













知識圖譜不復雜,我來幫你理一理!
原創【51CTO.com原創稿件】隨著互聯網業務的發展,產生了大量的數據,數據經過分析會推動業務的發展。將數據中蘊含的知識用圖的結構表示出來,就形成了知識圖譜。
圖片來自 Pexels
知識圖譜可以應用到智能搜索,自動文檔,推薦,決策支持等領域。例如:WordNet,Freebase,Wikidata。
今天和大家一起了解知識圖譜構建的方法和基本原理。
知識圖譜概括
知識圖譜是一個較大的話題。從發展,特點,分類和生命周期等不同的方面都有很多需要講的東西。
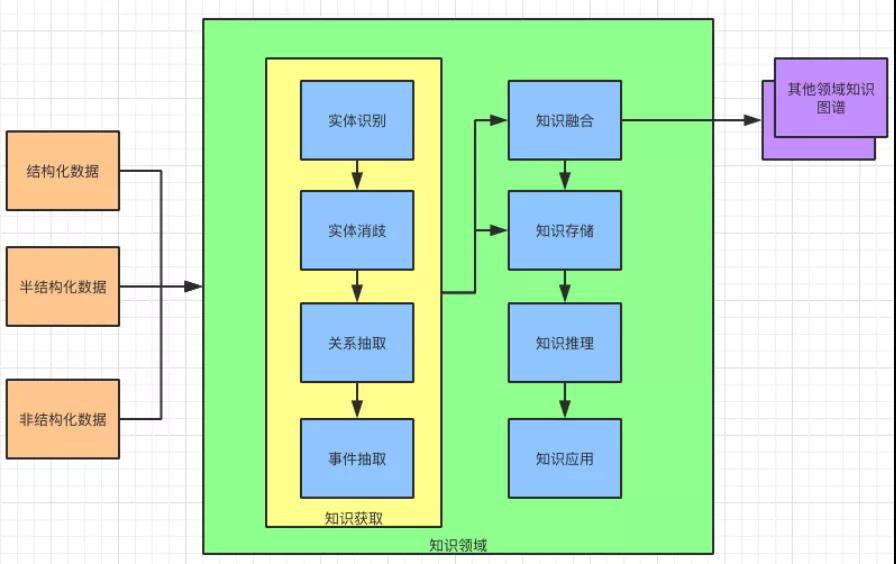
知識領域示意圖
這里我們主要從知識圖譜的生命周期作為切入點,講講在其形成和使用過程中用到的原理和方法。
①知識體系構建。根據分類,可以把知識圖譜分為通用型和領域型。無論是什么類型的知識圖譜都需要對其服務的領域進行知識建模。也就是說,采用什么樣的方式來表達知識。
②知識融合。一個知識庫可以和其他知識庫進行融合。在不同領域知識圖庫進行融合時,會發現來自不同領域,不同語言,甚至不同結構的知識需要做“補充,更新和去重的操作”。
這就是知識融合,一般分為:知識體系融合和實例融合。這部分的操作也可以在構建知識體系的時候統籌考慮。
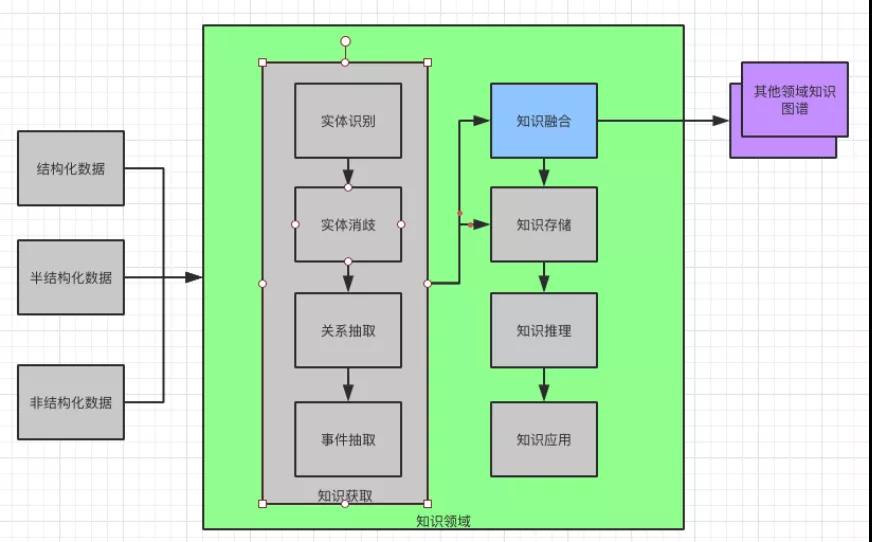
③知識獲取。知識獲取的目的是從海量的信息(文本)中抽取知識。本文中提到的“獲取信息”多為文本信息,因此這里的“獲取信息”也是從文本中獲取信息的過程。
獲取信息結構上劃分為三類,分別是結構化信息,半結構化信息和非結構化信息。
從獲取信息內容上又分為,實體識別,實體消歧,關系抽取和事件抽取。知識存儲在完成了知識抽取和融合之后,就需要將知識存儲下來了。
有 RDF(Resource Description Framework,資源描述框架)格式和圖數據庫兩種方式。
因為圖數據庫對于查詢友好,因此被廣泛使用,例如:Neo4j。
④知識推理。識別并抽取知識以及存儲知識以后,我們會試圖挖掘實體(知識)之間隱含的語義關系。
這個過程就是知識推理。例如:已知 A 是 B 的兒子,又知道 B 是 C 的兒子。那么可以推理出 A 是 C 的孫子。
⑤知識應用。識別,抽取,存儲和推理的最終目的還是為了應用。知識圖譜在搜索,問答,推薦,決策方面被廣泛應用。
后面會將上述過程展開講解,由于知識圖譜中包括的內容比較豐富,因此會著重介紹前面幾個部分的內容,關于知識推理和知識應用的部分會放到以后的文章中介紹。
知識體系構建
我們常說的知識是人類對現實世界的認識,如何將這種認識轉化為一種標準的形式呢?因此,需要有一種模型,對其進行描述,從而能夠存儲到計算機中。
知識表示
知識圖譜的表示方式有多種,有語義網絡,框架,腳本。使用比較多的是語義網絡模型。
