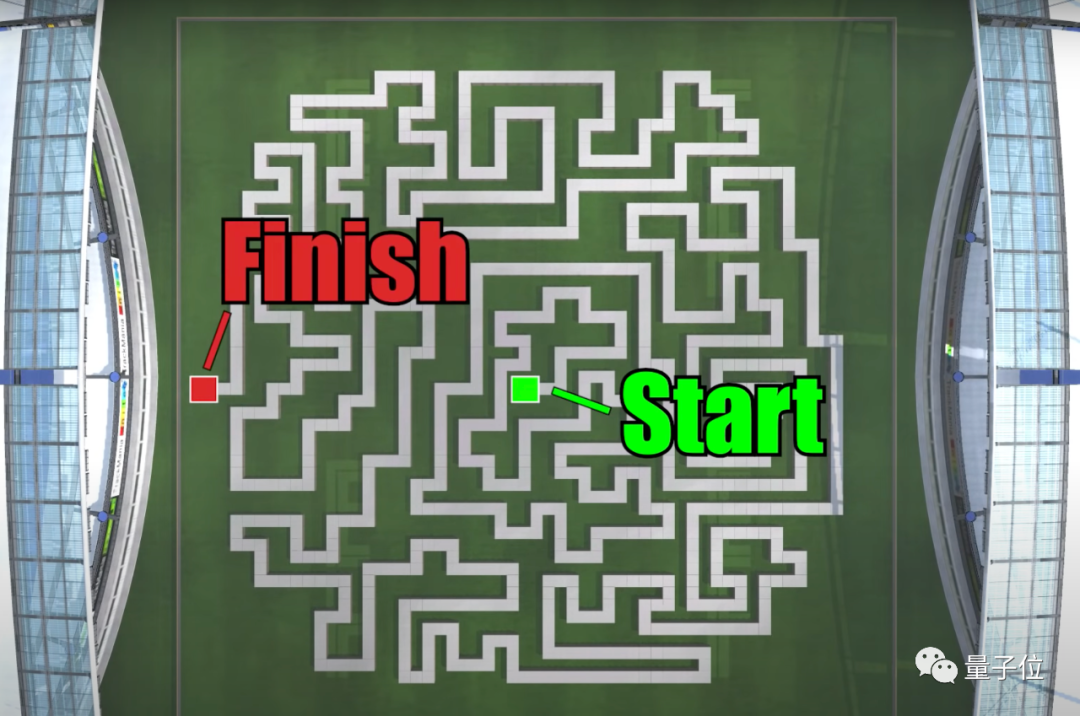
為了更大程度上激發賽車AI的潛力,開發者自制了這樣一張九曲十八彎的魔鬼地圖:
這位開發者名叫yoshtm,之間就已經用AI玩過這款游戲,一度引發熱議:
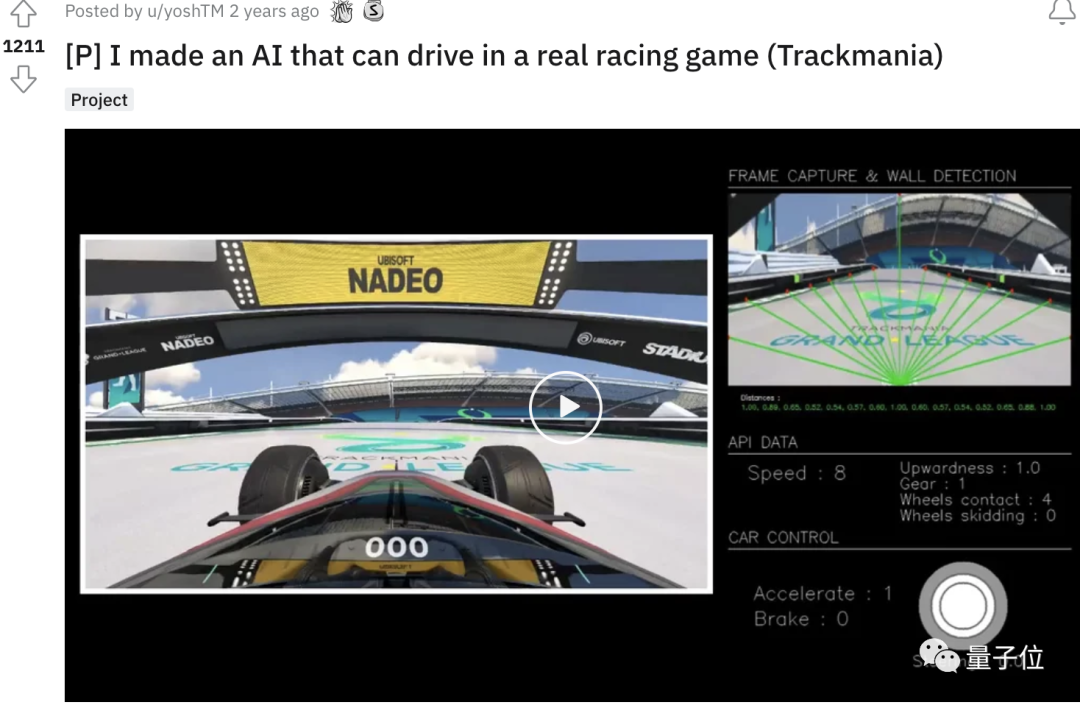
一開始,yoshtm采用的是一種監督學習模型,擁有2個隱藏層。
模型包含了16個輸入,包括如汽車當前速度、加速度、路段位置等等,再通過神經網絡對輸入參數進行分析,最終輸出6種動作中的一種:
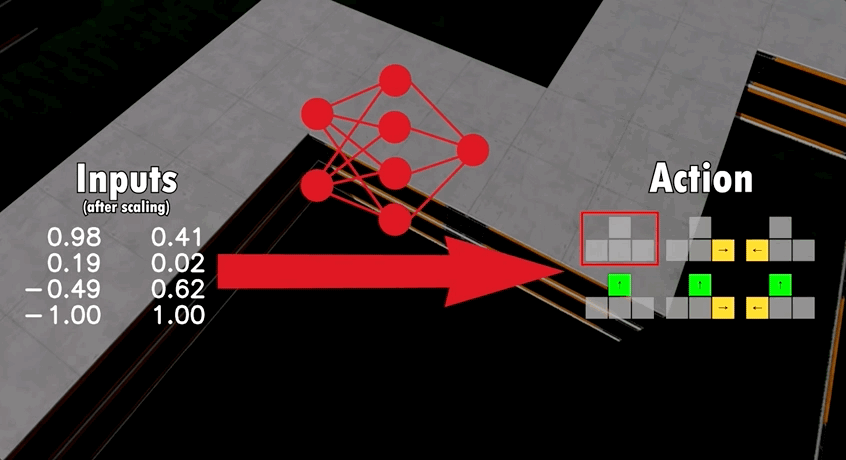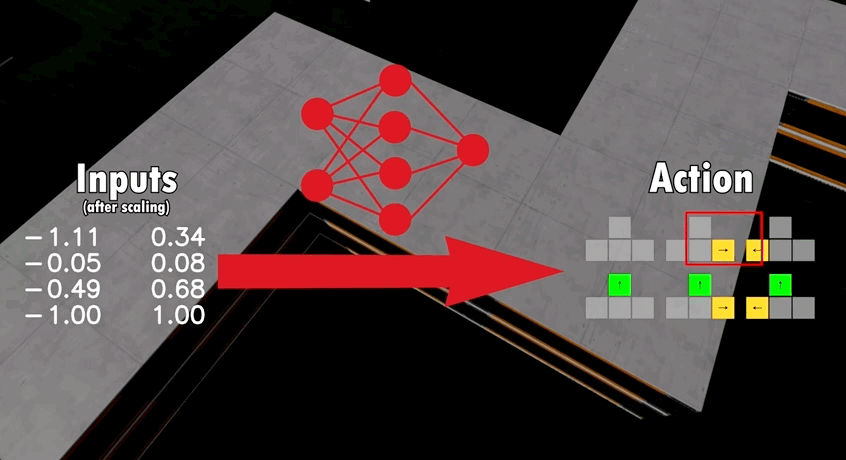