大到阿里,小到三線公司,緩存在大型分布式系統(tǒng)中的應(yīng)用
一、緩存概述
緩存是分布式系統(tǒng)中的重要組件,主要解決高并發(fā),大數(shù)據(jù)場(chǎng)景下,熱點(diǎn)數(shù)據(jù)訪問的性能問題。提供高性能的數(shù)據(jù)快速訪問。
1、緩存的原理
- 將數(shù)據(jù)寫入/讀取速度更快的存儲(chǔ)(設(shè)備);
- 將數(shù)據(jù)緩存到離應(yīng)用最近的位置;
- 將數(shù)據(jù)緩存到離用戶最近的位置。
2、緩存分類
在分布式系統(tǒng)中,緩存的應(yīng)用非常廣泛,從部署角度有以下幾個(gè)方面的緩存應(yīng)用。
- CDN緩存;
- 反向代理緩存;
- 分布式Cache;
- 本地應(yīng)用緩存;
3、緩存媒介
- 常用中間件:Varnish,Ngnix,Squid,Memcache,Redis,Ehcache等;
- 緩存的內(nèi)容:文件,數(shù)據(jù),對(duì)象;
- 緩存的介質(zhì):CPU,內(nèi)存(本地,分布式),磁盤(本地,分布式)
4、緩存設(shè)計(jì)
緩存設(shè)計(jì)需要解決以下幾個(gè)問題:
緩存什么?
哪些數(shù)據(jù)需要緩存:1.熱點(diǎn)數(shù)據(jù);2.靜態(tài)資源。
緩存的位置?
CDN,反向代理,分布式緩存服務(wù)器,本機(jī)(內(nèi)存,硬盤)
如何緩存的問題?
- 過期策略
- 固定時(shí)間:比如指定緩存的時(shí)間是30分鐘;
- 相對(duì)時(shí)間:比如最近10分鐘內(nèi)沒有訪問的數(shù)據(jù);
- 同步機(jī)制
- 實(shí)時(shí)寫入;(推)
- 異步刷新;(推拉)
二、CDN緩存
CDN主要解決將數(shù)據(jù)緩存到離用戶最近的位置,一般緩存靜態(tài)資源文件(頁(yè)面,腳本,圖片,視頻,文件等)。國(guó)內(nèi)網(wǎng)絡(luò)異常復(fù)雜,跨運(yùn)營(yíng)商的網(wǎng)絡(luò)訪問會(huì)很慢。為了解決跨運(yùn)營(yíng)商或各地用戶訪問問題,可以在重要的城市,部署CDN應(yīng)用。使用戶就近獲取所需內(nèi)容,降低網(wǎng)絡(luò)擁塞,提高用戶訪問響應(yīng)速度和命中率。
1、CND原理
CDN的基本原理是廣泛采用各種緩存服務(wù)器,將這些緩存服務(wù)器分布到用戶訪問相對(duì)集中的地區(qū)或網(wǎng)絡(luò)中,在用戶訪問網(wǎng)站時(shí),利用全局負(fù)載技術(shù)將用戶的訪問指向距離最近的工作正常的緩存服務(wù)器上,由緩存服務(wù)器直接響應(yīng)用戶請(qǐng)求。
(1)未部署CDN應(yīng)用前

網(wǎng)絡(luò)請(qǐng)求路徑:
- 請(qǐng)求:本機(jī)網(wǎng)絡(luò)(局域網(wǎng))——》運(yùn)營(yíng)商網(wǎng)絡(luò)——》應(yīng)用服務(wù)器機(jī)房
- 響應(yīng):應(yīng)用服務(wù)器機(jī)房——》運(yùn)營(yíng)商網(wǎng)絡(luò)——》本機(jī)網(wǎng)絡(luò)(局域網(wǎng))
在不考慮復(fù)雜網(wǎng)絡(luò)的情況下,從請(qǐng)求到響應(yīng)需要經(jīng)過3個(gè)節(jié)點(diǎn),6個(gè)步驟完成一次用戶訪問操作。
(2)部署CDN應(yīng)用后
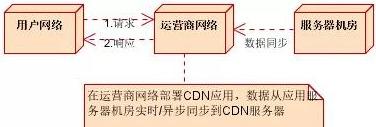
網(wǎng)絡(luò)路徑:
請(qǐng)求:本機(jī)網(wǎng)絡(luò)(局域網(wǎng))——》運(yùn)營(yíng)商網(wǎng)絡(luò)
響應(yīng):運(yùn)營(yíng)商網(wǎng)絡(luò)——》本機(jī)網(wǎng)絡(luò)(局域網(wǎng))
在不考慮復(fù)雜網(wǎng)絡(luò)的情況下,從請(qǐng)求到響應(yīng)需要經(jīng)過2個(gè)節(jié)點(diǎn),2個(gè)步驟完成一次用戶訪問操作。
與不部署CDN服務(wù)相比,減少了1個(gè)節(jié)點(diǎn),4個(gè)步驟的訪問。極大的提高的系統(tǒng)的響應(yīng)速度。
2、CDN優(yōu)缺點(diǎn)
優(yōu)點(diǎn)(摘自百度百科):