它是通過語義關系連接的概念網絡,將知識表示為互相連接的點和邊。其中,節點表示為實體,時間,值等信息;邊表示實體之間的關系。
例如:馬是一種動物,可以表示為如下:
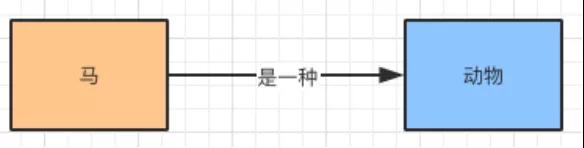
這里的馬和動物表示為實體,“是一種”表示它們之間的關系。這也是我們常說的三元組的表現形式。
用 RDF(Resource Description Framework,資源描述框架)可以表述為:
- (節點 1,關系,節點 1)
- (馬,是一種,動物)
針對關系來說有多種類型的定義:
- 實例關系:“是一個”。表示一個事物是另一個事物的一個實例。例如:小明是一個人。
- 分類關系:“是一種”。表示一個事物是另一個事物的種類。例如:籃球是一種球。
- 成員關系:“個人與集體”。表示一個事物是另一個事物的成員。例如:小王是三年級一班的學生。
- 屬性關系:“一個節點具有另一個節點所表示的屬性”。例如:猴子會爬樹。
- 聚合關系:“部分與整體”。例如:手是身體的一部分。
- 位置關系:事物的方位關系。例如:蘋果在桌子上。
- 相近關系:事物在形狀,內容等方面相似。例如:獅子和老虎在森林中都有霸主的地位。
如果將實體通過上述描述,用三元組的方式表示出來,就形成了知識的圖狀結構,我們把這種結構的表現就叫做知識表現。
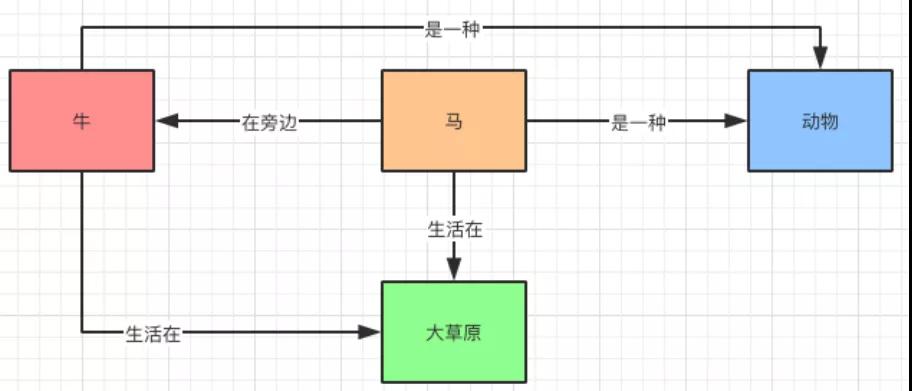
知識圖譜的表現形式
知識體系構建
上面講了知識表示,通過三元組表示現實世界的知識。由于知識領域的不同,對事物的概念和定義也會不相同。
例如:“運維”這個詞,在軟件領域是指對軟件的運行維護;在基礎設施領域,是指對供配電,空調的運行和維護。
因此,知識圖譜是針對具體知識領域而言的。需要根據具體的知識領域,進行“知識體系構建”。
知識體系主要包括三個方面的核心內容:對概念的分類,概念屬性的描述以及概念之間相互關系的定義。
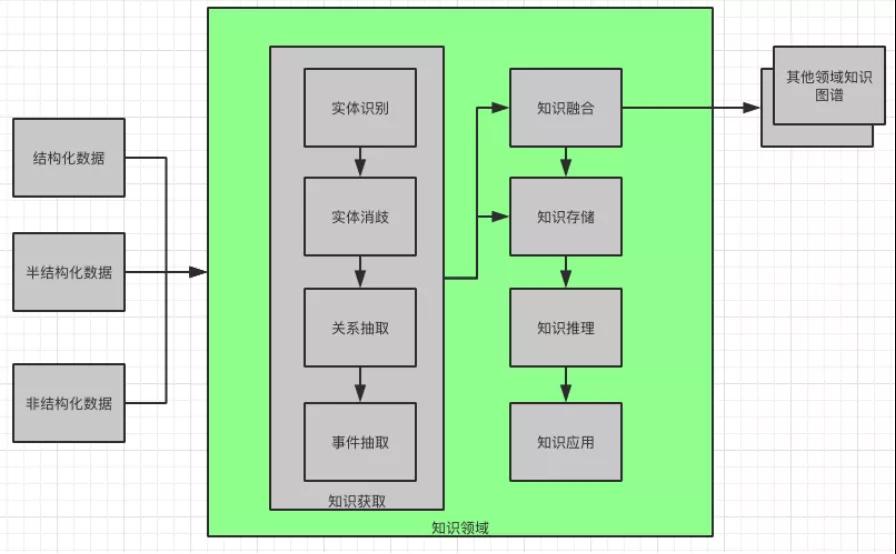
知識領域示意圖
知識領域(知識體系結構)就好像知識圖譜的框架,它定義了知識的概念,概念的屬性以及概念之間的關系。
只有先定義了它,才能再構建知識圖譜。如果把知識領域(知識體系結構)理解成 Class 的話,知識圖譜就是 Object;如果把知識領域(知識體系結構)理解成骨架的話,知識圖譜就是肉體。
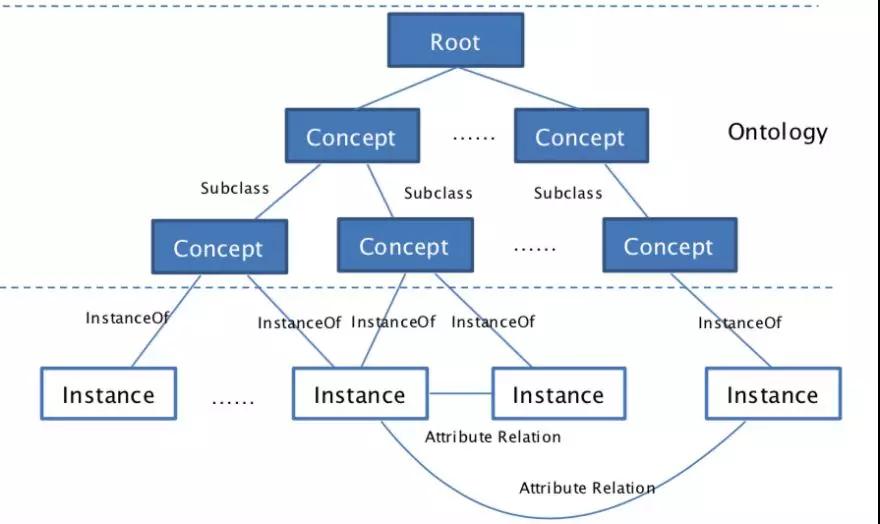
Ontology 對知識進行定義(Concept),根據定義生成實體(Instance)
骨架和肉體
說完知識領域(知識體系結構)的概念,再來看看通過人工構建需要哪幾個步驟。
①確定領域以及任務。這里需要明確幾個問題,為什么需要這個領域的知識圖譜?其中包括哪些知識?它所服務的人群?以及誰來維護它?
