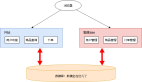
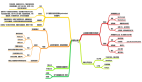
阿里是如何抗住雙11的?看完這篇你就明白了!
我從業之初便開始扮演“救火隊員”角色,經常去線上執行“救火”、止損、攻關等應急工作,再通過分析、推理、驗證…
“抽絲剝繭”的找出背后的根本原因,仿佛自己是個“經驗豐富、從容冷靜、思維縝密”的偵探。
以前我一直認為線上問題定位、分析處理能力是架構師的“看家功底”并常引以為傲。
但最近這兩年我開始思考,其實“防火”比“救火”更重要,正如一句古話“上醫治未病,中醫治欲病,下醫治已病”。下面我將為大家分享穩定性治理經驗和阿里的穩定性保障體系。
閱讀本文,你將會收獲:
- 高并發、大流量場景的常見問題和應對手段
- 知名互聯網公司的高可用架構和穩定性保障體系
穩定性治理的常見場景
突發大流量
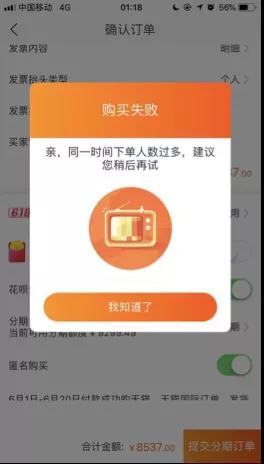
相信大家對上圖并不陌生,尤其在剛剛過去的雙 11、雙 12 中。這是電商大促場景中執行了最常用的自動預案 - “限流保護”,并非很多朋友說的“宕機”、“崩潰”。

“限流”是應對高并發或者突發大流量場景下的“三板斧”之一,不管是在電商大促、社交媒體突發熱點事件(例如:遇到“知名女星出軌”),還是在常態下都是非常有必要的保護手段。
本質上就是檢查到當前請求量即將超出自身處理能力時,自動執行拒絕(或者執行“請求排隊”),從而防止系統被徹底壓垮。
不穩定服務

講到“限流”,那就不得不提另外一板斧“降級”。除了我們之前所提到的 “開關降級”(關閉次要功能或服務)、兜底、降低一致性等之外,在技術層面最常用就是“自動熔斷降級”。
“限流”是為了防止大流量壓垮系統,而“熔斷”是為了防止不穩定的服務引發超時或等待,從而級聯傳遞并最終導致整個系統雪崩。
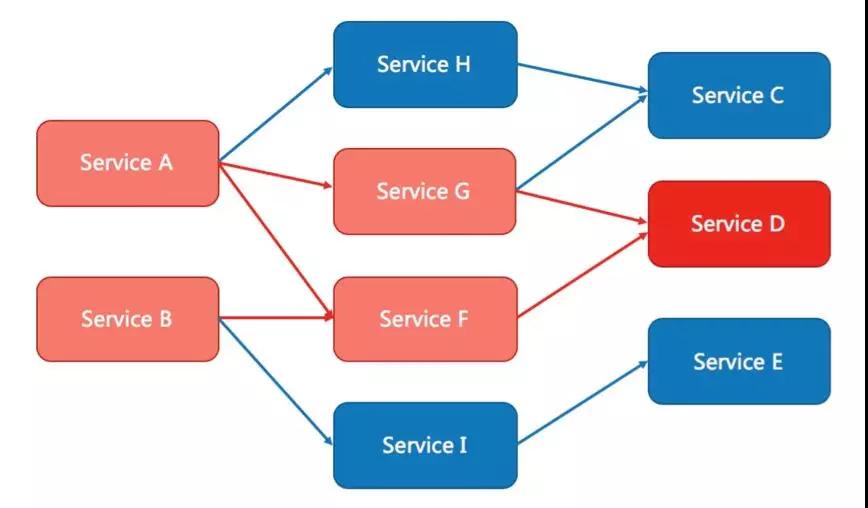
如圖所示,假設服務 D 此時發生了故障或者 FullGC 等,則會導致上游的服務 G、F 中產生大量等待和異常,并級聯傳遞給最上游的服務 A、B。