本地Cache加速:提升訪問速度,尤其含有大量圖片和靜態(tài)頁(yè)面站點(diǎn)。
鏡像服務(wù):消除了不同運(yùn)營(yíng)商之間互聯(lián)的瓶頸造成的影響,實(shí)現(xiàn)了跨運(yùn)營(yíng)商的網(wǎng)絡(luò)加速,保證不同網(wǎng)絡(luò)中的用戶都能得到良好的訪問質(zhì)量。
遠(yuǎn)程加速:遠(yuǎn)程訪問用戶根據(jù)DNS負(fù)載均衡技術(shù)智能自動(dòng)選擇Cache服務(wù)器,選擇最快的Cache服務(wù)器,加快遠(yuǎn)程訪問的速度。
帶寬優(yōu)化:自動(dòng)生成服務(wù)器的遠(yuǎn)程Mirror(鏡像)cache服務(wù)器,遠(yuǎn)程用戶訪問時(shí)從cache服務(wù)器上讀取數(shù)據(jù),減少遠(yuǎn)程訪問的帶寬、分擔(dān)網(wǎng)絡(luò)流量、減輕原站點(diǎn)WEB服務(wù)器負(fù)載等功能。
集群抗攻擊:廣泛分布的CDN節(jié)點(diǎn)加上節(jié)點(diǎn)之間的智能冗余機(jī)制,可以有效地預(yù)防黑客入侵以及降低各種D.D.o.S攻擊對(duì)網(wǎng)站的影響,同時(shí)保證較好的服務(wù)質(zhì)量。
缺點(diǎn):
- 動(dòng)態(tài)資源緩存,需要注意實(shí)時(shí)性;
解決:主要緩存靜態(tài)資源,動(dòng)態(tài)資源建立多級(jí)緩存或準(zhǔn)實(shí)時(shí)同步;
- 如何保證數(shù)據(jù)的一致性和實(shí)時(shí)性需要權(quán)衡考慮;
解決:
(1)設(shè)置緩存失效時(shí)間(1個(gè)小時(shí),最終一致性);
(2)數(shù)據(jù)版本號(hào);
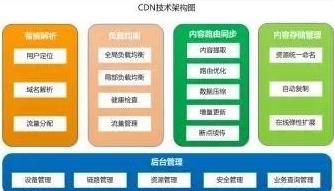
3、CND架構(gòu)參考
4、CND技術(shù)實(shí)踐
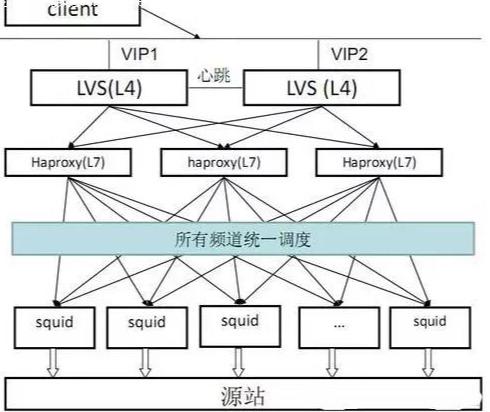
目前,中小型互聯(lián)網(wǎng)公司,綜合成本考慮,一般租用第三方CDN服務(wù),大型互聯(lián)網(wǎng)公司,采用自建或第三方結(jié)合的方式。比如淘寶剛開始使用第三方的,當(dāng)流量很大后,第三方公司無法支撐其CDN流量,淘寶最后采用自建CDN的方式實(shí)現(xiàn)。
淘寶CDN,如下圖(來自網(wǎng)絡(luò)):
三、反向代理緩存
反向代理是指在網(wǎng)站服務(wù)器機(jī)房部署代理服務(wù)器,實(shí)現(xiàn)負(fù)載均衡、數(shù)據(jù)緩存、安全控制等功能。
1、緩存原理
反向代理位于應(yīng)用服務(wù)器機(jī)房,處理所有對(duì)WEB服務(wù)器的請(qǐng)求。如果用戶請(qǐng)求的頁(yè)面在代理服務(wù)器上有緩沖的話,代理服務(wù)器直接將緩沖內(nèi)容發(fā)送給用戶。如果沒有緩沖則先向WEB服務(wù)器發(fā)出請(qǐng)求,取回?cái)?shù)據(jù),本地緩存后再發(fā)送給用戶。通過降低向WEB服務(wù)器的請(qǐng)求數(shù),從而降低了WEB服務(wù)器的負(fù)載。
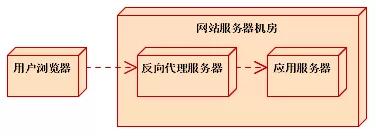
反向代理一般緩存靜態(tài)資源,動(dòng)態(tài)資源轉(zhuǎn)發(fā)到應(yīng)用服務(wù)器處理。常用的緩存應(yīng)用服務(wù)器有Varnish、Ngnix、Squid。
2、Squid示例
Squid 反向代理一般只緩存靜態(tài)資源,動(dòng)態(tài)程序默認(rèn)不緩存。根據(jù)從 WEB 服務(wù)器返回的 HTTP 頭標(biāo)記來緩沖靜態(tài)頁(yè)面。有四個(gè)最重要 HTTP 頭標(biāo)記:
- Last-Modified:告訴反向代理頁(yè)面什么時(shí)間被修改
- Expires:告訴反向代理頁(yè)面什么時(shí)間應(yīng)該從緩沖區(qū)中刪除
- Cache-Control:告訴反向代理頁(yè)面是否應(yīng)該被緩沖
- Pragma用來包含實(shí)現(xiàn)特定的指令,最常用的是 Pragma:no-cache
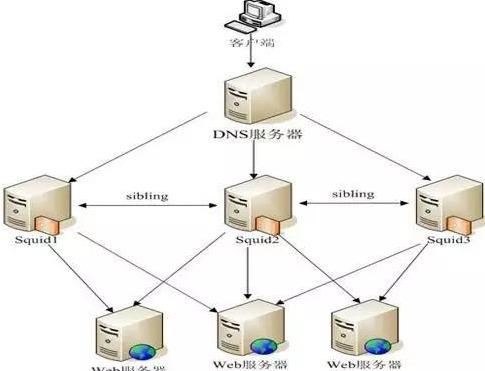