②知識體系整合。由于知識圖譜,需要包括海量的知識數據,所以從 0 開始建設成本很高。
因此,需要借助通用知識圖譜,領域詞典,語言學資源,開源知識圖譜的資源。在它們的基礎上建立,大大降低成本。
③羅列要素。針對要建立的知識圖譜,列出這個領域知識的概念,屬性,以及關系等要素。
例如:建立一個人物知識圖譜,就要列出科學家,演員,老師,運動員等概念分類。
針對每個分類,定義姓名,年齡,國籍,出生地等屬性。以及父母,子女,朋友等關系。
④確定分類體系。就是概念之間的層級關系,類似樹狀結構。例如體育分類,下面包括體育組織,體育賽事,體育院校等等。可以通過由上至下,或者由下至上的方式建立。

分類體系示意圖
⑤定義屬性以及關系。這里的屬性和關系的定義具有繼承性。例如:演藝人員擁有“年齡”,“畢業院校”,“經紀公司”等屬性。演藝人員分類下面包括了歌手和演員。
那么歌手和演員的屬性中,除了包括“年齡”,“畢業院校”,“經紀公司”等屬性以外,還可能包括其他屬性,例如:歌手包括“低/中/高音“;演員包括:”國內/國際影星“。
⑥定義約束。針對上面屬性關系的約束關系。例如:年齡為正整數。每個人只有一個母親(生理學意義上的)。
知識融合
各個領域知識圖譜的構建,導致存在各個垂直領域的知識庫。每個知識庫為了擴大自身的廣度和深度,就需要和其他庫做融合。
知識融合示例圖
知識庫的融合有兩種模式:
- 豎直方向的知識融合,將通用知識庫與專業知識庫進行融合。專業知識庫中需要一些通用知識庫中的通用知識定義,例如:著名人物,地名,公理。
- 水平方向的知識融合,將相同領域的知識庫進行融合。讓兩個知識庫進行數據互補。
知識體系能夠在認知和語義層次上對領域知識進行建模和表達,確定領域內共同認可的詞匯,通過概念之間的關系來描述概念的語義,提供對領域知識的共同理解。
多個知識體系在融合過程中會產生重疊,會產生許多不同的知識體系。這些不同的知識體系會導致不同的知識圖譜難以聯合使用。
因此,下面要介紹幾種融合的方法:
- 元素級匹配,將一個詞表示為語義向量空間中的一個點,如果詞與詞之間的相似度高,那么兩個點之間的距離就近。表明兩個詞可以融合。
- 結構級匹配,通過判斷元素屬性的定義域和值域匹配度,推斷屬性的匹配度。
- 實體對齊,通過判斷相同或不同知識庫中的兩個實體是否表示同一個物理對象的過程。