即便在服務 G、F 中設置了“超時”(如果沒有設置“超時”那情況就更糟糕了),那么也會導致線程池中的大量線程資源被占用。
如果服務 H、I 和服務 G、F 在同一個應用中且默認共用同一個線程池,那么也會因為資源耗盡變得不可用,并最終導致最上游的服務 A 和服務 B 整體不可用,全部鏈路都將異常,線上核心系統發生這種事故那就是災難。
假如我們在檢查到服務 G 和服務 F 中 RT 明顯變長或者異常比例增加時,能夠讓其自動關閉并快速失敗,這樣 H 和 I 將不會受影響,最上游的服務 A 和服務 B 還能保證“部分可用”。
舉個現實生活中更通俗的例子,當你們家的電器發生短路時空氣開關會自動跳閘(保險絲會自動 “熔斷”)。
這就是通過犧牲你們家的用電而換回小區的正常供電,否則整個線路都會燒毀,后果會不堪設想。
所以,你得結合實際業務場景先找出哪些接口、服務是可以被“降級”的。
架構單點
這個事件大概發生在 2015 年,被載入了支付寶的“史冊”,也推動了螞蟻金服整體 LDC 架構(三地五中心的異地多活架構)的演進。
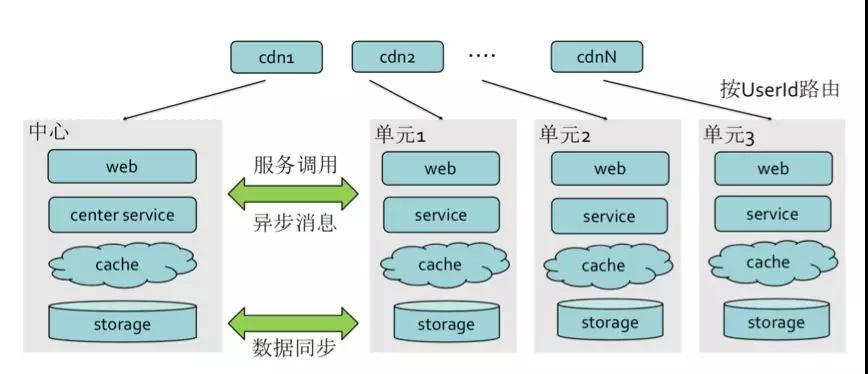
異地多活架構:
- 突破單機房容量限制
- 防機房單點,高可用
內建質量
根據以往的經驗,60% 以上的故障都是由變更引起的,請牢記變更“三板斧”:
- 可回滾/可應急
- 可灰度
- 可監控
預防質量事故的常用手段:
- 做好分析、設計、評審,容量評估,規避風險
- 制定規范,控制流程,加入代碼掃描和檢查等
- 閹割做好 Code Review
- 測試用例覆蓋(通過率、行覆蓋率、分支覆蓋率),變更全量回歸
- 盡可能的自動化,避免人肉(易出錯),關鍵時刻執行 Double Check
高可用架構的基石:穩定性保障體系
從故障視角來看穩定性保障,如下圖:
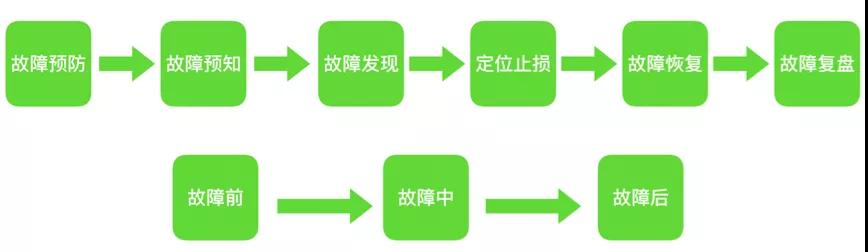
穩定性保障的核心目標如下:
- 盡早的預防故障,降低故障發生幾率。
- 及時預知故障,發現定義故障。
- 故障將要發生時可以快速應急。
- 故障發生后能快速定位,及時止損,快速恢復。
- 故障后能夠從中吸取教訓,避免重復犯錯。
仔細思考一下,所有的穩定性保障手段都是圍繞這些目標展開的。
穩定性保障體系