Squid 反向代理加速網(wǎng)站實(shí)例
- 通過DNS的輪詢技術(shù),將客戶端的請(qǐng)求分發(fā)給其中一臺(tái) Squid 反向代理服務(wù)器處理;
- 如果這臺(tái) Squid 緩存了用戶的請(qǐng)求資源,則將請(qǐng)求的資源直接返回給用戶;
- 否則這臺(tái) Squid 將沒有緩存的請(qǐng)求根據(jù)配置的規(guī)則發(fā)送給鄰居 Squid 和后臺(tái)的 WEB 服務(wù)器處理;
- 這樣既減輕后臺(tái) WEB 服務(wù)器的負(fù)載,又提高整個(gè)網(wǎng)站的性能和安全性。
2、代理緩存比較
常用的代理緩存有Varnish,Squid,Ngnix,簡(jiǎn)單比較如下:
(1)varnish和squid是專業(yè)的cache服務(wù),nginx需要第三方模塊支持;
(2) Varnish采用內(nèi)存型緩存,避免了頻繁在內(nèi)存、磁盤中交換文件,性能比Squid高;
(3)Varnish由于是內(nèi)存cache,所以對(duì)小文件如css,js,小圖片啥的支持很棒,后端的持久化緩存可以采用的是Squid或ATS;
(4)Squid功能全而大,適合于各種靜態(tài)的文件緩存,一般會(huì)在前端掛一個(gè)HAProxy或nginx做負(fù)載均衡跑多個(gè)實(shí)例;
(5)Nginx采用第三方模塊ncache做的緩沖,性能基本達(dá)到varnish,一般作為反向代理使用,可以實(shí)現(xiàn)簡(jiǎn)單的緩存。
四、分布式緩存
CDN,反向代理緩存,主要解決靜態(tài)文件,或用戶請(qǐng)求資源的緩存,數(shù)據(jù)源一般為靜態(tài)文件或動(dòng)態(tài)生成的文件(有緩存頭標(biāo)識(shí))。
而分布式緩存,主要指緩存用戶經(jīng)常訪問數(shù)據(jù)的緩存,數(shù)據(jù)源為數(shù)據(jù)庫(kù)。一般起到熱點(diǎn)數(shù)據(jù)訪問和減輕數(shù)據(jù)庫(kù)壓力的作用。
目前分布式緩存設(shè)計(jì),在大型網(wǎng)站架構(gòu)中是必備的架構(gòu)要素。常用的中間件有Memcache,Redis。
1、Memcache
Memcache是一個(gè)高性能,分布式內(nèi)存對(duì)象緩存系統(tǒng),通過在內(nèi)存里維護(hù)一個(gè)統(tǒng)一的巨大的hash表,它能夠用來存儲(chǔ)各種格式的數(shù)據(jù),包括圖像、視頻、文件以及數(shù)據(jù)庫(kù)檢索的結(jié)果等。簡(jiǎn)單的說就是將數(shù)據(jù)調(diào)用到內(nèi)存中,然后從內(nèi)存中讀取,從而大大提高讀取速度。
Memcache特性:
(1)使用物理內(nèi)存作為緩存區(qū),可獨(dú)立運(yùn)行在服務(wù)器上。每個(gè)進(jìn)程最大2G,如果想緩存更多的數(shù)據(jù),可以開辟更多的Memcache進(jìn)程(不同端口)或者使用分布式Memcache進(jìn)行緩存,將數(shù)據(jù)緩存到不同的物理機(jī)或者虛擬機(jī)上。
(2)使用key-value的方式來存儲(chǔ)數(shù)據(jù),這是一種單索引的結(jié)構(gòu)化數(shù)據(jù)組織形式,可使數(shù)據(jù)項(xiàng)查詢時(shí)間復(fù)雜度為O(1)。
(3)協(xié)議簡(jiǎn)單:基于文本行的協(xié)議,直接通過telnet在memcached服務(wù)器上可進(jìn)行存取數(shù)據(jù)操作,簡(jiǎn)單,方便多種緩存參考此協(xié)議。
(4)基于Libevent高性能通信:Libevent是一套利用C開發(fā)的程序庫(kù),它將BSD系統(tǒng)的kqueue,Linux系統(tǒng)的epoll等事件處理功能封裝成一個(gè)接口,與傳統(tǒng)的select相比,提高了性能。
(5)內(nèi)置的內(nèi)存管理方式:所有數(shù)據(jù)都保存在內(nèi)存中,存取數(shù)據(jù)比硬盤快,當(dāng)內(nèi)存滿后,通過LRU算法自動(dòng)刪除不使用的緩存,但沒有考慮數(shù)據(jù)的容災(zāi)問題,重啟服務(wù),所有數(shù)據(jù)會(huì)丟失。
