“分庫分表" 不注意選型和流程的話,容易失控
數據庫中間件之分庫分表
恭喜你,貴公司終于成長到一定規模,需要考慮高可用,甚至分庫分表了。但你是否知道分庫分表需要哪些要素?拆分過程是復雜的,提前計劃,不要等真正開工,各種意外的工作接踵而至,以至失控。
本文意圖打開數據庫中間件的廣度,而不考慮實現深度,至于庫表垂直和水平分的概念和緣由,不做過多解釋。所以此文面向的是有一定研發經驗,正在尋找選型和拆分流程的專業人士。
切入層次
以下,范圍界定在JAVA和MySQL中。我們首先來看一下分庫分表切入的層次。
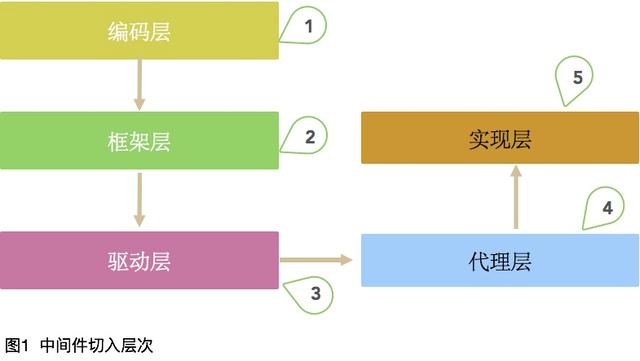
① 編碼層
在同一個項目中創建多個數據源,采用if else的方式,直接根據條件在代碼中路由。Spring中有動態切換數據源的抽象類,具體參見
AbstractRoutingDataSource。
如果項目不是很龐大,使用這種方式能夠快速的進行分庫。但缺點也是顯而易見的,需要編寫大量的代碼,照顧到每個分支。當涉及跨庫查詢、聚合,需要循環計算結果并合并的場景,工作量巨大。
如果項目裂變,此類代碼大多不能共用,大多通過拷貝共享。長此以往,碼將不碼。
② 框架層
這種情況適合公司ORM框架統一的情況,但在很多情況下不太現實。主要是修改或增強現有ORM框架的功能,在SQL中增加一些自定義原語或者hint來實現。
通過實現一些攔截器(比如Mybatis的Interceptor接口),增加一些自定義解析來控制數據的流向,效果雖然較好,但會改變一些現有的編程經驗。
很多情況要修改框架源碼,不推薦。
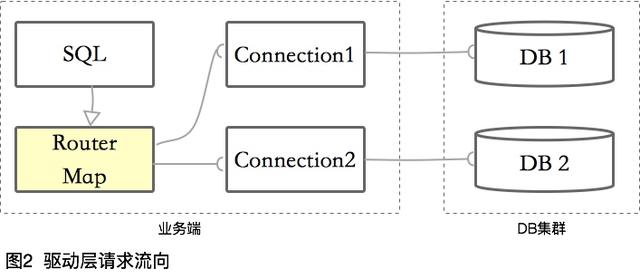
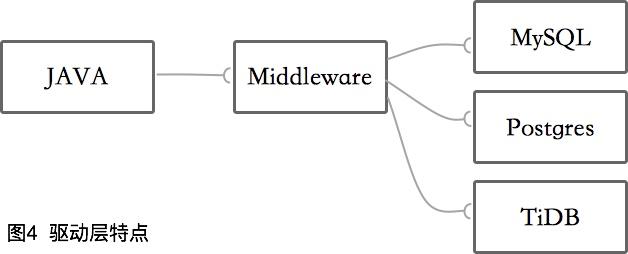
③ 驅動層
基于在編碼層和框架層切入的各種缺點,真正的數據庫中間件起碼要從驅動層開始。什么意思呢?其實就是重新編寫了一個JDBC的驅動,在內存中維護一個路由列表,然后將請求轉發到真正的數據庫連接中。
像TDDL、ShardingJDBC等,都是在此層切入。
包括Mysql Connector/J的Failover協議
(具體指“load balancing”、“replication”、“farbic”等),
也是直接在驅動上進行修改。
請求流向一般是這樣的:
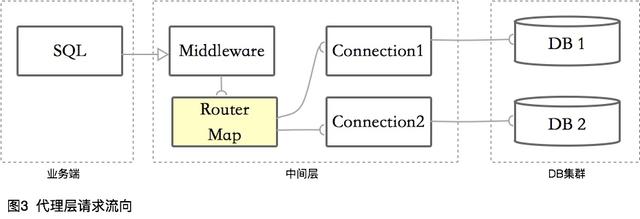
④ 代理層
代理層的數據庫中間件,將自己偽裝成一個數據庫,接受業務端的鏈接。然后負載業務端的請求,解析或者轉發到真正的數據庫中。
像MySQL Router、MyCat等,都是在此層切入。
