













AutoML取人代之?四個工程師兩個數據集將之干翻!
過去幾年,越來越多科技巨頭推出了自己的 AutoML 服務,市場對于此類服務的關注度與認可度也一直在不斷提升。數據科學家們一直面臨著靈魂拷問:AutoML 會取代我們嗎? 本文,四位數據科學家兩兩一組通過兩個數據集與 AutoML 服務正面較量,最終證明:AutoML 取代工程師,緩緩吧!
目前存在哪些 AutoML 平臺?
要了解 AutoML,我們先得談談機器學習項目的生命周期,具體涵蓋數據清潔、特征選擇 / 工程、模型選擇、參數優化以及最終模型驗證。盡管技術快速發展,傳統數據科學項目當中仍然包含大量既耗時又重復的手動操作流程。
圖片來源:R. Olson 等(2016 年),《在自動化數據科學場景下,對 TPOT(基于樹形結構的流水線優化工具)的評估》
AutoML 能夠自動完成從數據清潔到參數優化的整個流程,憑借著出色的時間與性能改進效果,為各類機器學習項目帶來巨大價值。
1. Google Cloud AutoML
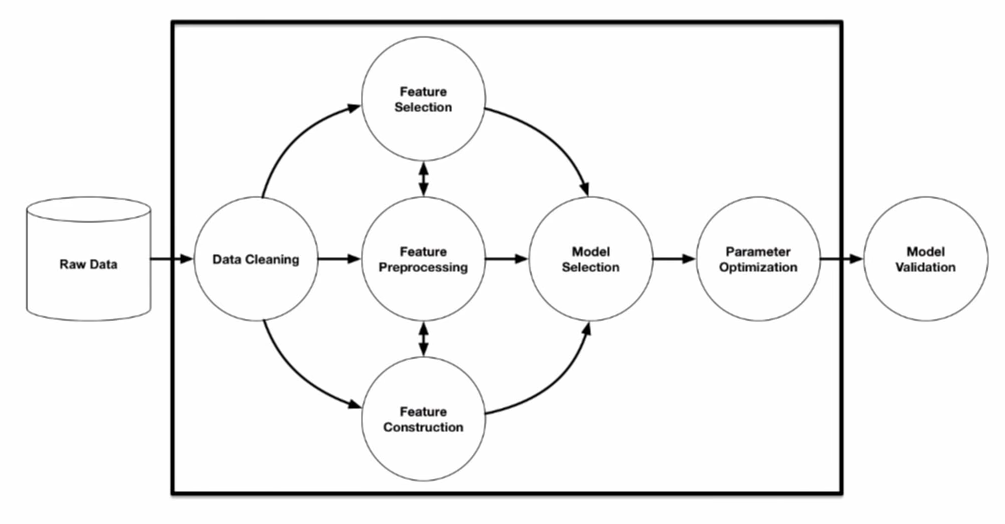
誕生于 2018 年的 Google Cloud AutoML 憑借其友好的用戶界面與極高的性能表現,很快在市場上得以普及。下圖所示,為 Google 與其他 AutoML 平臺之間的性能比較(藍色柱形為 Google AutoML)。
片來源:《在結構化數據上利用 AutoML 解決高價值業務問題》,2019 年 Cloud Next 大會
2. 微軟 Azure AutoML
同樣誕生于 2018 年的 Azure AutoML,為不熟悉編程知識的用戶們帶來高透明度模型選擇流程。
3. H2o.ai
“H2O 已經成為大規模模型構建領域的重要驅動力。面對數十億級別的參數規模,任何現成的標準開源技術都顯得無能為力。” — H2o.ai
H2o 誕生于 2012 年,同時提供開源軟件與商業 AutoML 服務(Driverless AI)兩種選項。自面世以來,H2O 已經在金融服務與零售等行業得到廣泛應用。
4. TPOT
TPOT(基于樹形結構的流水線優化工具)由賓夕法尼亞大學開發完成,是一款可免費使用的 Python 軟件包。該軟件雖然完全免費,但功能方面不打一點折扣,而且在各類數據集上均擁有出色性能表現:Iris 數據集準確率約為 97%,MNIS 數字識別數據集準確率 98%,波士頓房屋價格預測為 10 MSE。
AutoML 對陣數據科學家
現在,我們已經了解了 AutoML 的基本定義及其可用選項。下面來看核心問題:這些平臺會全面取代人類數據科學家嗎?
為了找到令人信服的答案,我們將通過一場黑客馬拉松,客觀評估 AutoML 與人類之間的分析能力差異。
成本比較
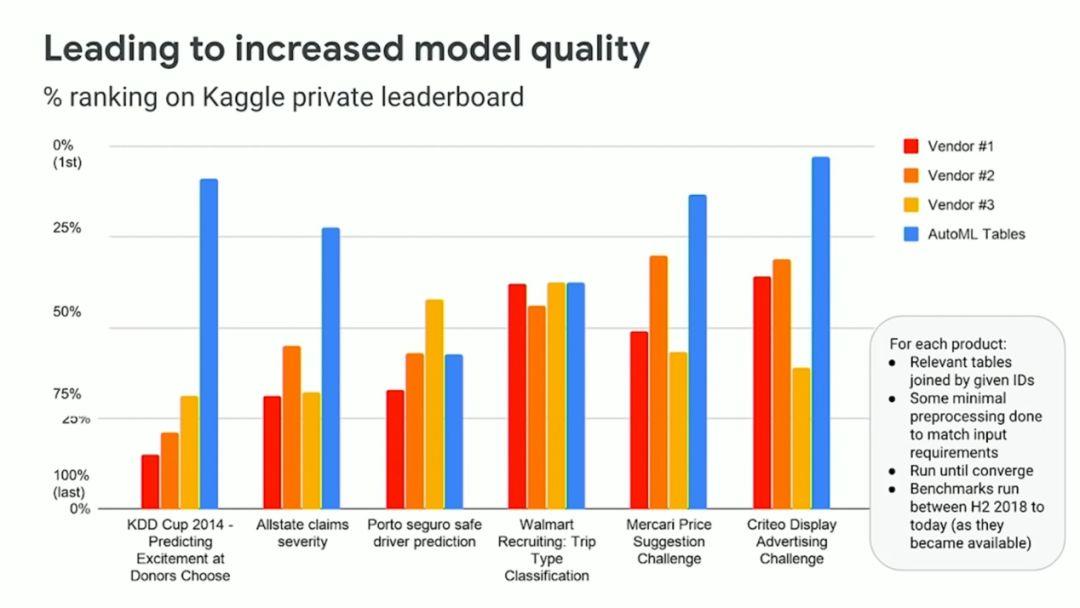
根據 Indeed.com 網站的統計,美國數據科學家的平均年薪為 12 萬 1585 美元。而 如果一家企業全年持續使用 AutoML(每周 40 小時,每年 52 周),則費用每年在 4160 美元到 41600 美元之間,具體視實際平臺選項而定。
誠然,這樣的直接比較并不合理,因為我們都知道數據科學家在模型操作之外還有其他工作需要處理。但在另一方面,這種快速簡單的方法,仍能在一定程度上體現數據科學家與 AutoML 的成本差異。
數據科學家與 AutoML 之間的成本比較
性能比較:黑客馬拉松
下面,我們將組織一場涵蓋兩套數據集的黑客馬拉松,進一步比較人類數據科學家與 AutoML 平臺之間的性能差異。每套數據集,對應一支人類數據科學家小組以及多個 AutoML 平臺。雙方將同步進行數據處理、特征選擇 / 工程、模型選擇以及參數調整,并最終努力給出符合預定性能指標的最佳預測結果。