知識獲取
定義了知識領域和領域之間的融合,就搭建了知識圖譜的框架,接下來就要填充內容了。根據三元組理論,知識圖譜是由(實體 1,關系,實體 2)組成的。
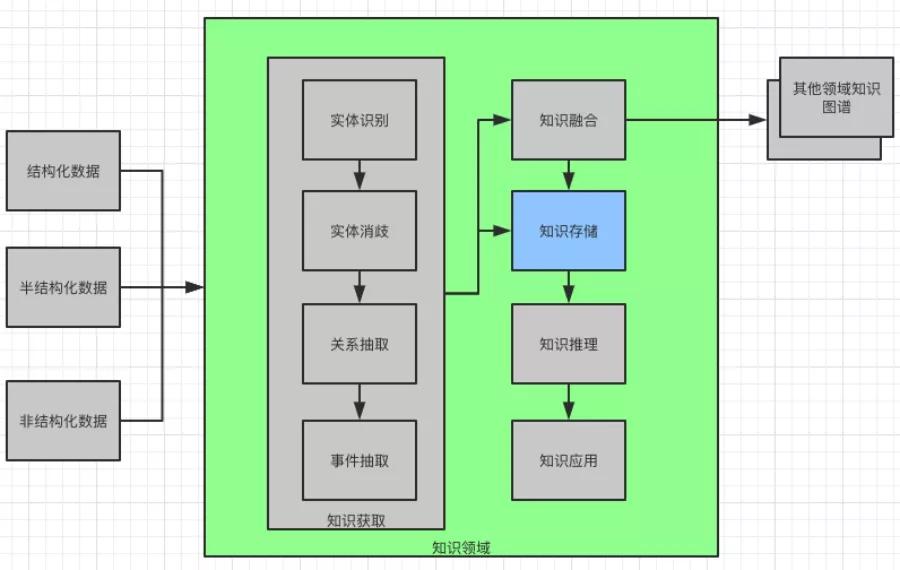
所以,接下來就要介紹知識獲取,它包括實體識別,實體消歧,關系抽取,事件抽取。
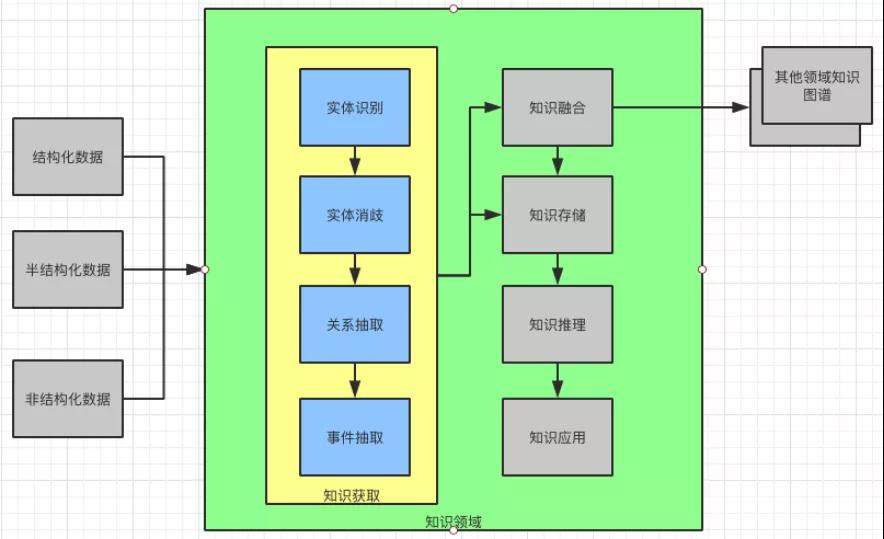
知識獲取示意圖
實體識別
實體(Entity)是知識圖譜的基本單元,也是本文中承載信息的重要語言單位。實體識別是抽取文本中命名性指稱項。
例如:人名,地名,機構名,產品名。通常意義上分為三大類:實體類,時間類和數字類;七小類:人名,地名,機構名,時間,日期,貨幣和百分比。
例如:紅利小學籃球教練張平出席了會議,他在會議上分享了執教心得。
實體“張平”就有三個指稱項,“紅利小學籃球教練”是名詞性指稱項;“張平”是命名性指稱項;“他”是代詞性指稱項。
實體識別抽取有以下幾種方法:
①基于規則的方法,通過建立命名實體詞典的方法,每次抽取都從文本中查找詞典的內容。
- 中文人名識別:<姓氏><名字>。例如:張平。
- 中文組織名識別:<人名><組織名><地名><核心名>。例如:中國軟件信息協會。
- 中文地名的識別:<名字部分><指示詞>。例如:武漢市。
②基于特征的方法,通過機器學習的方法利用預先標注好的語料訓練模型,使模型學習到某個字或者詞作為命名實體組成部分的概率,計算出一個候選字段作為命名實體的概率值。如果大于某個設定的閥值,就抽取命名實體。
③基于神經網絡的方法:
- 特征表示:利用神經網絡模型將文字符號特征表示為分布式特征信息。
- 模型訓練:利用標注數據,優化網絡參數,訓練網絡模型。
- 模型分類:利用訓練的模型對新樣本進行分類,完成識別。
實體消歧
實體識別完成以后,我們遇到一些問題。兩個實體名字一模一樣,但在不同的語境下面,表達的內容完全不同。
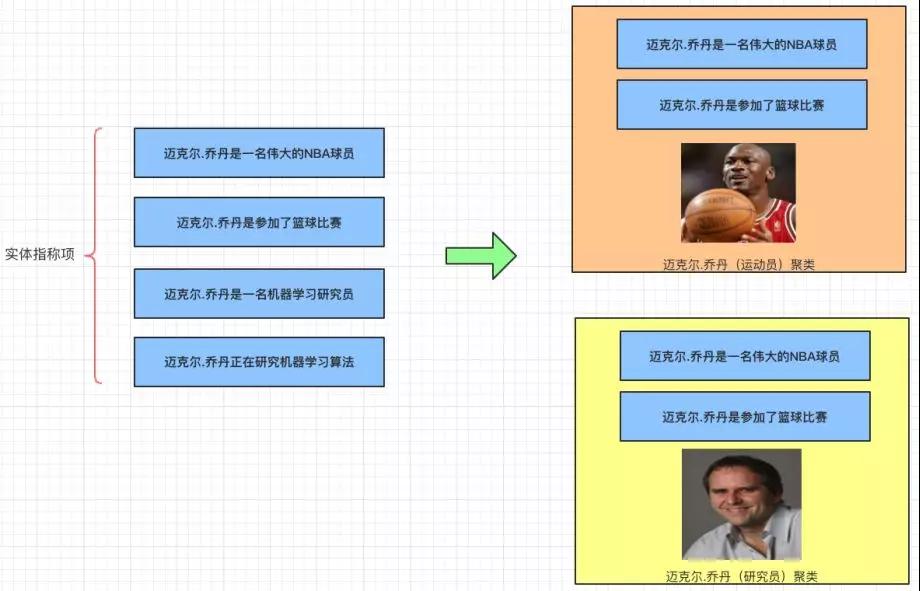
例如:實體指稱項,邁克爾·喬丹(Michael Jordan)在不同的文本中,有可能是籃球明星,也有可能是一位機器學習的研究員。
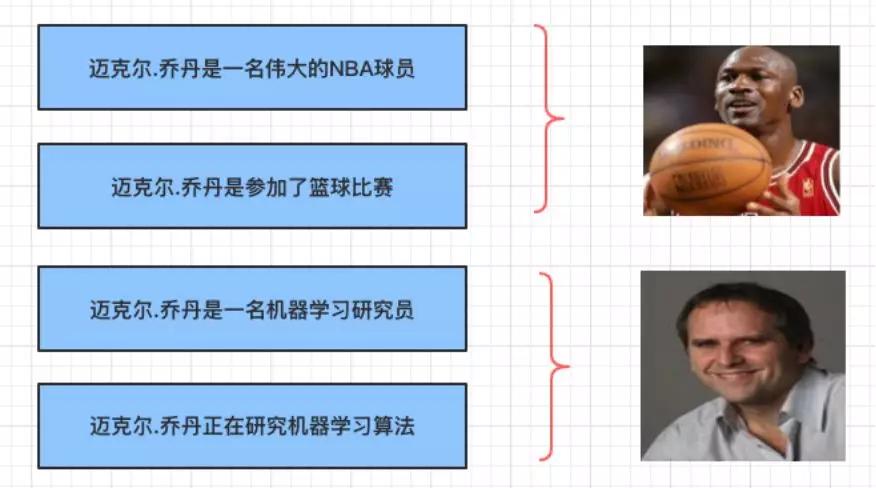