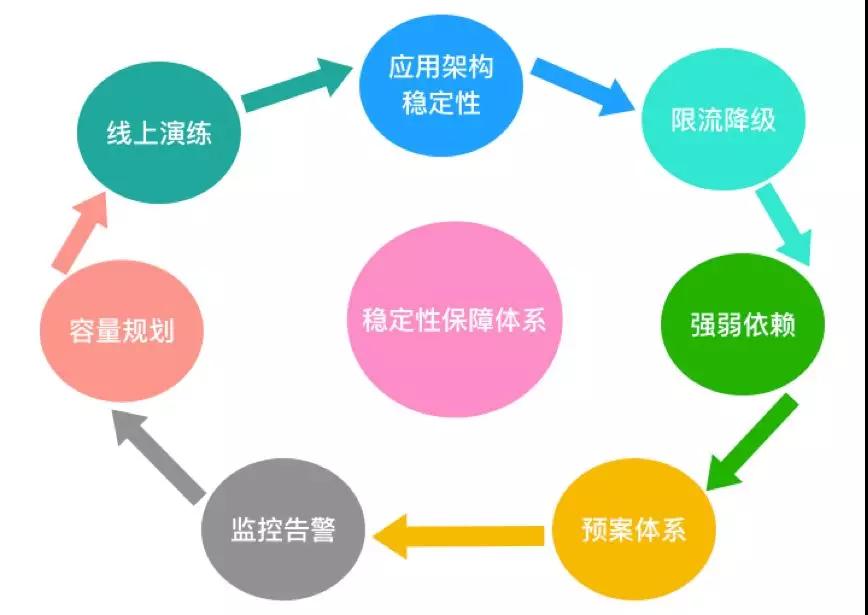
上圖涵蓋了穩定性體系的各個方面,下面我來一一講解。
應用架構穩定性
應用架構穩定性相對是比較廣的話題,按我的理解主要包括很多設計原則和手段:
①架構設計簡單化。系統架構簡單清晰,易于理解,同時也需要考慮到一定的擴展性,符合軟件設計中 KISS 原則。
現實中存在太多的“過度設計”和“為了技術而技術”,這些都是反例,架構師需懂得自己權衡。
②拆分。拆分是為了降低系統的復雜度,模塊或服務“自治”,符合軟件設計中“單一職責”原則。拆分的太粗或者太細都會有問題,這里沒有什么標準答案。
應該按照領域拆分(感興趣同學可以學習下 DDD 中的限界上下文),結合業務復雜程度、團隊規模(康威定律)等實際情況來判斷。可以想象 5 個人的小團隊去維護超過 30 多個系統,那一定是很痛苦的。
③隔離。拆分本質上也是一種系統級、數據庫級的隔離。此外,在應用內部也可以使用線程池隔離等。分清“主、次”,找出“高風險”的并做好隔離,可以降低發生的幾率。
④冗余。避免單點,容量冗余。機房是否單點,硬件是否單點,應用部署是否單點,數據庫部署是否單點,鏈路是否單點…硬件和軟件都是不可靠的,冗余(“備胎”)是高可用保障的常規手段。
⑤無狀態、一致性、并發控制、可靠性、冪等性、可恢復性…等。比如:投遞了一個消息,如何保障消費端一定能夠收到?上游重試調用了你的接口,保證數據不會重復?Redis 節點掛了分布式鎖失效了怎么辦?…這些都是在架構設計和功能設計中必須考慮的。
⑥盡可能的異步化,盡可能的降低依賴。異步化某種程度可以提升性能,降低 RT,還能減少直接依賴,是常用的手段。
⑦容錯模式。
我在團隊中經常強調學會“面向失敗和故障的設計”,盡可能做一個“悲觀主義者”,或許有些同學會不屑的認為我是“杞人憂天”,但事實證明是非常有效的。
從業以來我有幸曾在一些高手身邊學習,分享受益頗多的兩句話:
- 出來混,遲早要還的
- 不要心存僥幸,你擔心的事情遲早要發生的
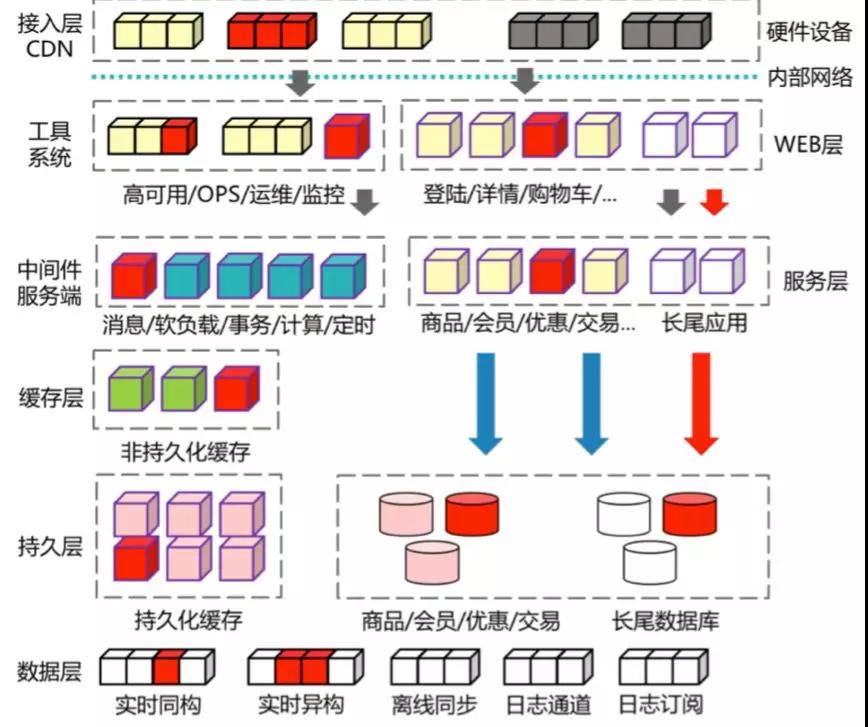
上圖是比較典型的互聯網分布式服務化架構,如果其中任意紅色的節點出現任何問題,確定都不會影響你們系統正常運行嗎?