請求流向一般是這樣的:
⑤ 實現層
SQL特殊版本支持,如Mysql cluster本身就支持各種特性,mariadb galera cluster支持對等雙主,Greenplum支持分片等。
需要換存儲,一般是解決方案,就不在討論之列了。
技術最終都會趨于一致,選擇任何一種、都是可行的。但最終選型,受開發人員熟悉度、社區活躍度、公司切合度、官方維護度、擴展性,以及公司現有的數據庫產品等多方位因素影響。選擇或開發一款合適的,小伙伴們會幸福很多。
驅動層和代理層對比
通過以上層次描述,很明顯,我們選擇或開發中間件,就集中在驅動層和代理層。在這兩層,能夠對數據庫連接和路由進行更強的控制和更細致的管理。但它們的區別也是明顯的。
驅動層特點
僅支持JAVA,支持豐富的DB
驅動層中間件僅支持Java一種開發語言,但支持所有后端關系型數據庫。如果你的開發語言固定,后端數據源類型豐富,推薦使用此方案。
占用較多的數據庫連接
驅動層中間件要維護很多數據庫連接。比如一個分了10個 庫 的表,每個java中的Connection要維護10個數據庫連接。如果項目過多,則會出現連接爆炸(我們算一下,如果每個項目6個實例,連接池中minIdle等于5,3個項目的連接總數是 10*6*5*3 = 900個)。像Postgres這種每個連接對應一個進程的數據庫,壓力會很大。
數據聚合在業務實例執行
數據聚合,比如count sum等,是通過多次查詢,然后在業務實例的內存中進行聚合。
路由表存在于業務方實例內存中,通過輪詢或者被動通知的途徑更新路由表即可。
集中式管理
所有集群的配置管理都集中在一個地方,運維負擔小,DBA即可完成相關操作。
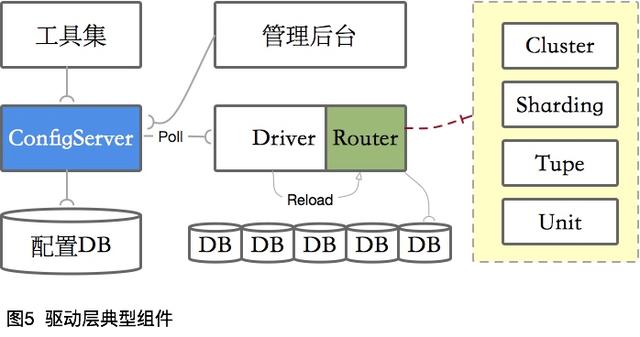
典型實現
代理層特點
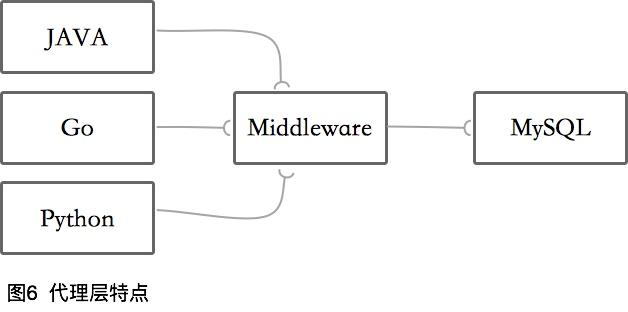
異構支持,DB支持有限
代理層中間件正好相反。僅支持一種后端關系型數據庫,但支持多種開發語言。如果你的系統是異構的,并且都有同樣的SLA要求,則推薦使用此方案。
運維負擔大
代理層需要維護數據庫連接數量有限(MySQL Router那種粘性連接除外)。但作為一個獨立的服務,既要考慮單獨部署,又要考慮高可用,會增加很多額外節點,更別提用了影子節點的公司了。
另外,代理層是請求唯一的入口,穩定性要求極高,一旦有高耗內存的聚合查詢把節點搞崩潰了,都是災難性的事故。
典型實現
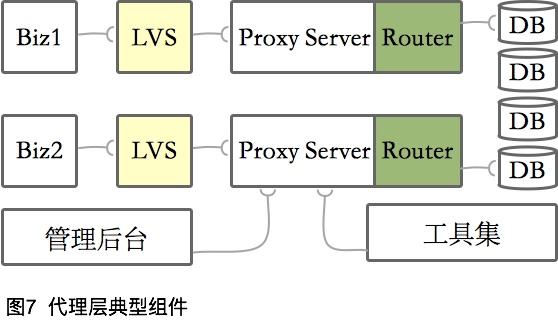
共同點