實體消歧示例圖
在介紹如何進行實體消歧之前,先介紹幾個相關概念,以上圖為例:
- 實體名:邁克爾·喬丹(Michael Jordan)
- 目標實體列表:邁克爾·喬丹(研究員),邁克爾·喬丹(運動員)
- 實體指稱項:“邁克爾·喬丹” 是 “邁克爾·喬丹(研究員)”的實體指稱項。同樣,“邁克爾·喬丹”也是 “邁克爾·喬丹(運動員)”的實體指稱項。
那么如何消除這種歧義呢?這里有兩種歧義消除系統推薦。
聚類的消歧系統:將同一實體指稱項分配到同一類別下面,聚類結果中每個類別對應一個目標實體。
聚類示意圖
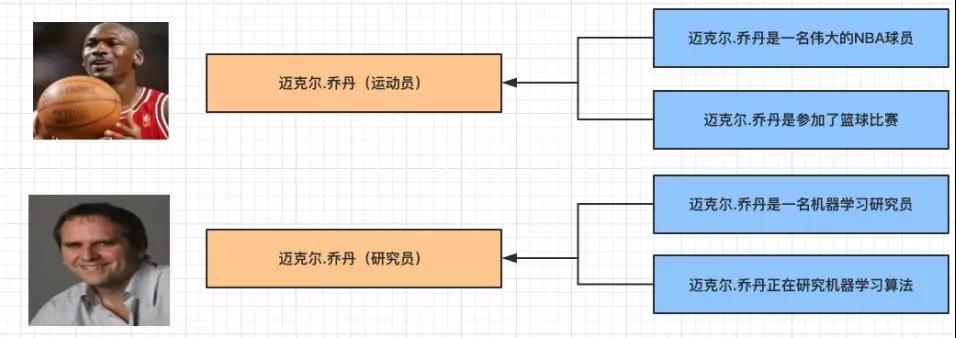
實體鏈接的消歧系統:將實體指稱項與目標實體列表中對應的實體進行連接實現消歧。
實體鏈接示意圖
關系抽取
上面可以將文本中的實體抽取出來,并且消除它們之間的歧義。接下來,要知道實體之間的關系,就需要用到關系抽取。
關系抽取就是,識別實體之間的語義關系。可以分為二元關系抽取(兩個實體)和多元關系抽取(三個及以上實體)。通常表示為(實體 1, 關系, 實體 2)三元組。
根據處理數據源的不同,關系抽取可以分為以下三種:
- 面向結構化文本的關系抽取:包括表格文檔、XML文檔、數據庫數據等。
- 面向非結構化文本的關系抽取:純文本。
- 面向半結構化文本的關系抽取:介于結構化和非結構化之間。
根據抽取文本的范圍不同,關系抽取可以分為以下兩種:
- 句子級關系抽取:從一個句子中判別兩個實體間是何種語義關系。
- 語料級關系抽取:不限定兩個目標實體所出現的上下文。
根據所抽取領域的劃分,關系抽取又可以分為以下兩種:
- 限定域關系抽取:在一個或者多個限定的領域內對實體間的語義關系進行抽取,限定關系的類別,可看成是一個文本分類任務。
- 開放域關系抽取:不限定關系的類別。
由于篇幅關系,這里對具體關系抽取的方法不展開描述。有興趣可以自行查找,每個算法都可以單獨成為一篇文章。這里我們只需要對關系抽取的分類和方法有基本認識就好。
事件抽取
和關系抽取類似,事件抽取是從文本中抽取出事件并以結構化的形式呈現出來。
首先識別事件及其類型,其次識別出事件所涉及的實體,最后需要確定實體在事件中扮演的角色。