限流降級
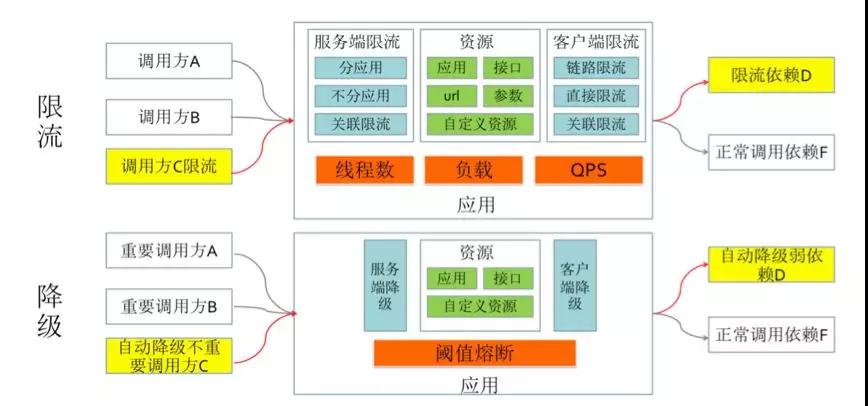
前面介紹過了限流和降級的一些場景,這里簡單總結下實際使用中的一些關鍵點。
以限流為例,你需要先問自己并思考一些問題:
- 你限流的實際目的是什么?僅僅只做過載保護?
- 需要什么限流策略,是“單機限流”還是“集群限流”?
- 需要限流保護的資源有哪些?網關?應用?
- 水位線在哪里?限流閾值配多少?
- …
同理,降級你也需要考慮:
- 系統、接口依賴關系
- 哪些服務、功能可以降級掉
- 是使用手工降級(在動態配置中心里面加開關)還是自動熔斷降級?熔斷的依據是什么?
- 哪些服務可以執行兜底降級的?怎么去兜底(例如:掛了的時候走緩存或返回默認值)?
- …
這里我先賣下關子,篇幅關系,下篇文章中我會專門講解。
監控預警

上圖是我個人理解的一家成熟的互聯網公司應該具備的監控體系。前面我提到過云原生時代“可觀察性”,也就是監控的三大基石。
這里再簡單補充一下 “健康檢查”,形成經典的“監控四部曲”:
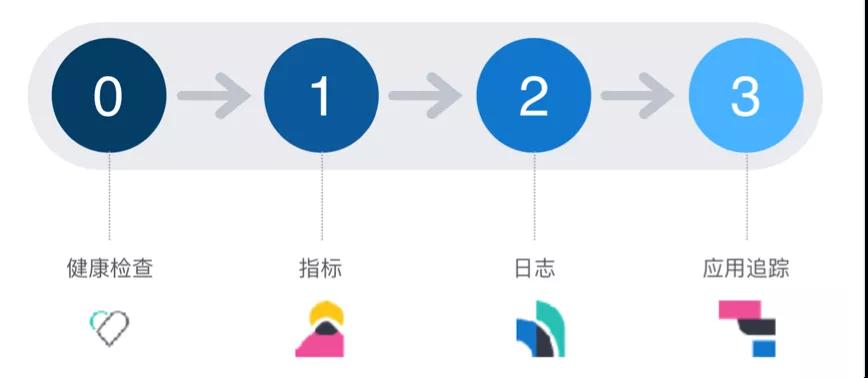
關于健康檢查,主要就分為“服務端輪詢”和“客戶端主動上報”兩種模式,總的來講各有優缺點,對于類似 MySQL 這類服務是無法主動上報的(除非借助第三方代理)。需要注意的是傳統基于端口的健康檢查很難識別“進程僵死”的問題。

提到監控那就不得不提 Google SRE 團隊提出的監控四項黃金指標:
- 延遲:響應時間
- 流量:請求量、QPS
- 錯誤:錯誤數、錯誤率
- 飽和度:資源利用率
類似的還有 USE 方法,RED 方法,感興趣的讀者可以自行查閱相關資料。
云原生時代通常是應用/節點暴露端點,監控服務端采用 Pull 的方式采集指標,當前比較典型的就是 Prometheus 監控系統,感興趣的可以詳細了解。
當然,以前也有些監控是通過 Agent 采集指標數據然后上報到服務端的。
除了監控自身,告警能力也是非常重要的。告警的閾值配多少也需要技巧,配太高了不靈敏可能會錯過故障,配太低了容易“監控告警疲勞”。
強弱依賴治理

