分庫分表,讀寫分離后,數據庫中間件扮演了一個怎樣的角色?
分庫分表,讀寫分離會帶來哪些問題?
前面一篇文章圖解分布式系統架構(看推薦閱讀)大概講了一下分庫分表,以及讀寫分離出現的場景,分庫分表為了解決高并發和海量數據的問題。
分庫后會出現新的問題
1、跨庫join問題
如有2個庫,訂單庫,用戶庫,要查詢買了某件商品的所有用戶信息
2、事務問題
用戶下訂單的時候需要扣減商品庫存,如果訂單數據和商品數據在一個數據庫中,我們可以使用事務來保證扣減商品庫存和生成訂單的操作要么都成功要么都失敗,但分庫后就無法使用數據庫事務了,這時就要用到分布式事務了
分表后也會出現新的問題
1、join操作
水平分表后,數據分散在多個表中,如果需要與其他表進行join查詢,需要在業務代碼或數據庫中間件中進行多次join查詢,然后將結果合并
2、count()操作
業務代碼或者數據庫中間件對每個表進行count(*)操作,然后將結果相加。或者新建一張表,假如表名為“記錄數表”,包含table_name和row_count兩個字段,每次插入或刪除子表數據成功后,都更新“記錄數表”
3、order by操作
水平分表后,數據分散到多個字表中,排序操作無法再數據庫中完成,只能由業務代碼或數據庫中間件分別查詢每個子表中的數據,然后匯總進行排序
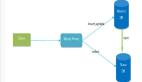
而高并發這個階段,肯定是需要做讀寫分離的,啥意思?因為實際上大部分的互聯網公司,一些網站,或者是 app,其實都是讀多寫少。所以針對這個情況,就是寫一個主庫,但是主庫掛多個從庫,然后從多個從庫來讀,那不就可以支撐更高的讀并發壓力了嗎?
那么如何實現 MySQL 的讀寫分離?
其實很簡單,就是基于主從復制架構,簡單來說,就搞一個主庫,掛多個從庫,然后我們就單單只是寫主庫,然后從庫讀取bin log進行重放,這樣主庫和從庫數據就一樣,只不過并發量比較高時,會有主從同步延時問題
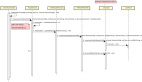
放個圖理解一下MySQL主從復制的原理,這塊面試經常被問到
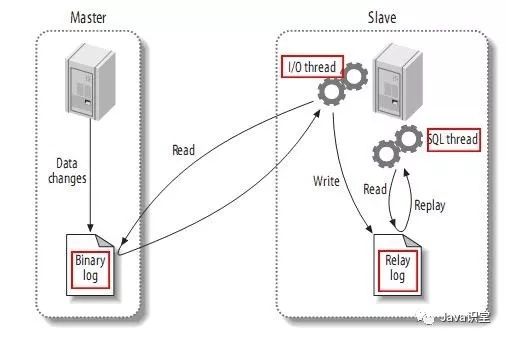
總的來說,MySQL復制有三個步驟
1、在主庫上把數據更改記錄到二進制日志中(Binary Log)中(這些記錄被稱為二進制日志事件)
2、備庫將主庫上的日志復制到自己的中繼日志(Relay Log)中
3、備庫讀取中繼日志中的事件,將其重放到備庫數據之上
現在理論知識都有了,就剩怎么實現了?本來就是為了實現一個功能,現在好了,單寫讀寫分離,跨庫join,分布式事務,排序操作等就夠你忙的了。
這時候你就應該想起數據庫中間件了,它能幫你進行上述操作,把你從復雜的數據處理中解放出來,專注于開發業務代碼。
數據庫中間件能幫你做什么?