通過一個例子,來介紹幾個概念。例如:“小明和小紅于 2019 年 12 月 30 日在北京舉行婚禮。”
事件指稱:具體事件的自然語言描述,通常是一個句子或句群。就是上面這句話的描述。
事件觸發詞:代表事件發生的詞,是決定事件類別的特征,一般是動詞或名詞。例如:“舉行婚禮”。
事件元素:事件中的參與者,主要由實體、時間和屬性值組成。例如:“小明”,“小紅”, “2019 年 12 月 30 日”。
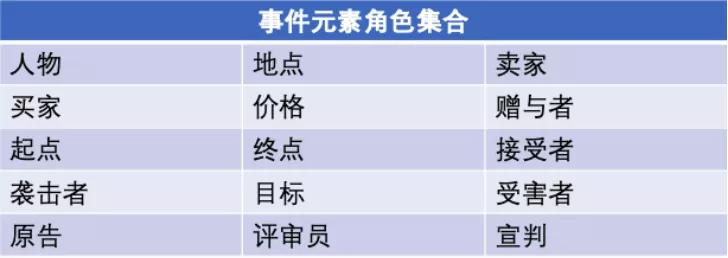
事件元素類型
元素角色:事件元素在事件中扮演的角色。例如:“小明”與“小紅”扮演的是“夫妻角色”。
事件類別:事件元素和觸發詞決定了事件的類別,每個分類下面還有子分類。例如:生命,結婚。
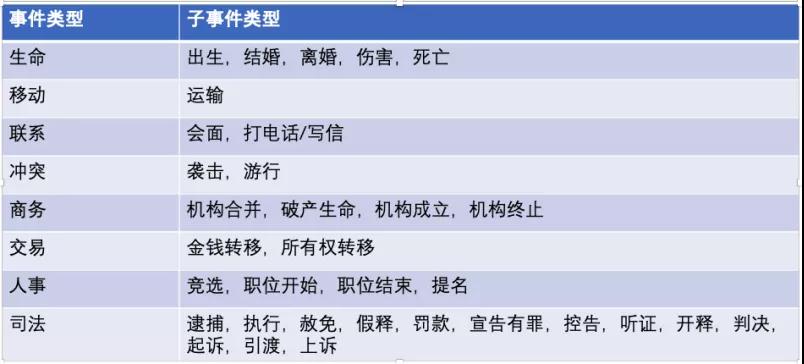
事件類型示意圖
事件抽取的方法比較多,基本上分為限定域事件抽取和開放域事件抽取兩大類。
在兩類中又分為若干小類。這里針對限定域中給予模式匹配的方法給大家做簡單介紹。
限定域事件抽取:在進行抽取之前,預先定義好目標事件的類型及每種類型的具體結構(包含哪些具體的事件元素),通常會給出一定數量的標注數據。通過這些標注數據引導事件的抽取。
比較有代表的是基于模式匹配的方法,首先通過人工標注語料,再通過學習模型來抽取模式,最后將“待抽取文檔”與模式庫中的模式進行匹配,生成抽取結果。
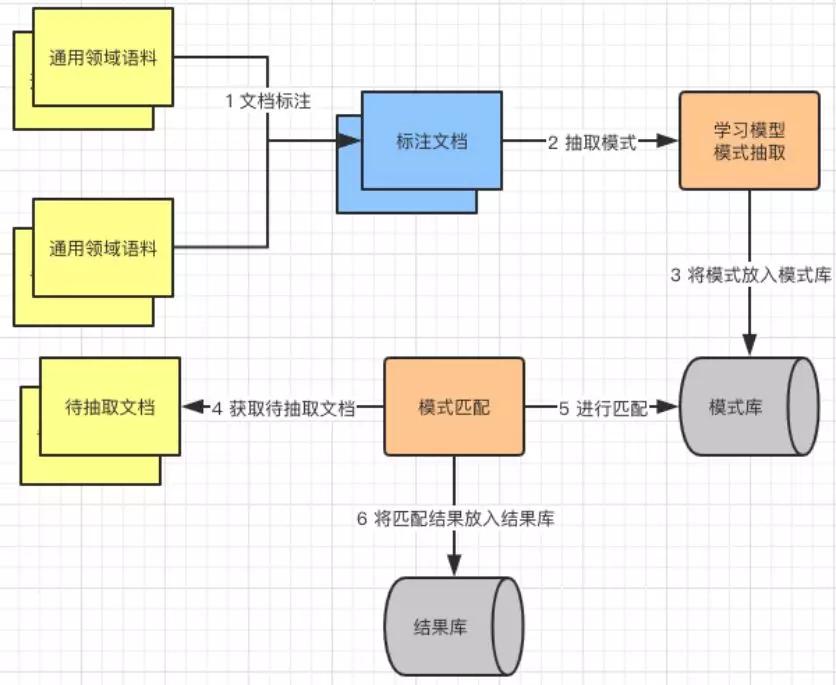
事件抽取,匹配流程圖
另外,關于事件抽取的方法和關系還有很多,這里不展開描述,放出思維導圖供大家參考。
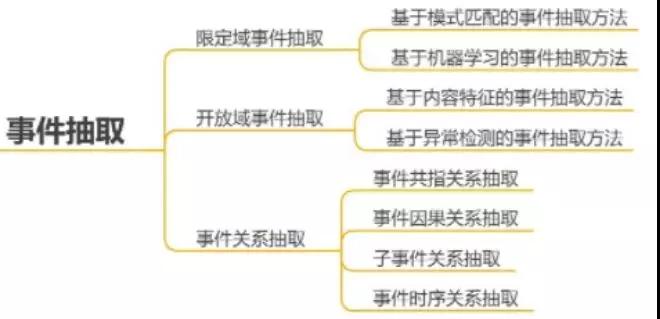
事件抽取思維導圖
知識存儲與檢索
前面提到了知識圖譜的架構,知識的抽取,接下來就需要將這些知識(數據)存儲下來。并且可以將存儲的數據進行檢索。
知識存儲示意圖
談到存儲,需要回到前面說的三元組。知識圖譜中的知識是通過 RDF(Resource Description Framework,資源描述框架)構成的。
每個事實被表示為一個形如(subject,predicate,object)的三元組:
- subject:主體(也稱主語),其取值通常是實體、事件。
- predicate:謂詞(也稱謂語),其取值通常是關系或屬性。