(6)分布式:各個(gè)memcached服務(wù)器之間互不通信,各自獨(dú)立存取數(shù)據(jù),不共享任何信息。服務(wù)器并不具有分布式功能,分布式部署取決于Memcache客戶端。
(7)緩存策略:memcached的緩存策略是LRU(最近最少使用)到期失效策略。在memcached內(nèi)存儲(chǔ)數(shù)據(jù)項(xiàng)時(shí),可以指定它在緩存的失效時(shí)間,默認(rèn)為永久。當(dāng)memcached服務(wù)器用完分配的內(nèi)時(shí),失效的數(shù)據(jù)被首先替換,然后也是最近未使用的數(shù)據(jù)。在LRU中,memcached使用的是一種Lazy Expiration策略,自己不會(huì)監(jiān)控存入的key/vlue對(duì)是否過期,而是在獲取key值時(shí)查看記錄的時(shí)間戳,檢查key/value對(duì)空間是否過期,這樣可減輕服務(wù)器的負(fù)載。
Memcache工作原理:
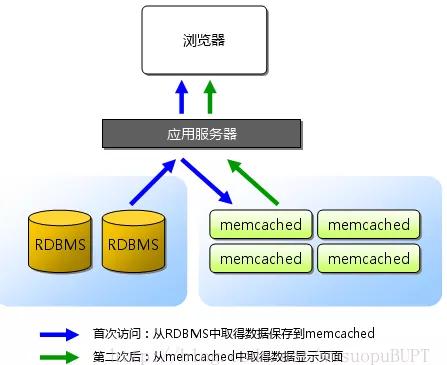
Memcache的工作流程如下:
(1)先檢查客戶端的請(qǐng)求數(shù)據(jù)是否在memcached中,如有,直接把請(qǐng)求數(shù)據(jù)返回,不再對(duì)數(shù)據(jù)庫(kù)進(jìn)行任何操作。
(2) 如果請(qǐng)求的數(shù)據(jù)不在memcached中,就去查數(shù)據(jù)庫(kù),把從數(shù)據(jù)庫(kù)中獲取的數(shù)據(jù)返回給客戶端,同時(shí)把數(shù)據(jù)緩存一份到memcached中(memcached客戶端不負(fù)責(zé),需要程序?qū)崿F(xiàn))。
(3) 每次更新數(shù)據(jù)庫(kù)的同時(shí)更新memcached中的數(shù)據(jù),保證一致性。
(4) 當(dāng)分配給memcached內(nèi)存空間用完之后,會(huì)使用LRU(Least Recently Used,最近最少使用)策略加上到期失效策略,失效數(shù)據(jù)首先被替換,然后再替換掉最近未使用的數(shù)據(jù)。
Memcache集群
memcached 雖然稱為“分布式 ” 緩存服務(wù)器,但服務(wù)器端并沒有 “ 分布式 ” 功能。每個(gè)服務(wù)器都是完全獨(dú)立和隔離的服務(wù)。 memcached 的分布式,是由客戶端程序?qū)崿F(xiàn)的。
當(dāng)向memcached集群存入/取出key value時(shí),memcached客戶端程序根據(jù)一定的算法計(jì)算存入哪臺(tái)服務(wù)器,然后再把key value值存到此服務(wù)器中。
存取數(shù)據(jù)分二步走,第一步,選擇服務(wù)器,第二步存取數(shù)據(jù)。
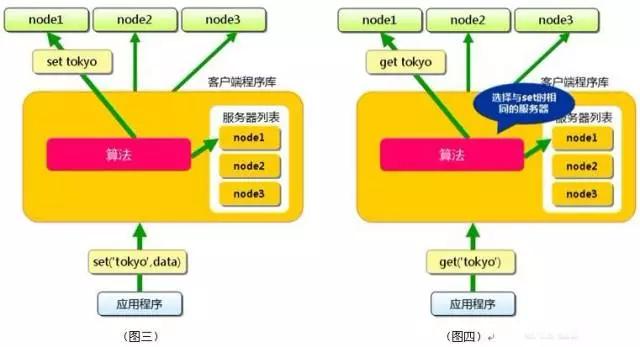
分布式算法(Consistent Hashing):
選擇服務(wù)器算法有兩種,一種是根據(jù)余數(shù)來計(jì)算分布,另一種是根據(jù)散列算法來計(jì)算分布。
- 余數(shù)算法:
先求得鍵的整數(shù)散列值,再除以服務(wù)器臺(tái)數(shù),根據(jù)余數(shù)確定存取服務(wù)器。
優(yōu)點(diǎn):計(jì)算簡(jiǎn)單,高效。
缺點(diǎn):在memcached服務(wù)器增加或減少時(shí),幾乎所有的緩存都會(huì)失效。
- 散列算法:(一致性Hash)
先算出memcached服務(wù)器的散列值,并將其分布到0到2的32次方的圓上,然后用同樣的方法算出存儲(chǔ)數(shù)據(jù)的鍵的散列值并映射至圓上,最后從數(shù)據(jù)映射到的位置開始順時(shí)針查找,將數(shù)據(jù)保存到查找到的第一個(gè)服務(wù)器上,如果超過2的32次方,依然找不到服務(wù)器,就將數(shù)據(jù)保存到第一臺(tái)memcached服務(wù)器上。
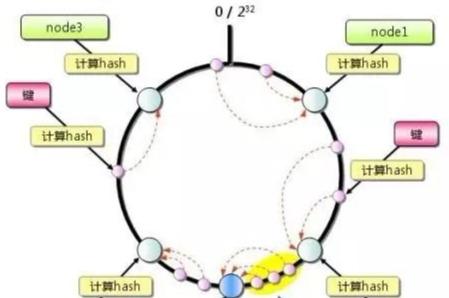
如果添加了一臺(tái)Memcached服務(wù)器,只在圓上增加服務(wù)器的逆時(shí)針方向的第一臺(tái)服務(wù)器上的鍵會(huì)受到影響。
一致性Hash算法:解決了余數(shù)算法增加節(jié)點(diǎn)命中大幅額度降低的問題,理論上,插入一個(gè)實(shí)體節(jié)點(diǎn),平均會(huì)影響到:虛擬節(jié)點(diǎn)數(shù) /2 的節(jié)點(diǎn)數(shù)據(jù)的命中。