這是網上找的一張“系統依賴拓撲圖”,可見面對這種復雜性,無論是通過個人經驗,還是借助“鏈路跟蹤工具”都很難快速理清的。
何為強弱依賴?A 系統需要借助 B 系統的服務完成業務邏輯,當 B 掛掉的時候會影響 A 系統中主業務流程的推進,這就是“強依賴”。
舉個例子:下單服務依賴“生成訂單號”,這就是“強依賴”,“扣庫存”這也是 “強依賴”。
同理,當 A 依賴的 B 系統掛掉的時候,不會影響主流程推進,那么就是“弱依賴”。例如:購物車頁面中顯示的庫存數是非必須的。
如何梳理出這種強弱依賴,這個在阿里內部是有專門的中間件可以做的,目前開源社區沒有替代品,可能就要結合鏈路跟蹤+個人的經驗,針對系統級,接口級去做鏈路梳理。
我們重點關注的是 “強依賴”,而“弱依賴” 通常是可以執行容災策略的,例如:可以直接降級掉,可以返回為空或者默認值、執行兜底等。
總結出來關鍵有幾點:當前業務功能/應用/服務、依賴的服務描述、依賴類型(比如:RPC 調用),峰值調用量、鏈路的流量調用比例、強弱等級、掛掉的后果等。
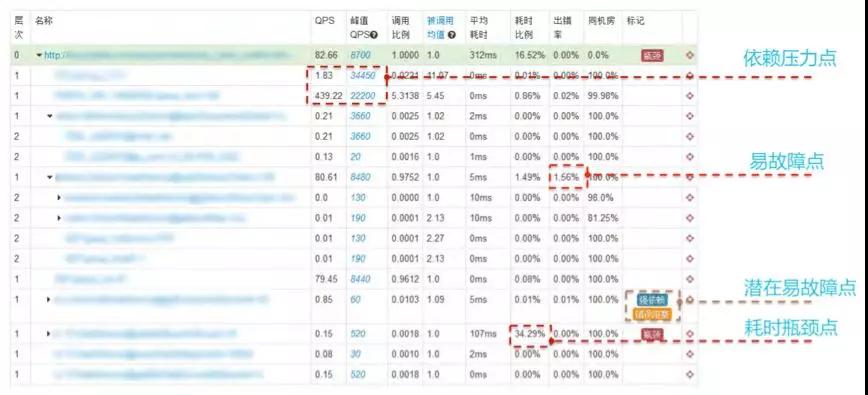
容量規劃
容量規劃是非常重要的,無論是成本控制還是穩定性保障都需要。否則壓根不知道需要投入多少資源以及資源投入到哪里。
需要了解系統極限水位在哪里,再推算出合理的“閾值”來做好“過載保護”,這也是執行是限流、降級等預案體系的關鍵依據和基礎。
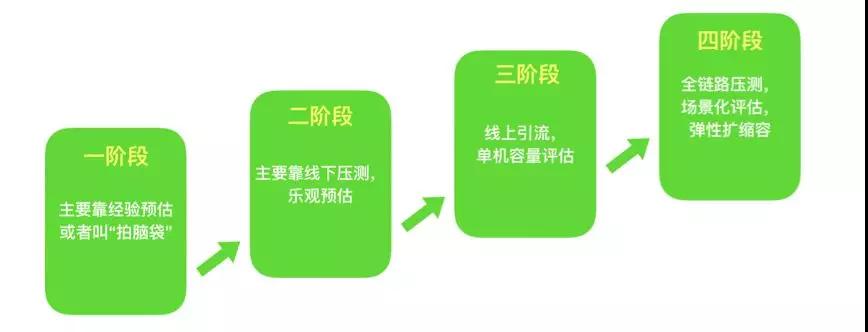
第一階段:主要依靠經驗值、理論值等來預估的,或者是靠“拍腦袋”的
前幾年資本市場情況比較好,互聯網公司比較典型的現象:老板,我需要買 100 臺服務器,50 臺跑應用,20 臺跑中間件,10 臺做數據庫…預計可以扛住日均 1000W 訪問量,每天 100W 訂單…
靠譜一點的人還能扯出 “MySQL 并發連接數在幾 core 幾 G 大概能到 xxx”、 “Redis 官方稱可以達到 10W TPS”之類的參考值,這種至少聽起來還有那么一點道理。
不靠譜的人呢?那可能就真是瞎說的一個數字,或者會說“我上家公司就用了這么多支撐的”,其實純靠拍腦袋的。