- object:客體(也稱賓語),其取值既可以是實體、 事件、概念,也可以是普通的值(如數字、字符串等) 。
基于表數據的介紹
知識圖譜的表存放方式有兩種,分別是三元組表,類型表。來看看前兩種存儲的方式。例如:有下圖關系。
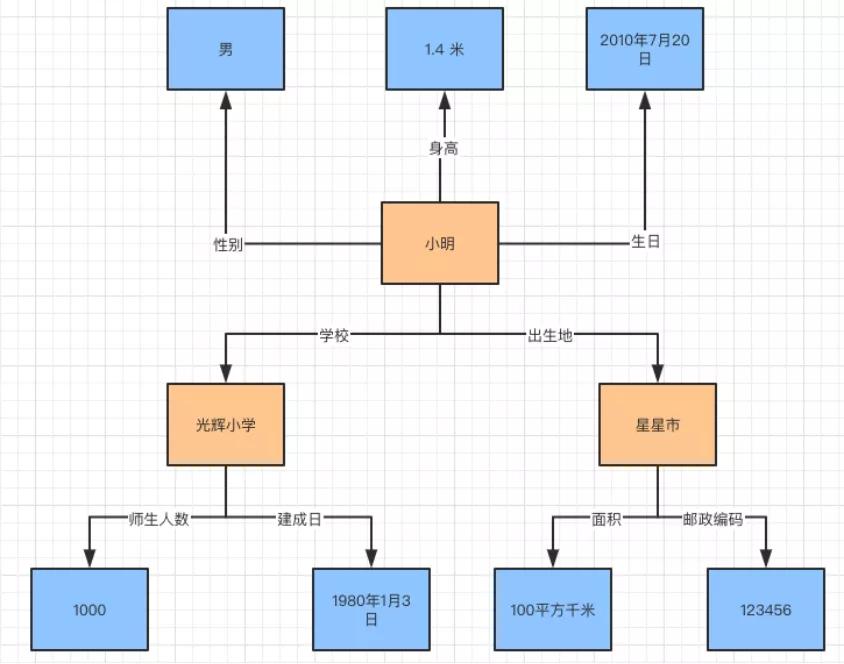
知識圖譜存儲示例圖
用三元組方式存儲:
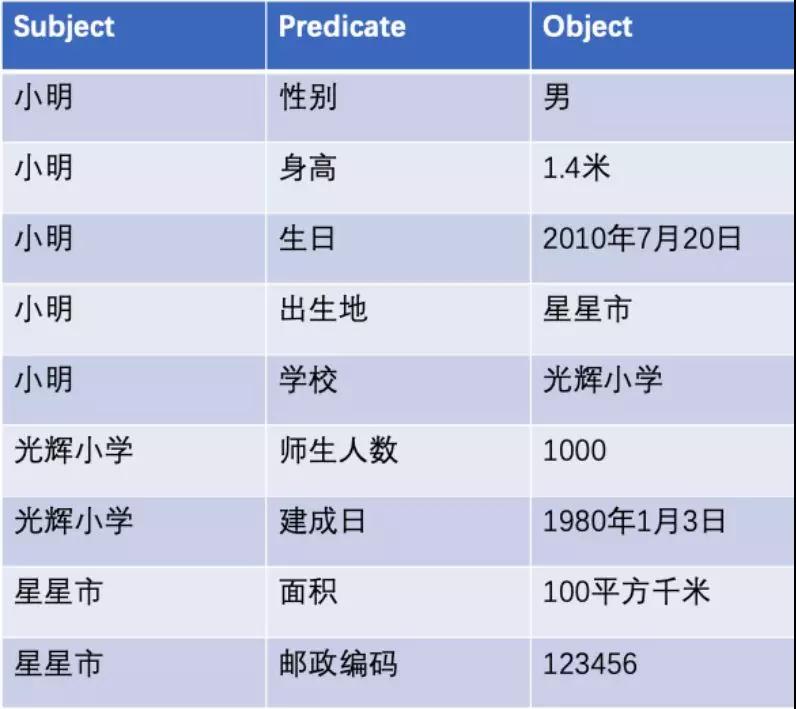
用類型表存儲:
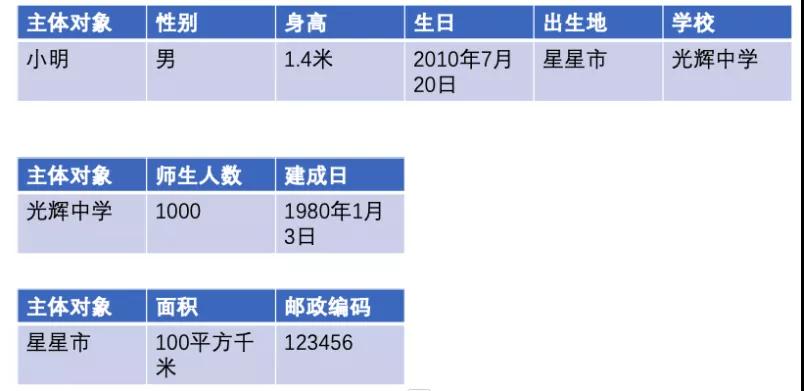
基于圖數據庫的介紹
圖數據庫基于有向圖,其理論基礎是圖論。節點、邊和屬性是圖數據庫的核心概念。
節點,用于表示實體、事件等對象,可以類比于關系數據庫中的記錄。例如人物、 地點、電影等都可以作為圖中的節點。
邊,是指圖中連接節點的有向線條,用于表示不同節點之間的關系。例如:夫妻關系、同事關系等。
屬性,用于描述節點或者邊的特性。例如:姓名、夫妻關系的起止時間等。
來看個例子:
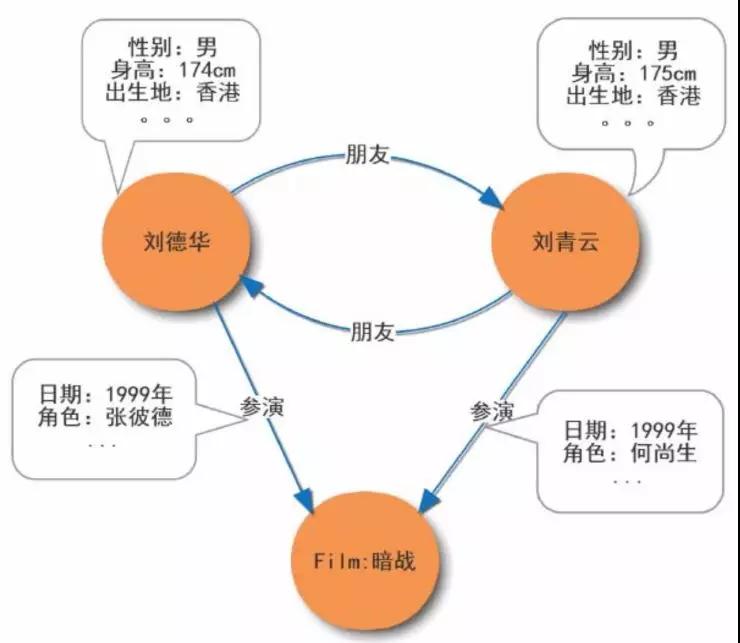
用節點表示實體:劉德華、劉青云、Film:暗戰 。
用邊表示實體間的關系:劉德華和暗戰之間的參演關系、劉德華和劉青云之間的朋友關系等 。
節點可以定義屬性:劉德華性別男、身高 174cm、出生地香港等。
邊上也可以定義屬性:劉德華參演暗戰的時間是 1999 年,參演角色是張彼得等。
無向關系需要轉化為兩條對稱的有向關系:劉德華和劉青云之間互為朋友關系。
知識圖譜的檢索
上面說了按照表方式和圖方式的存儲,再來看看存儲之后如何檢索知識信息。知識圖譜信息可以通過 SQL 和 SPARQL 搜索來獲得。
這里著重介紹 SPARQL,它是 Simple Protocol and RDF Query Language 的縮寫,是由 W3C 為 RDF 數據開發的一種查詢語言和數據獲取協議,被圖數據庫廣泛支持。
和 SQL 類似,SPARQL 也是一種結構化的查詢語言,用于對數據的獲取與管理。
①數據插入
INSERT DATA { } 包含三元組,不同的三元組通過”.”分割,連續的三元組用”;” 分割。