目前國內用的最多的中間件就是sharding-jdbc,mycat,別的用的很少,不再介紹
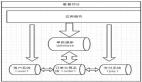
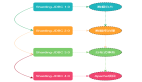
而數據庫中間件針對數據源管理,目前主要有兩種思路
1、客戶端模式,在每個應用程序模塊中配置管理自己需要的一個(或者多個)數據源,直接訪問各個數據庫,在模塊內完成數據的整合,sharding-jdbc的實現方式
2、通過中間代理層來統一管理所有的數據源,后端數據庫集群對前端應用程序透明,mycat的實現方式
放兩張圖就能理解區別了
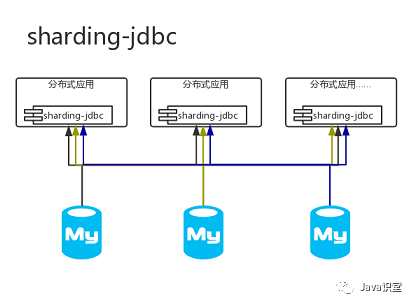

一般的建議是小公司用sharding-jdbc,大公司用mycat,因為維護一套mycat集群也需要人力,物力。鑒于篇幅限制,本文就介紹一下mycat的基本使用
以一個最形象的例子,讓你明白mycat到底幫你做了什么?

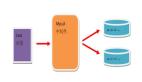
先介紹一下什么是分片?簡單來說,就是通過某種特定的條件,將我們存放在同一個數據庫中的數據,分散存放到多個數據庫上面,以達到分散單臺設備負載的效果
如上圖所表示,數據被分到多個分片數據庫后,應用如果需要讀取數據,就要需要處理多個數據源的數據。如果沒有數據庫中間件,那么應用將直接面對分片集群,數據源切換、事務處理、數據聚合都需要應用直接處理,原本該是專注于業務的應用,將會花大量的工作來處理分片后的問題,最重要的是每個應用處理將是完全的重復造輪子。
所以有了數據庫中間件,應用只需要集中與業務處理,大量的通用的數據聚合,事務,數據源切換都由中間件來處理。
那么數據庫中間件是怎么做到的呢?
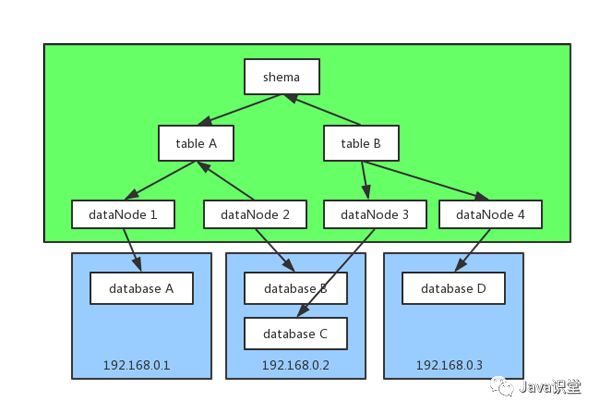
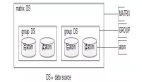
綠色的部分為mycat的邏輯節點,藍色的部分為物理節點(即數據庫的部署地址)
schema:邏輯庫
通常對實際應用來說,并不需要知道中間件的存在,業務開發人員只需要知道
數據庫的概念,所以數據庫中間件可以被看做是一個或多個數據庫集群構成的邏輯庫
table:邏輯表
既然有邏輯庫,那么就會有邏輯表,分布式數據庫中,對應用來說,讀寫數據的表就是邏輯表。邏輯表,可以是數據切分后,分布在一個或多個分片庫中,也可以不做數據切分,不分片,只有一個表構成
datanode:分片節點
數據切分后,一個大表被分到不同的分片數據庫上面,每個表分片所在的數據庫就是分片節點
datahost:節點主機(上圖藍色節點)
數據切分后,每個分片節點(dataNode)不一定都會獨占一臺機器,同一機器上面可以有多個分片數據庫,這樣一個或多個分片節點(dataNode)所在的機器就是節點主機(dataHost),為了規避單節點主機并發數限制,盡量將讀寫壓力高的分片節點(dataNode)均衡的放在不同的節點主機(dataHost)。
rule:分片規則
前面講了數據切分,一個大表被分成若干個分片表,就需要一定的規則,這樣按照某種業務規則把數據分到某個分片的規則就是分片規則,數據切分選擇合適的分片規則非常重要,將極大的避免后續數據處理的難度。
實戰Mycat
為了快速熟悉各種配置,一般直接從git上下載代碼,本地用idea打開啟動,方便練習一波,小編演示本文就是用的這種方法
mycat的配置其實是蠻簡單的,最主要的是熟悉各配置文件的規則。如用戶名,密碼,分片規則,都是在配置文件中定義的
關于配置文件,conf目錄下主要以下三個需要熟悉,要是本地測試用idea打開在resources目錄下
小編演示一個最簡單的映射配置,找一個數據庫服務器,建立3個庫,db1,db2,db3,把id為0-500 0000的數據放在db1,id為500 0001到1000 0000的數據放在db2,以此類推
server.xml是Mycat服務器參數調整和用戶授權的配置文件(省略了一些配置,后面2個配置文件一樣)
- <mycat:server xmlns:mycat="http://io.mycat/">
- <user name="root" defaultAccount="true">
- <property name="password">123456</property>
- <property name="schemas">TESTDB</property>
- </user>
- </mycat:server>
schema.xml是邏輯庫,邏輯表定義以及分片定義的配置文件
- <mycat:schema xmlns:mycat="http://io.mycat/">
- <!--邏輯庫名-->
- <schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100">
- <!--rule的值和rule.xml的實現對應-->
- <table name="tb_test" dataNode="dn1,dn2,dn3" rule="auto-sharding-long" />