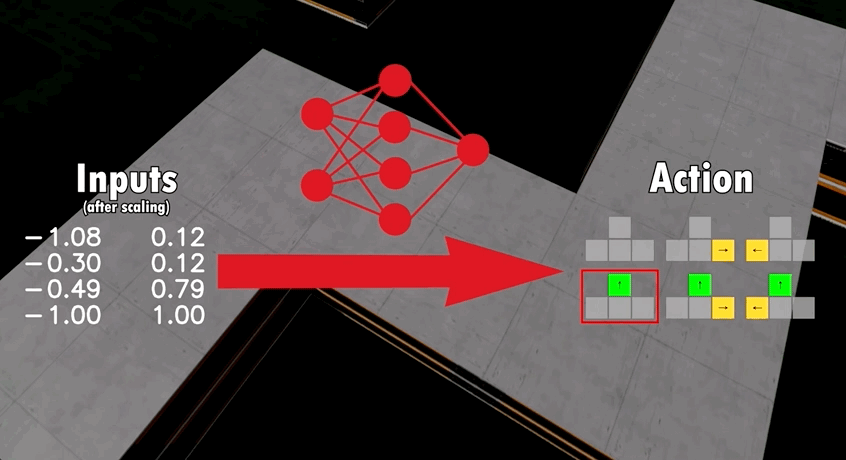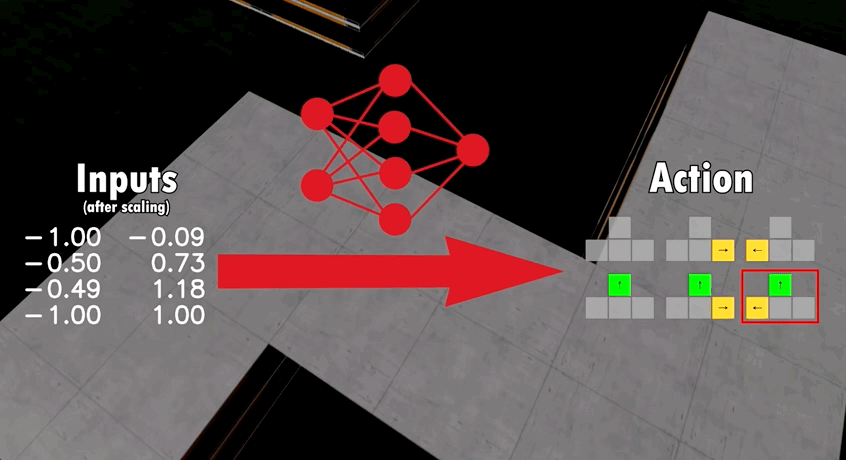
基于這一模型架構,開發者讓多只AI在同一張地圖上競爭。
通過多次迭代,不同AI的神經網絡會出現細微的差別,結果最好的AI將最終脫穎而出。
這種方法確實能讓AI學會駕駛,不過也帶來了一個問題:
AI常常只能以速度或最終沖線的時間等單一指標來評估自己,難以更進一步。
這次,時隔兩年后的賽車AI,不僅學會了從長遠出發制定策略(比如在急彎時對速度作出調整),還大幅提高了對新地圖的適應性。
主要原因就來自于開發者這次引入的新方法,強化學習。
這種方法的核心概念是“獎勵”,即通過選擇帶來更多獎勵的行為,來不斷優化最終效果。