2、Redis
Redis 是一個(gè)開源(BSD許可)的,基于內(nèi)存的,多數(shù)據(jù)結(jié)構(gòu)存儲(chǔ)系統(tǒng)。可以用作數(shù)據(jù)庫(kù)、緩存和消息中間件。 支持多種類型的數(shù)據(jù)結(jié)構(gòu),如 字符串(strings), 散列(hashes), 列表(lists), 集合(sets), 有序集合(sorted sets) 與范圍查詢, bitmaps, hyperloglogs 和 地理空間(geospatial) 索引半徑查詢。
內(nèi)置了 復(fù)制(replication),LUA腳本(Lua scripting), LRU驅(qū)動(dòng)事件(LRU eviction),事務(wù)(transactions) 和不同級(jí)別的 磁盤持久化(persistence), 并通過 Redis哨兵(Sentinel)和自動(dòng)分區(qū)(Cluster)提供高可用性(high availability)。
Redis常用數(shù)據(jù)類型
- String
常用命令:set,get,decr,incr,mget。
應(yīng)用場(chǎng)景:String是最常用的一種數(shù)據(jù)類型,與Memcache的key value存儲(chǔ)方式類似。
實(shí)現(xiàn)方式:String在Redis內(nèi)部存儲(chǔ)默認(rèn)就是一個(gè)字符串,被redisObject所引用,當(dāng)遇到incr,decr等操作時(shí)會(huì)轉(zhuǎn)成數(shù)值型進(jìn)行計(jì)算,此時(shí)redisObject的encoding字段為int。
- Hash
常用命令:hget,hset,hgetall 。
應(yīng)用場(chǎng)景:以存儲(chǔ)一個(gè)用戶信息對(duì)象數(shù)據(jù),為例:
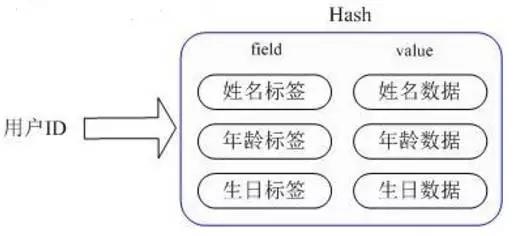
實(shí)現(xiàn)方式:Redis Hash對(duì)應(yīng)的Value,內(nèi)部實(shí)際就是一個(gè)HashMap,實(shí)際這里會(huì)有2種不同實(shí)現(xiàn)。
(1)Hash的成員比較少時(shí)Redis為了節(jié)省內(nèi)存會(huì)采用類似一維數(shù) 組的方式來緊湊存儲(chǔ),而不會(huì)采用真正的HashMap結(jié)構(gòu),對(duì)應(yīng)的value redisObject的encoding為zipmap。
(2)當(dāng)成員數(shù)量增大時(shí)會(huì)自動(dòng)轉(zhuǎn)成真正的HashMap,此時(shí)encoding為ht。
- List
常用命令:lpush,rpush,lpop,rpop,lrange。
應(yīng)用場(chǎng)景:Redis list的應(yīng)用場(chǎng)景非常多,也是Redis最重要的數(shù)據(jù)結(jié)構(gòu)之一,比如twitter的關(guān)注列表,粉絲列表等都可以用Redis的list結(jié)構(gòu)來實(shí)現(xiàn)。
實(shí)現(xiàn)方式:Redis list的實(shí)現(xiàn)為一個(gè)雙向鏈表,可以支持反向查找和遍歷,方便操作。不過帶來了部分額外的內(nèi)存開銷,Redis內(nèi)部的很多實(shí)現(xiàn),包括發(fā)送緩沖隊(duì)列等也都是用的這個(gè)數(shù)據(jù)結(jié)構(gòu)。
- Set
常用命令:sadd,spop,smembers,sunion。
應(yīng)用場(chǎng)景:Redis set對(duì)外提供的功能與list類似是一個(gè)列表的功能,特殊之處在于set是可以自動(dòng)排重的,當(dāng)你需要存儲(chǔ)一個(gè)列表數(shù)據(jù),又不希望出現(xiàn)重復(fù)數(shù)據(jù)時(shí),set 是一個(gè)很好的選擇,并且set提供了判斷某個(gè)成員是否在一個(gè)set集合內(nèi)的重要接口,這個(gè)也是list所不能提供的。