- </schema>
- <!--dataHost可以配置不同主機上的數據庫,這里為了演示就配置了一個主機上的不同數據庫-->
- <dataNode name="dn1" dataHost="localhost1" database="db1" />
- <dataNode name="dn2" dataHost="localhost1" database="db2" />
- <dataNode name="dn3" dataHost="localhost1" database="db3" />
- <dataHost name="localhost1" maxCon="1000" minCon="10" balance="0"
- writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
- <!--心跳語句-->
- <heartbeat>select user()</heartbeat>
- <!--這里我本地mycat配了一個遠程mysql-->
- <writeHost host="hostM1" url="遠程mysql的ip地址:3306" user="root"
- password="2014">
- </writeHost>
- </dataHost>
- </mycat:schema>
rule.xml是分片規則的配置文件
- <mycat:rule xmlns:mycat="http://io.mycat/">
- <tableRule name="auto-sharding-long">
- <rule>
- <!--根據哪個列進行分片-->
- <columns>id</columns>
- <!--分片規則,連續分片-->
- <algorithm>rang-long</algorithm>
- </rule>
- </tableRule>
- <function name="rang-long"
- <!--分片規則的實現類-->
- class="io.mycat.route.function.AutoPartitionByLong">
- <!--分片規則配置文件-->
- <property name="mapFile">autopartition-long.txt</property>
- </function>
- </mycat:rule>
autopartition-long.txt詳細的分片策略
- # range start-end ,data node index
- # K=1000,M=10000.
- 00-500M=0
- 500M-1000M=1
- 1000M-1500M=2
這個配置的意思是,id在0到500w放在***個分片,以此類推
小編這里用Navicat(數據庫連接工具)連接到本地的mycat
主機:localhost
端口:8066
用戶名:root(server.xml中配置好的用戶名密碼)
密碼:123456
看到有一個TestDB庫,在這個庫里面執行建表語句
- CREATE TABLE `tb_test` (
- `id` int(11) NOT NULL,
- `name` varchar(255) DEFAULT NULL,
- PRIMARY KEY (`id`)
- ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
然后到對應的物理數據庫db1,db2,db3上看,3個庫都有了這個表。
在邏輯數據庫中插入如下三條數據
- insert into tb_test (id, name) values (1, "1");
- insert into tb_test (id, name) values (5000001, "5000001");
- insert into tb_test (id, name) values (10000001, "10000001");
可以看到id為1的數據插入到物理數據庫中的db1,id為5000001的數據插入到db2,id為10000001的數據插入到db3
在邏輯數據庫中執行如下語句又能拿到這3條記錄
- select id, name from tb_test
執行如下語句,可以看到mycat從三個數據庫中取了記錄,LIMIT 100是因為schema.xml中配置了sqlMaxLimit=“100”
- explain select id, name from tb_test
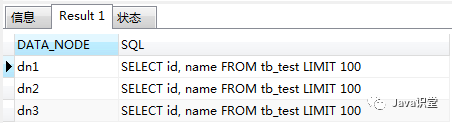
有了mycat以后,我們的數據庫地址配置成mycat即可,它幫我們做了很多,其他各種分片規則,讀寫分離等的配置就不再演示,理解整個框架的大概運行流程就行
***再分享一個知識點,mycat1.5 開始會支持本地 xml 啟動,以及從 zookeeper 加載配置轉為本地 xml 的兩種方式,即原來分享的zookeeper可以用作配置中心