篇幅有限,不做過多討論。訪問各中間件宣傳頁面,能夠看到長長的Feature列表,也就是白名單;也能看到長長的限制列表,也就是黑名單。限定了你怎么玩,在增強了分布式能力后,分庫分表本身就是一個閹割的數據庫。
使用限制
確保數據均衡 拆分數據庫的數據盡量均勻,比如按省份分user庫不均勻,按userid取模會比較均勻
不用深分頁 不帶切分鍵的深分頁,會取出所有庫所取頁數之前的所有數據在內存排序計算。容易造成內存溢出。
減少子查詢 子查詢會造成SQL解析紊亂,解析錯誤的情況,盡量減少SQL的子查詢。
事務最小原則 盡量縮小單機事務涉及的庫范圍,即盡可能減少夸庫操作,將同類操作的庫/表分在一起
數據均衡原則 拆分數據庫的數據盡量均勻,比如按省份分user庫不均勻,按userid取模會比較均勻
特殊函數 distinct、having、union、in、or等,一般不被支持。或者被支持,使用之后會增加風險,需要改造。
產品
建議聚焦在MyCat和ShardingJDBC上。另外,還有大量其他的中間件,不熟悉建議不要妄動。
數據庫中間件不好維護,你會發現大量半死不活的項目。
以下列表,排名不分先后,有幾個是只有HA功能,沒有拆分功能的:
Atlas、Kingshard、DBProxy、mysql router、MaxScale、58 Oceanus、ArkProxy、Ctrip DAL、Tsharding、Youtube vitess、網易DDB、Heisenberg、proxysql、Mango、DDAL、Datahekr、MTAtlas、MTDDL、Zebra、Cobar、Cobar
汗、幾乎每個大廠都有自己的數據庫中間件(還發現了幾個喜歡拿開源組件加公司前綴作為產品的),只不過不給咱用罷了。
流程解決方案
無論是采用哪個層面切入進行分庫分表,都面臨以下工作過程。
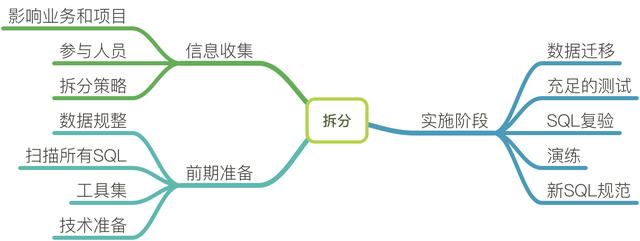
信息收集
統計影響的業務和項目
項目范圍越大,分庫難度越高。有時候,一句復雜的SQL能夠涉及四五個業務方,這種SQL都是需要重點關注的。
確定分庫分表的規模,是只分其中的幾張表,還是全部涉及。分的越多,工作量越大,幾乎是線性的。
還有一些項目是牽一發動全身的。舉個例子,下面這個過程,影響的鏈路就不僅是分庫這么簡單了。
確定參與人員
除了分庫分表組件的技術支持人員,最應該參與的是對系統、對現有代碼最熟悉的幾個人。只有他們能夠確定哪些SQL該廢棄掉、SQL的影響面等。
確定分庫分表策略
確定分庫分表的維度和切分鍵。切分鍵(就是路由數據的column)一旦確定,是不允許修改的,所以在前期架構設計上,應該首先將其確立下來,才能進行后續的工作;數據維度多意味著有不同的切分鍵,達到不同條件查詢的效果。這涉及到數據的冗余(多寫、數據同步),會更加復雜。