總之,這都是很不靠譜的,會造成資源分配不合理,有些浪費而有些饑荒。
第二階段:通過線下壓測手段來進行
線下壓測通常是壓測的單接口、單節點,壓測結果可以幫助我們了解應用程序的性能狀況、定位性能瓶頸,但是要說做整體的容量規劃,那參考價值不大。
因為實際情況往往復雜太多,網絡帶寬、公共資源、覆蓋場景不一致、線上多場景混合等各種因素。
根據“木桶短板”的原理,系統的容量往往取決于最弱的那一環節。正所謂 “差之毫厘,失之千里”。
第三階段:通過線上單機壓測來做
比較常見的手段有:線上引流、流量復制、日志回放等。其中線上引流實施起來最簡單,但需要中間件統一。
通過接入層或服務注冊中心(軟負載中心)調整流量權重和比例,將單機的負載打到極限。這樣就比較清楚系統的實際水位線在哪里了。
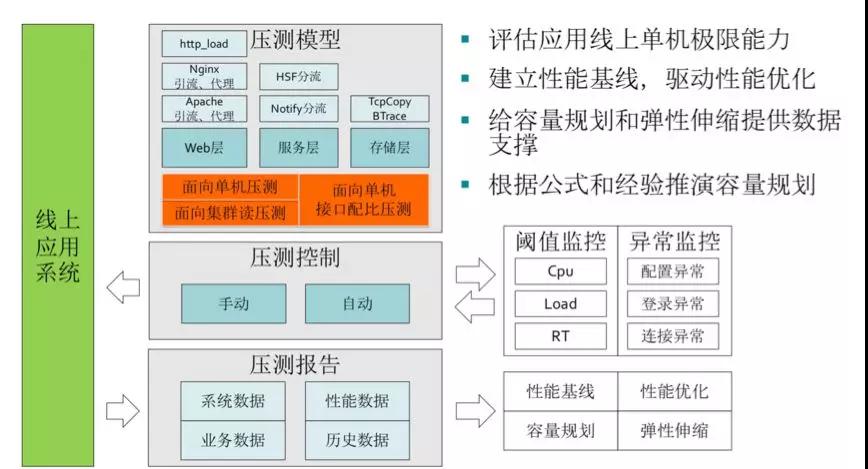
第四階段:全鏈路壓測,彈性擴容
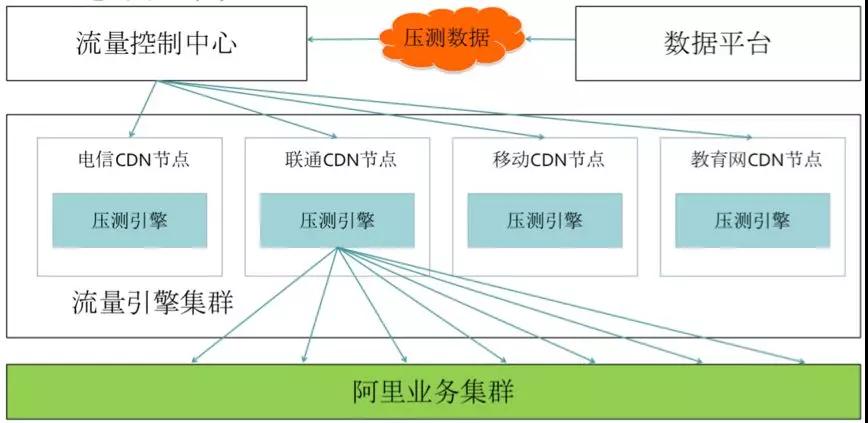
這個是阿里首創的,目前很多公司在效仿。屬于是業務倒逼技術創造出來的手段。
全鏈路壓測涉及到的內容會比較多,關鍵的步驟包括:
- 鏈路梳理
- 基礎數據準備、脫敏等
- 中間件改造(透傳影子標,軟負載/消息/緩存/分庫分表等路由,建立影子表)
- 建立壓測模型、流量模型、流量引擎
- 預案體系的檢查
- 執行壓測,緊盯監控告警
- 數據清理
對業務開發團隊同學來講,關于鏈路梳理、流量模型的評估是其中最重要的環節,全鏈路壓測就是模擬用戶真實的訪問路徑構造請求,對生產環境做實際演練。
這里我以大家熟悉的購買電影票的場景為例。如下圖,整個鏈路中業務流量其實是呈“漏斗模型”的,至于每一層的比例是多少,這個第一就是參考當前的監控,第二就是參考歷史數據去推算平均值了。
漏斗模型推演示例:
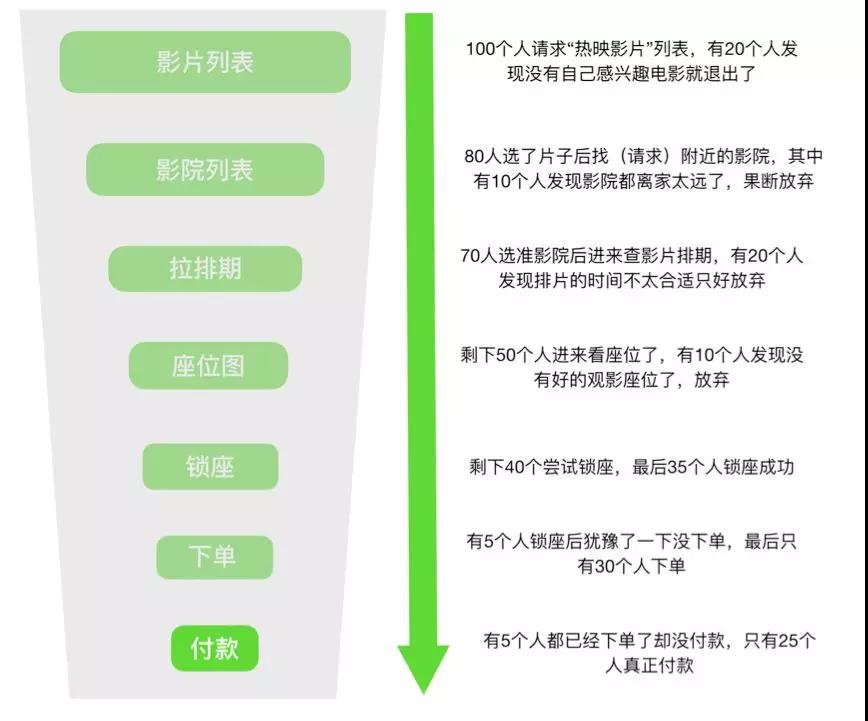
可以看出每一層(不同應用、不同服務)所需要承載的真實流量不一樣,負載也是不一樣的。
當然,實際場景更復雜,實際情況是多場景混合并行的,A 用戶在拉排期的時候 B 用戶已經在鎖座了…