實(shí)現(xiàn)方式:set的內(nèi)部實(shí)現(xiàn)是一個(gè)value永遠(yuǎn)為null的HashMap,實(shí)際就是通過計(jì)算hash的方式來快速排重的,這也是set能提供判斷一個(gè)成員是否在集合內(nèi)的原因。
Sorted set
常用命令:zadd、zrange、zrem、zcard。
使用場(chǎng)景:Redis sorted set的使用場(chǎng)景與set類似,區(qū)別是set不是自動(dòng)有序的,而sorted set可以通過用戶額外提供一個(gè)優(yōu)先級(jí)(score)的參數(shù)來為成員排序,并且是插入有序的,即自動(dòng)排序。當(dāng)你需要一個(gè)有序的并且不重復(fù)的集合列表,可以選擇sorted set數(shù)據(jù)結(jié)構(gòu),比如twitter 的public timeline可以以發(fā)表時(shí)間作為score來存儲(chǔ),這樣獲取時(shí)就是自動(dòng)按時(shí)間排好序的。
實(shí)現(xiàn)方式:Redis sorted set的內(nèi)部使用HashMap和跳躍表(SkipList)來保證數(shù)據(jù)的存儲(chǔ)和有序,HashMap里放的是成員到score的映射,而跳躍表里存放的 是所有的成員,排序依據(jù)是HashMap里存的score,使用跳躍表的結(jié)構(gòu)可以獲得比較高的查找效率,并且在實(shí)現(xiàn)上比較簡(jiǎn)單。
Redis集群
(1)通過keepalived實(shí)現(xiàn)的高可用方案
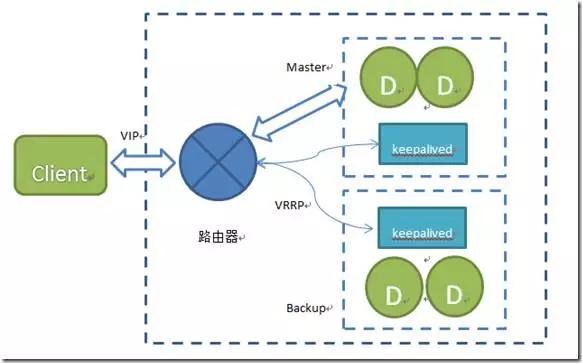
切換流程:
- 當(dāng)Master掛了后,VIP漂移到Slave;Slave 上keepalived 通知redis 執(zhí)行:slaveof no one ,開始提供業(yè)務(wù);
- 當(dāng)Master起來后,VIP 地址不變,Master的keepalived 通知redis 執(zhí)行slaveof slave IP host ,開始作為從同步數(shù)據(jù);
- 依次類推。
主從同時(shí)Down機(jī)情況:
- 非計(jì)劃性,不做考慮,一般也不會(huì)存在這種問題
- 計(jì)劃性重啟,重啟之前通過運(yùn)維手段SAVE DUMP 主庫(kù)數(shù)據(jù);需要注意順序:
- 關(guān)閉其中一臺(tái)機(jī)器上所有redis,是得master全部切到另外一臺(tái)機(jī)器(多實(shí)例部署,單機(jī)上既有主又有從的情況);并關(guān)閉機(jī)器
- 依次dump主上redis服務(wù)
- 關(guān)閉主
- 啟動(dòng)主,并等待數(shù)據(jù)load完畢
- 啟動(dòng)從
- 刪除DUMP 文件(避免重啟加載慢)
(2)使用Twemproxy 實(shí)現(xiàn)集群方案
特點(diǎn):快、輕量級(jí)、減少后端Cache Server連接數(shù)、易配置、支持ketama、modula、random、常用hash分片算法。
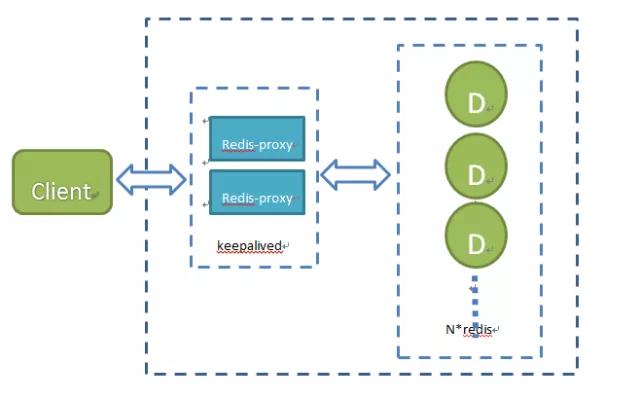
這里使用keepalived實(shí)現(xiàn)高可用主備方案,解決proxy單點(diǎn)問題。
優(yōu)點(diǎn):
對(duì)于客戶端而言,redis集群是透明的,客戶端簡(jiǎn)單,遍于動(dòng)態(tài)擴(kuò)容;
Proxy為單點(diǎn)、處理一致性hash時(shí),集群節(jié)點(diǎn)可用性檢測(cè)不存在腦裂問題;
高性能,CPU密集型,而redis節(jié)點(diǎn)集群多CPU資源冗余,可部署在redis節(jié)點(diǎn)集群上,不需要額外設(shè)備。
3、Memcache與Redis的比較
(1)數(shù)據(jù)結(jié)構(gòu):Memcache只支持key value存儲(chǔ)方式,Redis支持更多的數(shù)據(jù)類型,比如Key value、hash、list、set、zset;
(2)多線程:Memcache支持多線程,Redis支持單線程;CPU利用方面Memcache優(yōu)于Redis;
(3)持久化:Memcache不支持持久化,Redis支持持久化;
(4)內(nèi)存利用率:Memcache高,Redis低(采用壓縮的情況下比Memcache高);
