數(shù)據(jù)庫(kù)主從復(fù)制,讀寫分離,分庫(kù)分表,分區(qū)講解
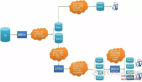
隨著互聯(lián)網(wǎng)應(yīng)用的廣泛普及,海量數(shù)據(jù)的存儲(chǔ)和訪問成為了系統(tǒng)設(shè)計(jì)的瓶頸問題。對(duì)于一個(gè)大型的互聯(lián)網(wǎng)應(yīng)用,每天幾十億的PV無疑對(duì)數(shù)據(jù)庫(kù)造成了相當(dāng)高的負(fù)載。對(duì)于系統(tǒng)的穩(wěn)定性和擴(kuò)展性造成了極大的問題。通過數(shù)據(jù)切分來提高網(wǎng)站性能,橫向擴(kuò)展數(shù)據(jù)層已經(jīng)成為架構(gòu)研發(fā)人員首選的方式。
mysql主從復(fù)制原理
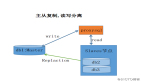
主要涉及三個(gè)線程:binlog 線程、I/O 線程和 SQL 線程。
- binlog 線程 :負(fù)責(zé)將主服務(wù)器上的數(shù)據(jù)更改寫入二進(jìn)制日志(Binary log)中。
- I/O 線程 :負(fù)責(zé)從主服務(wù)器上讀取二進(jìn)制日志,并寫入從服務(wù)器的中繼日志(Relay log)。
- SQL 線程 :負(fù)責(zé)讀取中繼日志,解析出主服務(wù)器已經(jīng)執(zhí)行的數(shù)據(jù)更改并在從服務(wù)器中重放(Replay)。
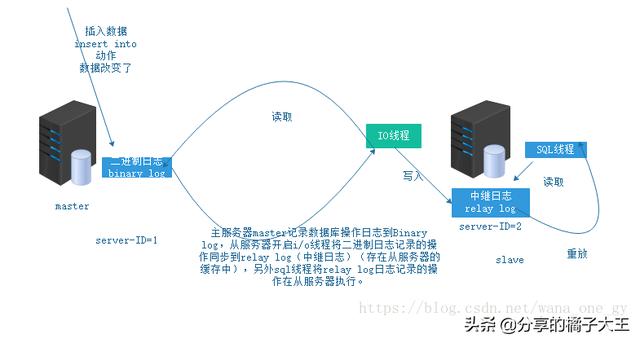
這張圖就很清晰表達(dá)出流程
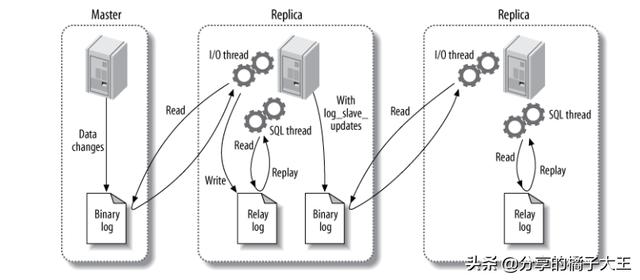
1:主庫(kù)db的更新事件(update、insert、delete)被寫到binlog
2:從庫(kù)發(fā)起連接,連接到主庫(kù)
3:此時(shí)主庫(kù)創(chuàng)建一個(gè)binlog dump thread線程,把binlog的內(nèi)容發(fā)送到從庫(kù)
4:從庫(kù)啟動(dòng)之后,創(chuàng)建一個(gè)I/O線程,讀取主庫(kù)傳過來的binlog內(nèi)容并寫入到relay log
5:還會(huì)創(chuàng)建一個(gè)SQL線程,從relay log里面讀取內(nèi)容,從Exec_Master_Log_Pos位置開始執(zhí)行讀取到的更新事件,將更新內(nèi)容寫入到slave的db.