前期準備
數據規整
庫表結構不滿足需求,需要提前規整。比如,切分鍵的字段名稱不同或者類型各異。在實施分庫分表策略時,這些個性會造成策略過大不好維護。
掃描所有SQL
將項目中所有的SQL掃描出來,逐個判斷是否能夠按照切分鍵正常運行。
在判斷過程中肯定會有大量不合規的SQL,則都需要給出改造方案,這是主要的工作量之一。
驗證工具支持
直接在原有項目上進行改動和驗證是可行的,但會遇到諸多問題,主要是效率太低。我傾向于首先設計一些驗證工具,輸入要驗證的SQL或者列表,然后打印路由信息和結果進行判斷。
技術準備
建議以下提到的各個點,都找一個例子體驗一下,然后根據自己的團隊預估難度。
以下:
中間件所有不支持的SQL類型
整理容易造成崩潰的注意事項
不支持的SQL給出處理方式
考慮一個通用的主鍵生成器
考慮沒有切分鍵的SQL如何處理
考慮定時任務等掃全庫的如何進行遍歷
考慮跨庫跨表查詢如何改造
準備一些工具集
實施階段
數據遷移
分庫分表會重新影響數據的分布,無論是全量還是增量,都會涉及到數據遷移,所以Databus是必要的。
一種理想的狀態是所有的增刪改都是消息,可以通過訂閱MQ進行雙寫。
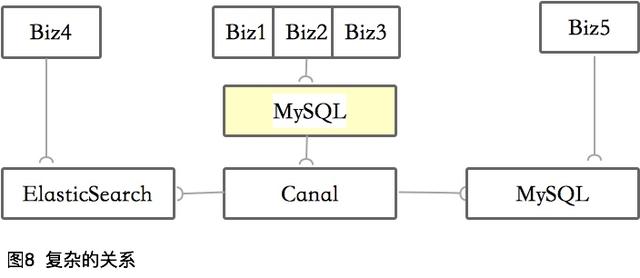
但一般情況下,仍然需要去模擬這個狀態,比如使用Canal組件。
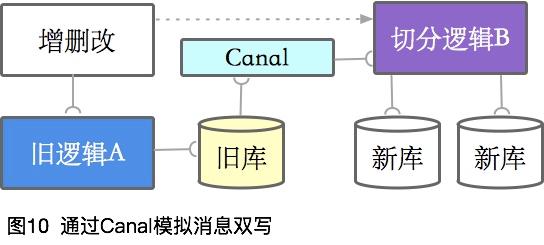
怎么保證數據安全的切換,我們分其他章節進行討論。
充足的測試
分庫分表必須經過充足的測試,每一句SQL都要經過嚴格的驗證。如果有單元測試或者自動化測試工具,完全的覆蓋是必要的。一旦有數據進行了錯誤的路由,尤其是增刪改,將會創造大量的麻煩。
在測試階段,將驗證過程輸出到單獨的日志文件,充足測試后review日志文件是否有錯誤的數據流向。
SQL復驗
強烈建議統一進行一次SQL復驗。主要是根據功能描述,確定SQL的正確性,也就是通常說的review。
演練
在非線上環境多次對方案進行演練,確保萬無一失。
制定新的SQL規范
分庫分表以后,項目中的SQL就加了枷鎖,不能夠隨意書寫了。很多平常支持的操作,在拆分環境下就可能運行不了了。所以在上線前,涉及的SQL都應該有一個確認過程,即使已經經過了充足的測試。
題外話
沒有支持的活別接,干不成。
分庫分表是戰略性的技術方案,很多情況無法回退或者回退方案復雜。如果要拆分的庫表涉及多個業務方,公司技術人員復雜,CTO要親自掛帥進行協調,并有專業仔細的架構師進行監督。沒有授權的協調人員會陷入尷尬的境地,導致流程失控項目難產。
真正經歷過的人,會知道它的痛!