在訓練賽車游戲中的AI時,yoshtm定義的獎勵很常規:速度越快獎勵越多,走錯路或掉下賽道就會懲罰。

但問題是,一些行動,比如在臨近轉彎時的加速或許能導致短期的正面獎勵,但從長遠來看卻可能會產生負面的后果。
于是,yoshtm采用了一種叫做Deep Q Learning的方法。
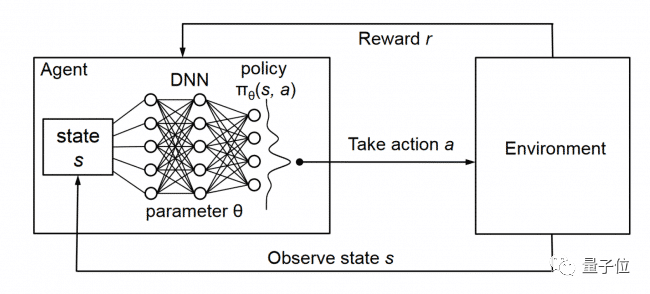
這是一種無模型的強化學習技術,對于給定狀態,它能夠比較可用操作的預期效用,同時還不需要環境模型。
Deep Q Learning會通過深度網絡參數 的學習不斷提高Q值預測的準確性,也就是說,能夠使AI在賽車游戲中預測每個可能的行動的預期累積獎勵,從而“具備一種長遠的策略目光”。
隨機出生點幫AI改正“偏科”
接下來開始進行正式訓練。
yoshtm的思路是,AI會先通過隨機探索來盡可能多地收集地圖數據,他將這一行為稱之為探索。