我們要做的,就是盡可能接近真實。還有最關鍵的一點要求:不能影響線上真實業務。這就需要非常強的監控告警和故障隔離能力了。
關于系統容量和水位標準,這里給大家一個建議參考值:
- 水位標準:單機房部署水位應在 70% 以下,雙機房部署水位應在 40% 以下
- 單機水位:單機負載 / 單機容量
- 集群水位:集群負載 / 集群容量
- 理論機器數:實際機器數 *(集群水位 / 水位標準)
為什么雙機房是 40%?一個機房故障了流量全都切到另外一個機房去,要確保整體不受影響,不會被壓垮。
預案體系
電影片段中 “檢查到有未知生物入侵地球,聯合國宣布啟動進入一級戒備,馬上啟動宇宙飛船達到現場” ,“已經了解清楚,并按協議執行驅逐指令,目前已經離開” … 這就是典型的預案體系。
觸發條件、等級、執行動作、事后情況都非常清晰,整個過程還帶有閉環的(當然這片段是我 YY 出來的)。
前面我講過“面向失敗的設計”,就是盡可能的考慮到各種異常場景和特殊情況。
這些零散的“知識點”,還有日常的一些復盤的經驗都可以作為日后的預案。
當然,前面我們講過的限流、降級等應急手段,容錯模式也是整個預案體系中非常重要的。預案積累的越豐富,技術往往越成熟。
總的來講,預案的生命周期包括:
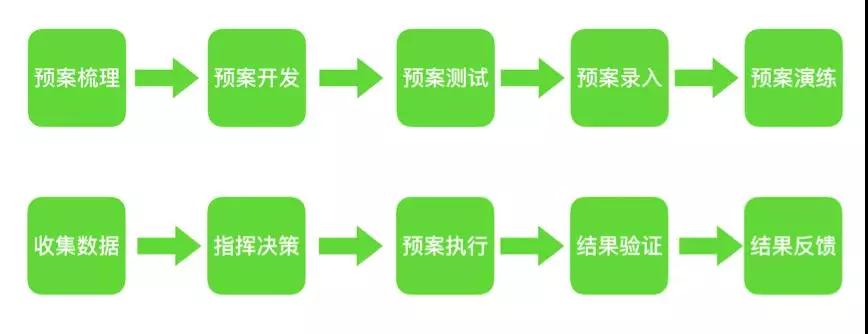
從大的層面又可以分為:
- 事前制定和完善預案
- 日常演練預案
- 事中統一指揮,收集數據,決策并執行預案
- 事后總結并繼續完善和改進預案
當然,這里說明下,有些預案是達到明確的觸發條件后自動執行的,有些是需要依賴人工決策然后再觸發執行的。
這里我給一個簡單的 Demo 給大家參考:
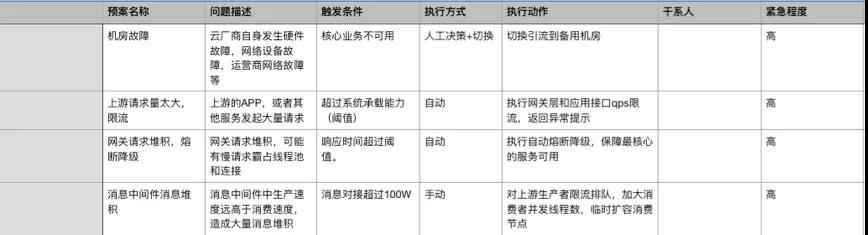
線上演練
正所謂 “養兵千日,用兵一時”。現實生活中的“消防演習”就是一個好例子,否則時間久了根本不知道滅火器放在哪里,滅火器是怎么打開的?
打開后還能噴出泡沫來嗎?對應到我們技術領域也是一樣的,你怎么知道你的預案都是有效的?你怎么保證 on call 值班機制沒問題?你怎么知道監控告警真的很靈敏?