主從同步復(fù)制模式:

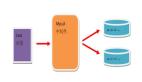
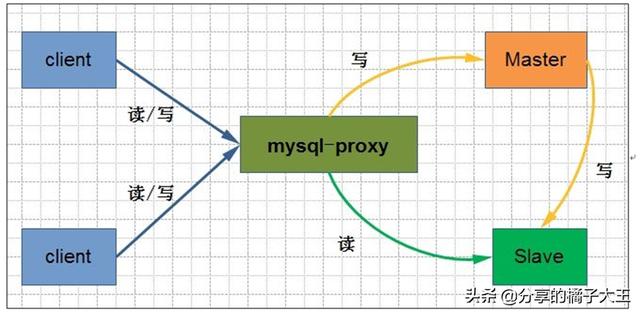
讀寫分離:
MYSQL讀寫分離的原理其實(shí)就是讓Master數(shù)據(jù)庫(kù)處理事務(wù)性增、刪除、修改、更新操作(CREATE、INSERT、UPDATE、DELETE),而讓Slave數(shù)據(jù)庫(kù)處理SELECT操作,MYSQL讀寫分離前提是基于MYSQL主從復(fù)制,這樣可以保證在Master上修改數(shù)據(jù),Slave同步之后,WEB應(yīng)用可以讀取到Slave端的數(shù)據(jù)。
數(shù)據(jù)庫(kù)分區(qū):
分區(qū)并不是生成新的數(shù)據(jù)表,而是將表的數(shù)據(jù)均衡分?jǐn)偟讲煌挠脖P,系統(tǒng)或是不同服務(wù)器存儲(chǔ)介子中,實(shí)際上還是一張表。另外,分區(qū)可以做到將表的數(shù)據(jù)均衡到不同的地方,提高數(shù)據(jù)檢索的效率,降低數(shù)據(jù)庫(kù)的頻繁IO壓力值,分區(qū)的優(yōu)點(diǎn)如下:
- 相對(duì)于單個(gè)文件系統(tǒng)或是硬盤,分區(qū)可以存儲(chǔ)更多的數(shù)據(jù);
- 數(shù)據(jù)管理比較方便,比如要清理或廢棄某年的數(shù)據(jù),就可以直接刪除該日期的分區(qū)數(shù)據(jù)即可;
- 精準(zhǔn)定位分區(qū)查詢數(shù)據(jù),不需要全表掃描查詢,大大提高數(shù)據(jù)檢索效率;
- 可跨多個(gè)分區(qū)磁盤查詢,來提高查詢的吞吐量;
- 在涉及聚合函數(shù)查詢時(shí),可以很容易進(jìn)行數(shù)據(jù)的合并;
1、水平分區(qū)
這種形式分區(qū)是對(duì)表的行進(jìn)行分區(qū),通過這樣的方式不同分組里面的物理列分割的數(shù)據(jù)集得以組合,從而進(jìn)行個(gè)體分割(單分區(qū))或集體分割(1個(gè)或多個(gè)分區(qū))。所有在表中定義的列在每個(gè)數(shù)據(jù)集中都能找到,所以表的特性依然得以保持。
2、垂直分區(qū)
這種分區(qū)方式一般來說是通過對(duì)表的垂直劃分來減少目標(biāo)表的寬度,使某些特定的列被劃分到特定的分區(qū),每個(gè)分區(qū)都包含了其中的列所對(duì)應(yīng)的行。
什么時(shí)候考慮使用分區(qū)?
- 一張表的查詢速度已經(jīng)慢到影響使用的時(shí)候。
- sql經(jīng)過優(yōu)化
- 數(shù)據(jù)量大
- 表中的數(shù)據(jù)是分段的
- 對(duì)數(shù)據(jù)的操作往往只涉及一部分?jǐn)?shù)據(jù),而不是所有的數(shù)據(jù)
分庫(kù)分表:
分庫(kù)分表的原因:
- 隨著單庫(kù)中的數(shù)據(jù)量越來越大,相應(yīng)的,查詢所需要的時(shí)間也越來越多,相當(dāng)于數(shù)據(jù)的處理遇到了瓶頸
- 單庫(kù)發(fā)生意外的時(shí)候,需要修復(fù)的是所有的數(shù)據(jù),而多庫(kù)中的一個(gè)庫(kù)發(fā)生意外的時(shí)候,只需要修復(fù)一個(gè)庫(kù)(當(dāng)然,也可以用物理分區(qū)的方式處理這種問題)
什么時(shí)候考慮使用分庫(kù)?
單臺(tái)DB的存儲(chǔ)空間不夠
隨著查詢量的增加單臺(tái)數(shù)據(jù)庫(kù)服務(wù)器已經(jīng)沒辦法支撐
分庫(kù)解決的問題:
其主要目的是為突破單節(jié)點(diǎn)數(shù)據(jù)庫(kù)服務(wù)器的 I/O 能力限制,解決數(shù)據(jù)庫(kù)擴(kuò)展性問題。
垂直拆分
將系統(tǒng)中不存在關(guān)聯(lián)關(guān)系或者需要join的表可以放在不同的數(shù)據(jù)庫(kù)不同的服務(wù)器中。
按照業(yè)務(wù)垂直劃分。比如:可以按照業(yè)務(wù)分為資金、會(huì)員、訂單三個(gè)數(shù)據(jù)庫(kù)。
需要解決的問題:跨數(shù)據(jù)庫(kù)的事務(wù)、jion查詢等問題。
水平拆分
例如,大部分的站點(diǎn)。數(shù)據(jù)都是和用戶有關(guān),那么可以根據(jù)用戶,將數(shù)據(jù)按照用戶水平拆分。
按照規(guī)則劃分,一般水平分庫(kù)是在垂直分庫(kù)之后的。比如每天處理的訂單數(shù)量是海量的,可以按照一定的規(guī)則水平劃分。需要解決的問題:數(shù)據(jù)路由、組裝。
什么時(shí)候考慮分表?