探索的比例越高,隨機性也就越強,而隨著比例降低,AI則會更加專注于贏取上述設置的獎勵,也即專注于跑圖。

不過,在訓練了近3萬次,探索比例降低到5%時,AI“卡關”了:

核心問題是AI出現了“偏科”。
由于前期經歷了多個彎道的跑圖,所以AI出現了過擬合現象,面對長直線跑道這種新的賽道類型,一度車身不穩,搖搖晃晃,最終甚至選擇了“自殺”:
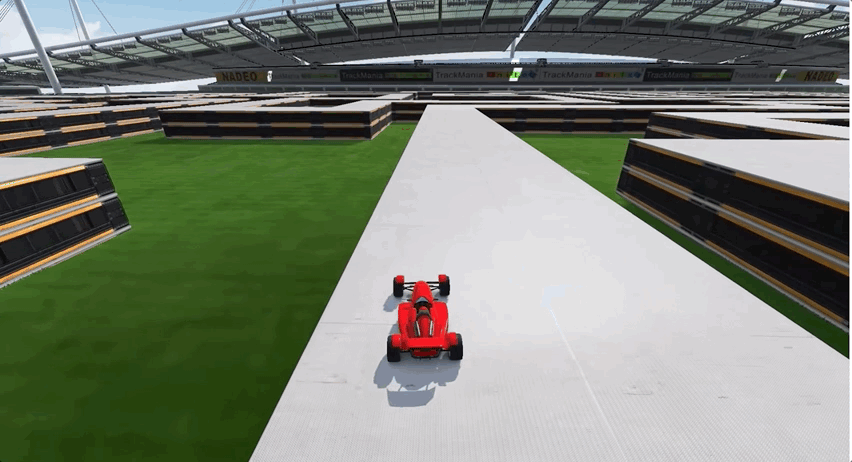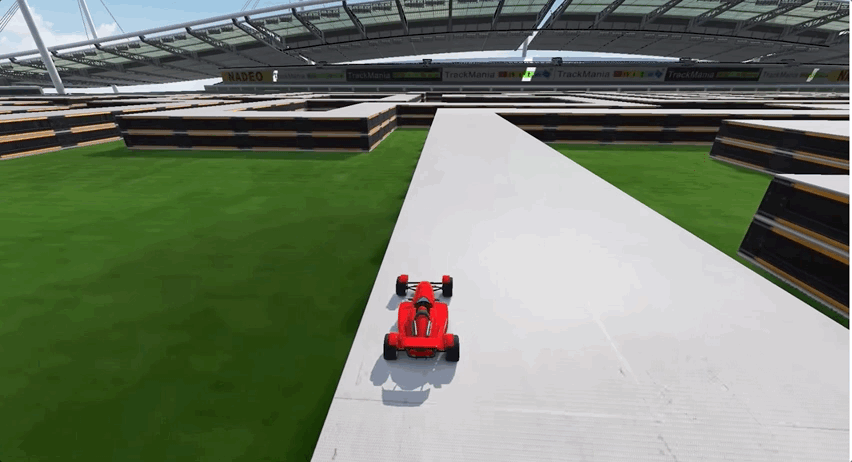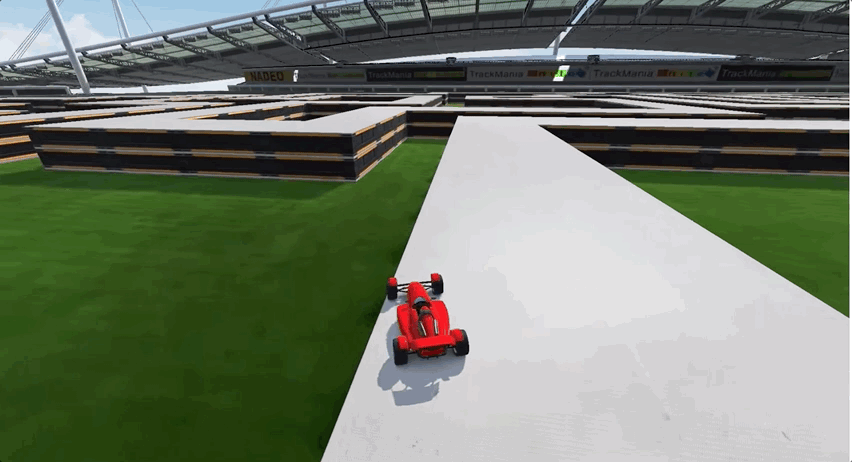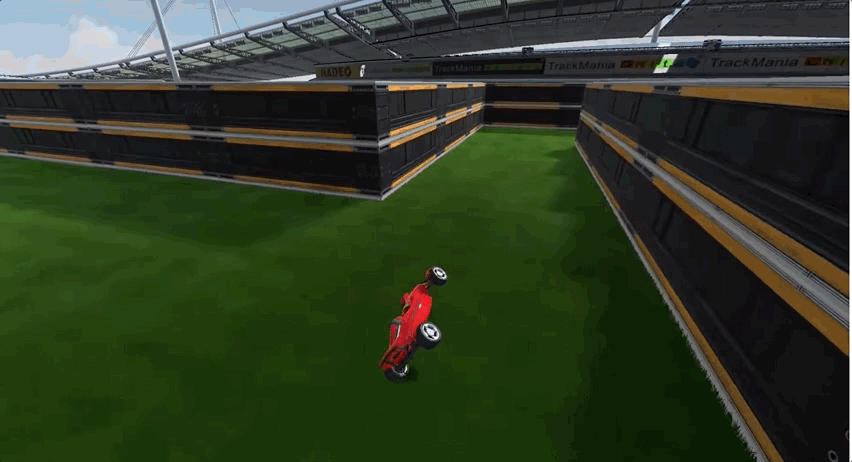
要如何解決這個問題呢?
yoshtm并沒有選擇重新制作地圖,而是選擇修改AI的出生點:
每次開始訓練時,AI的出發點都將在地圖上的一個隨機位置生成,同時速度和方向也會隨機。

《賽車狂飆》本來就是一個需要大量訓練的游戲,AI當然也如此。
至少我現在很確定,這個AI可以打敗大量的初學者。
這一辦法立竿見影,AI終于開始能夠完整跑完一條賽道了。
接下來就是進行不斷訓練,最終,開發者yoshtm和AI比了一場,AI在這次跑到了最好成績:6分20秒。

雖然還是沒有真人操控的賽車跑得快,不過AI表現出了較強的場地適應性,對草地還是泥地都能立馬舉一反三。
yoshtm最后這樣說道:
《賽車狂飆》本來就是一個需要大量訓練的游戲,AI當然也如此。
至少我現在很確定,這個AI可以打敗大量的初學者。