在阿里內部不管是大促還是常態,都會不定期來一些線上演練。在螞蟻內部每年都會有“紅藍軍對抗演練”,這是一種非常好的“以戰養兵”的做法。
先看一張關于故障畫像的大圖,這里列舉了典型的一些故障場景,大家不妨思考下如何通過“故障注入”來驗證系統的高可用能力。
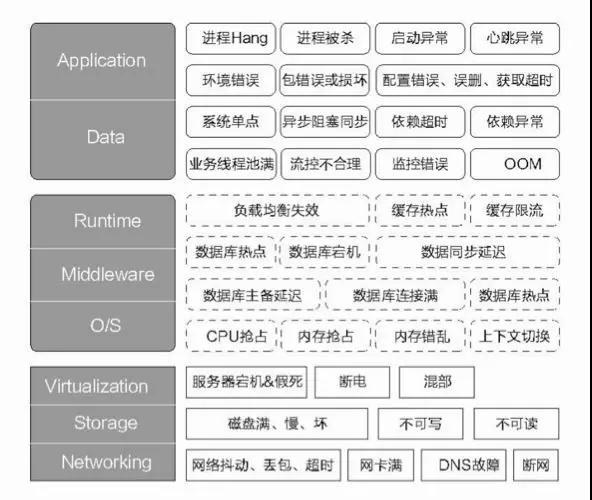
簡單總結故障演練主要場景和目的:
- 預案有效性、完整性
- 監控告警的準確性、時效性
- 容災能力測試
- 檢查故障是否會重現
- 檢查 on call 機制,驗證突發情況團隊實際戰斗能力
- …
“混沌工程”是近年來比較流行的一種工程實踐,概念由 Netflix 提出,Google、阿里在這方面的實踐經驗比較豐富(或者說是不謀而合,技術頂尖的公司大都很相似)。
通俗點來講就是通過不斷的給現有系統“找亂子”(進行實驗),以便驗證和完善現有系統的高可用性、容錯性等。
引用一句雞湯就是:“殺不死我的必將使我更強大”,混沌工程的原則:
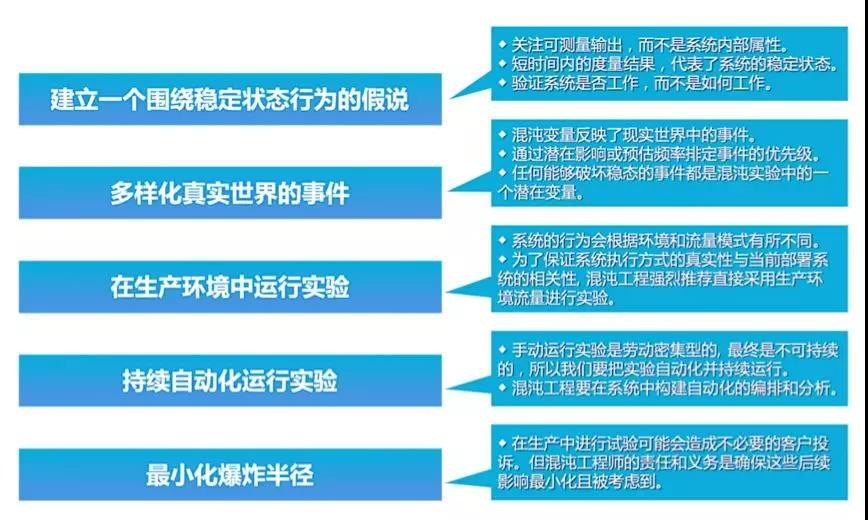
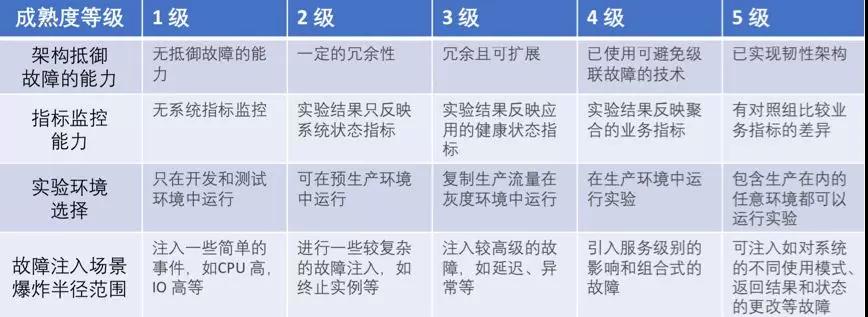
系統成熟度模型:
面向故障/失敗的設計更是一種技術文化,應該在團隊中大力推廣。
小結
本文我主要講解了穩定性治理的常見手段,穩定性保障體系。其中涉及到的知識、手段、內容都非常多。
限于篇幅的關系,不可能每一項都特別細致。還需讀者慢慢消化,更重要的是好好思考現狀并努力改進,也歡迎留言討論。
作者:丁浪
簡介:目前在創業公司擔任高級技術架構師。曾就職于阿里巴巴大文娛和螞蟻金服。具有豐富的穩定性保障,全鏈路性能優化的經驗。架構師社區特邀嘉賓!