- 一張表的查詢速度已經(jīng)慢到影響使用的時(shí)候。
- sql經(jīng)過優(yōu)化
- 數(shù)據(jù)量大
- 當(dāng)頻繁插入或者聯(lián)合查詢時(shí),速度變慢
分表解決的問題
分表后,單表的并發(fā)能力提高了,磁盤I/O性能也提高了,寫操作效率提高了
- 查詢一次的時(shí)間短了
- 數(shù)據(jù)分布在不同的文件,磁盤I/O性能提高
- 讀寫鎖影響的數(shù)據(jù)量變小
- 插入數(shù)據(jù)庫(kù)需要重新建立索引的數(shù)據(jù)減少
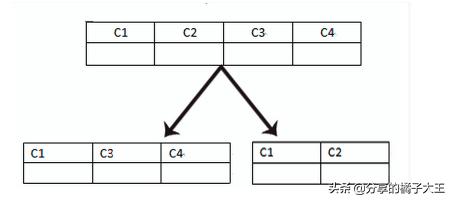
垂直分表
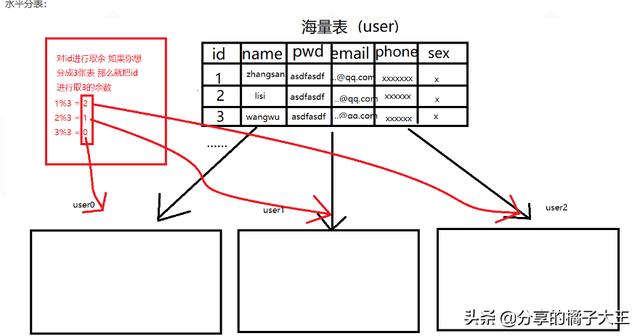
水平分表
存儲(chǔ)演變:
單庫(kù)單表
單庫(kù)單表是最常見的數(shù)據(jù)庫(kù)設(shè)計(jì),例如,有一張用戶(user)表放在數(shù)據(jù)庫(kù)db中,所有的用戶都可以在db庫(kù)中的user表中查到。
單庫(kù)多表
隨著用戶數(shù)量的增加,user表的數(shù)據(jù)量會(huì)越來越大,當(dāng)數(shù)據(jù)量達(dá)到一定程度的時(shí)候?qū)ser表的查詢會(huì)漸漸的變慢,從而影響整個(gè)DB的性能。如果使用mysql, 還有一個(gè)更嚴(yán)重的問題是,當(dāng)需要添加一列的時(shí)候,mysql會(huì)鎖表,期間所有的讀寫操作只能等待。
可以通過某種方式將user進(jìn)行水平的切分,產(chǎn)生兩個(gè)表結(jié)構(gòu)完全一樣的user_0000,user_0001等表,user_0000 + user_0001 + …的數(shù)據(jù)剛好是一份完整的數(shù)據(jù)。
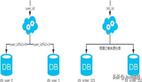
多庫(kù)多表
隨著數(shù)據(jù)量增加也許單臺(tái)DB的存儲(chǔ)空間不夠,隨著查詢量的增加單臺(tái)數(shù)據(jù)庫(kù)服務(wù)器已經(jīng)沒辦法支撐。這個(gè)時(shí)候可以再對(duì)數(shù)據(jù)庫(kù)進(jìn)行水平拆分。
數(shù)據(jù)庫(kù)額外小知識(shí):
MySQL 使用自增ID主鍵和UUID 作為主鍵的優(yōu)劣比較詳細(xì)過程(從百萬到千萬表記錄測(cè)試)
(1)單實(shí)例或者單節(jié)點(diǎn)組:
經(jīng)過500W、1000W的單機(jī)表測(cè)試,自增ID相對(duì)UUID來說,自增ID主鍵性能高于UUID,磁盤存儲(chǔ)費(fèi)用比UUID節(jié)省一半的錢。所以在單實(shí)例上或者單節(jié)點(diǎn)組上,使用自增ID作為首選主鍵。
(2)分布式架構(gòu)場(chǎng)景:
20個(gè)節(jié)點(diǎn)組下的小型規(guī)模的分布式場(chǎng)景,為了快速實(shí)現(xiàn)部署,可以采用多花存儲(chǔ)費(fèi)用、犧牲部分性能而使用UUID主鍵快速部署;
20到200個(gè)節(jié)點(diǎn)組的中等規(guī)模的分布式場(chǎng)景,可以采用自增ID+步長(zhǎng)的較快速方案。
200以上節(jié)點(diǎn)組的大數(shù)據(jù)下的分布式場(chǎng)景,可以借鑒類似twitter雪花算法構(gòu)造的全局自增ID作為主鍵。