(5)過期策略:Memcache過期后,不刪除緩存,會(huì)導(dǎo)致下次取數(shù)據(jù)數(shù)據(jù)的問題,Redis有專門線程,清除緩存數(shù)據(jù);
五、本地緩存
本地緩存是指應(yīng)用內(nèi)部的緩存,標(biāo)準(zhǔn)的分布式系統(tǒng),一般有多級(jí)緩存構(gòu)成。本地緩存是離應(yīng)用最近的緩存,一般可以將數(shù)據(jù)緩存到硬盤或內(nèi)存。
1、硬盤緩存
將數(shù)據(jù)緩存到硬盤到,讀取時(shí)從硬盤讀取。原理是直接讀取本機(jī)文件,減少了網(wǎng)絡(luò)傳輸消耗,比通過網(wǎng)絡(luò)讀取數(shù)據(jù)庫(kù)速度更快。可以應(yīng)用在對(duì)速度要求不是很高,但需要大量緩存存儲(chǔ)的場(chǎng)景。
2、內(nèi)存緩存
直接將數(shù)據(jù)存儲(chǔ)到本機(jī)內(nèi)存中,通過程序直接維護(hù)緩存對(duì)象,是訪問速度最快的方式。
六、緩存架構(gòu)示例
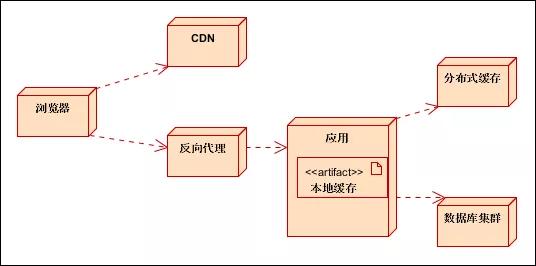
職責(zé)劃分:
CDN:存放HTML、CSS、JS等靜態(tài)資源;
反向代理:動(dòng)靜分離,只緩存用戶請(qǐng)求的靜態(tài)資源;
分布式緩存:緩存數(shù)據(jù)庫(kù)中的熱點(diǎn)數(shù)據(jù);
本地緩存:緩存應(yīng)用字典等常用數(shù)據(jù)。
請(qǐng)求過程:
(1)瀏覽器向客戶端發(fā)起請(qǐng)求,如果CDN有緩存則直接返回;
(2)如果CDN無緩存,則訪問反向代理服務(wù)器;
(3)如果反向代理服務(wù)器有緩存則直接返回;
(4)如果反向代理服務(wù)器無緩存或動(dòng)態(tài)請(qǐng)求,則訪問應(yīng)用服務(wù)器;
(5)應(yīng)用服務(wù)器訪問本地緩存;如果有緩存,則返回代理服務(wù)器,并緩存數(shù)據(jù);(動(dòng)態(tài)請(qǐng)求不緩存)
(6)如果本地緩存無數(shù)據(jù),則讀取分布式緩存;并返回應(yīng)用服務(wù)器;應(yīng)用服務(wù)器將數(shù)據(jù)緩存到本地緩存(部分);
(7)如果分布式緩存無數(shù)據(jù),則應(yīng)用程序讀取數(shù)據(jù)庫(kù)數(shù)據(jù),并放入分布式緩存。
七、緩存常見問題
1、數(shù)據(jù)一致性
緩存是在數(shù)據(jù)持久化之前的一個(gè)節(jié)點(diǎn),主要是將熱點(diǎn)數(shù)據(jù)放到離用戶最近或訪問速度更快的介質(zhì)中,加快數(shù)據(jù)的訪問,減小響應(yīng)時(shí)間。
因?yàn)榫彺鎸儆诔志没瘮?shù)據(jù)的一個(gè)副本,因此不可避免的會(huì)出現(xiàn)數(shù)據(jù)不一致問題。導(dǎo)致臟讀或讀不到數(shù)據(jù)的情況。數(shù)據(jù)不一致,一般是因?yàn)榫W(wǎng)絡(luò)不穩(wěn)定或節(jié)點(diǎn)故障導(dǎo)致。根據(jù)數(shù)據(jù)的操作順序,主要有以下幾種情況。
場(chǎng)景介紹
(1)先寫緩存,再寫數(shù)據(jù)庫(kù)
如下圖:
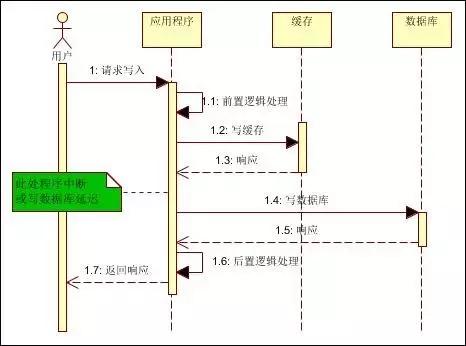
假如緩存寫成功,但寫數(shù)據(jù)庫(kù)失敗或響應(yīng)延遲,則下次讀取(并發(fā)讀)緩存時(shí),就出現(xiàn)臟讀。
(2)先寫數(shù)據(jù)庫(kù),再寫緩存
如下圖:
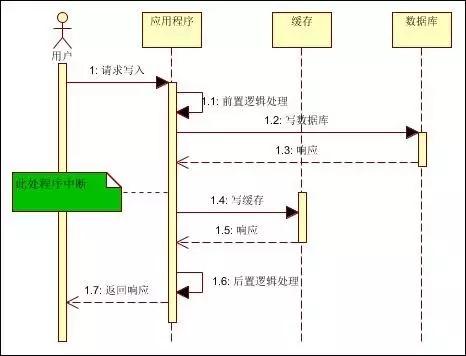
假如寫數(shù)據(jù)庫(kù)成功,但寫緩存失敗,則下次讀取(并發(fā)讀)緩存時(shí),則讀不到數(shù)據(jù)。
(3)緩存異步刷新
指數(shù)據(jù)庫(kù)操作和寫緩存不在一個(gè)操作步驟中,比如在分布式場(chǎng)景下,無法做到同時(shí)寫緩存或需要異步刷新(補(bǔ)救措施)時(shí)候。
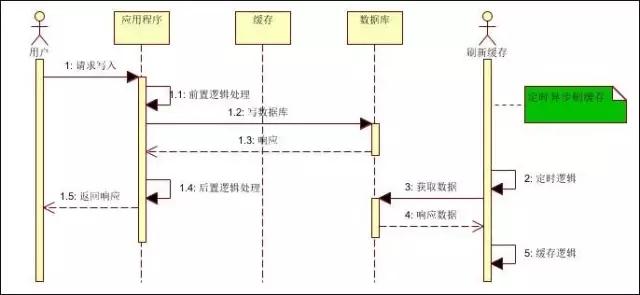
此種情況,主要考慮數(shù)據(jù)寫入和緩存刷新的時(shí)效性。比如多久內(nèi)刷新緩存,不影響用戶對(duì)數(shù)據(jù)的訪問。
解決方法
第一個(gè)場(chǎng)景:這個(gè)寫緩存的方式,本身就是錯(cuò)誤的,需要改為先寫持久化介質(zhì),再寫緩存的方式。