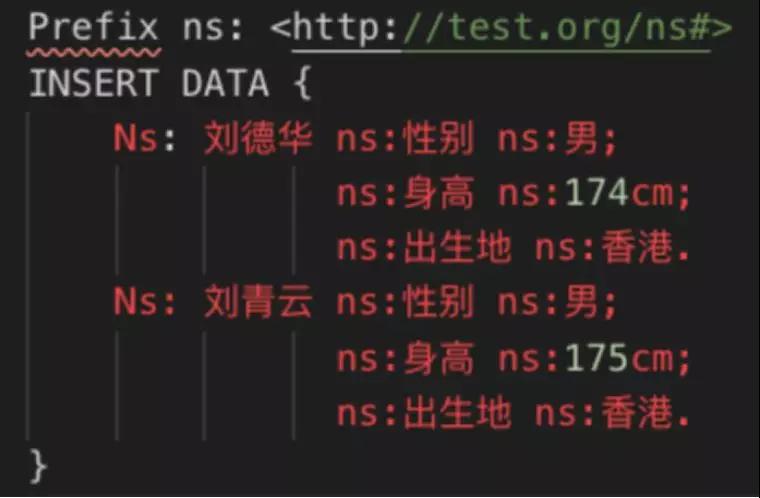
②數據刪除
DELETE DATA {} 包括的三元組,不同的三元組通過”.”分割。
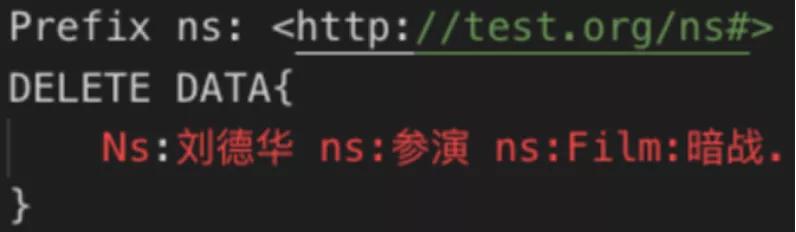
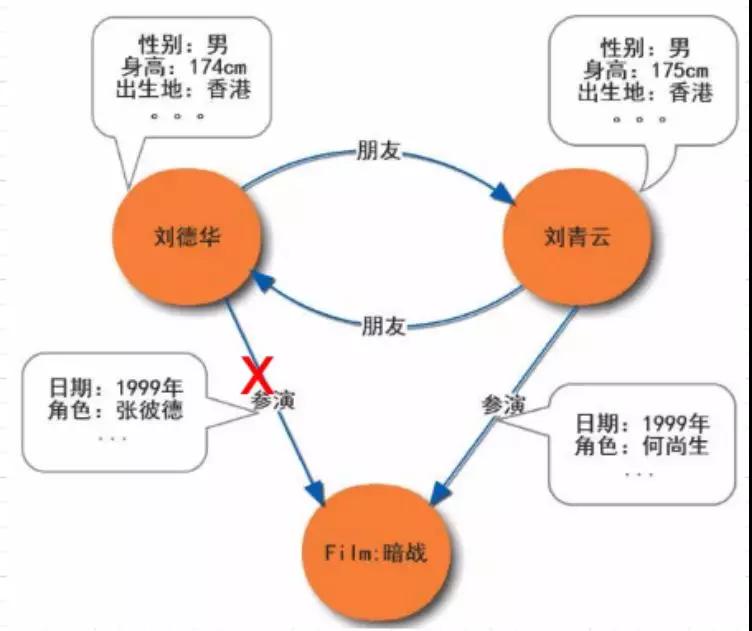
刪除劉德華參演電影的關系
如果想刪除所有劉德華對應節點的關系,用如下語句。
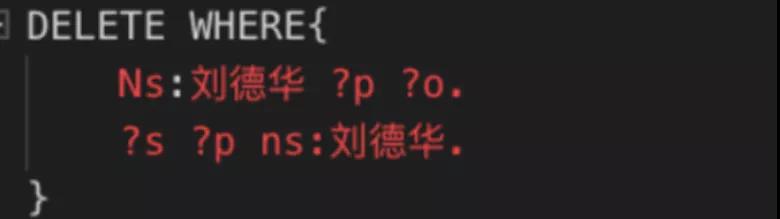
這里的 s,p,o 分別對應的是 subject,predicate 和 object。這樣和劉德華這個節點的相關信息都刪除了。但是劉青云和暗戰對應的節點和關系依舊存在。
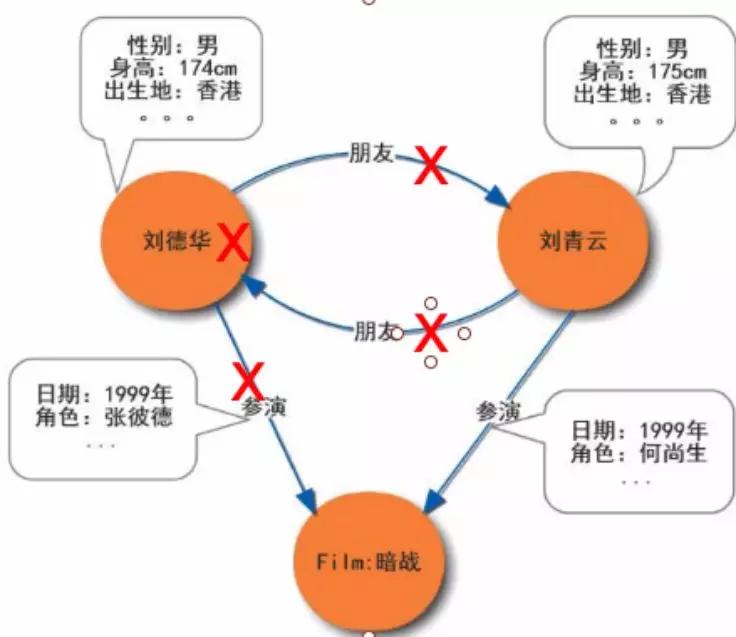
刪除劉德華節點以及對應的關系
③查詢語句
和上面兩個語句類似,例如要查詢身高為 174cm 的男演員。
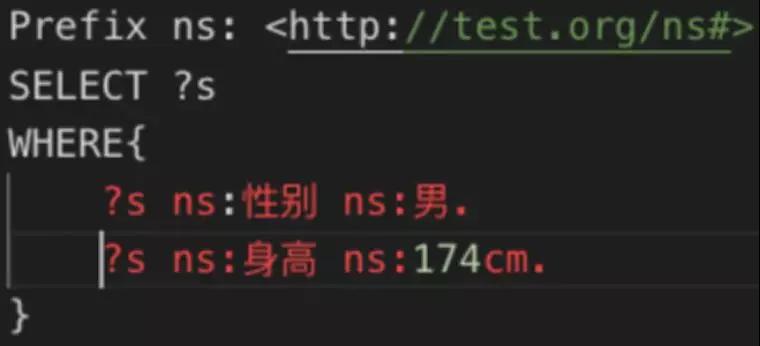
得出的結果就是“s:劉德華”。
總結
如果說知識圖譜本身就是一個知識的數據庫,那么知識領域(知識體系結構)就是這個數據庫的框架。
在建立知識圖譜之前我們需要對知識體系進行搭建,同時要解決知識融合的問題。
有了知識體系結構,就可以進行知識獲取,這里包括實體識別,實體消岐,關系抽取和事件抽取。
實體識別有基于規則,特征和神經網絡的識別方法。實體消岐可以通過聚類和實體連接的方法搞定。
關系抽取和事件抽取,根據數據源,文本范圍和領域劃分的不同,方法各有千秋。知識抽取以后需要做知識的存儲,其中有表存儲和圖存儲兩種方式。
目前比較流行的是圖存儲的方式。并且基于圖存儲的方式,還提供了 SPARQL 查詢語言對數據進行管理。
PS:知識圖譜的內容比較廣博,本文只是對最基本的概念進行了描述。很多觀點來自于趙軍老師的知識圖譜一書。如果需要深入了解,建議閱讀。
作者:崔皓
簡介:十六年開發和架構經驗,曾擔任過惠普武漢交付中心技術專家,需求分析師,項目經理,后在創業公司擔任技術/產品經理。善于學習,樂于分享。目前專注于技術架構與研發管理。

【51CTO原創稿件,合作站點轉載請注明原文作者和出處為51CTO.com】
