第二個(gè)場(chǎng)景:
(1)根據(jù)寫入緩存的響應(yīng)來進(jìn)行判斷,如果緩存寫入失敗,則回滾數(shù)據(jù)庫(kù)操作;此種方法增加了程序的復(fù)雜度,不建議采用;
(2)緩存使用時(shí),假如讀緩存失敗,先讀數(shù)據(jù)庫(kù),再回寫緩存的方式實(shí)現(xiàn)。
第三個(gè)場(chǎng)景:
(1)首先確定,哪些數(shù)據(jù)適合此類場(chǎng)景;
(2)根據(jù)經(jīng)驗(yàn)值確定合理的數(shù)據(jù)不一致時(shí)間,用戶數(shù)據(jù)刷新的時(shí)間間隔。
其他方法
(1)超時(shí):設(shè)置合理的超時(shí)時(shí)間;
(2)刷新:定時(shí)刷新一定范圍內(nèi)(根據(jù)時(shí)間,版本號(hào))的數(shù)據(jù);
以上是簡(jiǎn)化數(shù)據(jù)讀寫場(chǎng)景,實(shí)際中會(huì)分為:
(1)緩存與數(shù)據(jù)庫(kù)之間的一致性;
(2)多級(jí)緩存之前的一致性;
(3)緩存副本之前的一致性。
2、緩存高可用
業(yè)界有兩種理論,第一套緩存就是緩存,臨時(shí)存儲(chǔ)數(shù)據(jù)的,不需要高可用。第二種緩存逐步演化為重要的存儲(chǔ)介質(zhì),需要做高可用。
本人的看法是,緩存是否高可用,需要根據(jù)實(shí)際的場(chǎng)景而定。臨界點(diǎn)是是否對(duì)后端的數(shù)據(jù)庫(kù)造成影響。
具體的決策依據(jù)需要根據(jù),集群的規(guī)模(數(shù)據(jù),緩存),成本(服務(wù)器,運(yùn)維),系統(tǒng)性能(并發(fā)量,吞吐量,響應(yīng)時(shí)間)等方面綜合評(píng)價(jià)。
解決方法
緩存的高可用,一般通過分布式和復(fù)制實(shí)現(xiàn)。分布式實(shí)現(xiàn)數(shù)據(jù)的海量緩存,復(fù)制實(shí)現(xiàn)緩存數(shù)據(jù)節(jié)點(diǎn)的高可用。架構(gòu)圖如下:
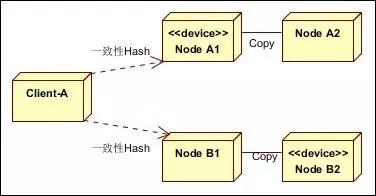
其中,分布式采用一致性Hash算法,復(fù)制采用異步復(fù)制。
其他方法
(1)復(fù)制雙寫:緩存節(jié)點(diǎn)的復(fù)制,由異步改為雙寫,只有兩份都寫成功,才算成功。
(2)虛擬層:一致性Hash存在,假如其中一個(gè)HASH環(huán)不可用,數(shù)據(jù)會(huì)寫入臨近的環(huán),當(dāng)HASH可用時(shí),數(shù)據(jù)又寫入正常的HASH環(huán),會(huì)導(dǎo)致數(shù)據(jù)偏移問題。這種情況,可以考慮在HASH環(huán)前面加一個(gè)虛擬層實(shí)現(xiàn)。
(3)多級(jí)緩存:比如一級(jí)使用本地緩存,二級(jí)采用分布式Cahce,三級(jí)采用分布式Cache+本地持久化;
方式很多,需要根據(jù)業(yè)務(wù)場(chǎng)景靈活選擇。
3、緩存雪崩
雪崩是指當(dāng)大量緩存失效時(shí),導(dǎo)致大量的請(qǐng)求訪問數(shù)據(jù)庫(kù),導(dǎo)致數(shù)據(jù)庫(kù)服務(wù)器,無法抗住請(qǐng)求或掛掉的情況。
解決方法:
(1)合理規(guī)劃緩存的失效時(shí)間;
(2)合理評(píng)估數(shù)據(jù)庫(kù)的負(fù)載壓力;
(3)對(duì)數(shù)據(jù)庫(kù)進(jìn)行過載保護(hù)或應(yīng)用層限流;
(4)多級(jí)緩存設(shè)計(jì),緩存高可用。
4、緩存穿透
緩存一般是Key,value方式存在,當(dāng)某一個(gè)Key不存在時(shí)會(huì)查詢數(shù)據(jù)庫(kù),假如這個(gè)Key,一直不存在,則會(huì)頻繁的請(qǐng)求數(shù)據(jù)庫(kù),對(duì)數(shù)據(jù)庫(kù)造成訪問壓力。
解決方法:
(1)對(duì)結(jié)果為空的數(shù)據(jù)也進(jìn)行緩存,當(dāng)此key有數(shù)據(jù)后,清理緩存;
(2)一定不存在的key,采用布隆過濾器,建立一個(gè)大的Bitmap中,查詢時(shí)通過該bitmap過濾。