黑客馬拉松數據集 1:快速分類

黑客馬拉松數據集 2:ASHRAE(回歸)
數據集 1:快速分類數據集
數據集概述
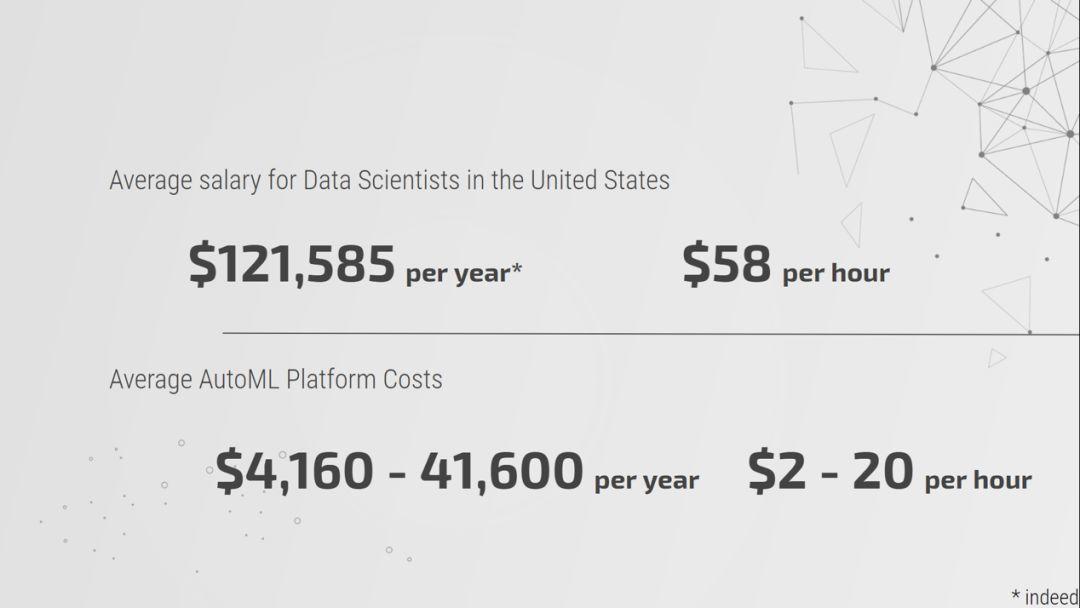
該數據集收集自參與實驗性快速約會活動的人群。在這些活動中,參與者會填寫一份調查表,其中包括個人信息以及他們理想中的伴侶所應具備的特征。例如,他們會以從 1 到 10 幾個等級評論自己、自己從事的工作,以及希望伴侶表現出哪些特質。這套數據集的目標,在于根據個人喜好預測其能否找到適合自己的匹配對象。這是一個典型的分類問題,我們將“match”變量作為因變量。
數據科學家的數據預處理與特征工程
為了獲得優于 AutoML 平臺的結果,人類數據科學家需要對數據集進行特征設計、處理類失衡問題、處理缺失值,并對分類變更執行獨熱編碼。由于數據收集自調查問卷,因此必須存在嚴重的值缺少問題——這是因為如果采訪者不愿意回答某個問題,則可直接留空。這些缺失值只能通過適當估算均值、中位數或者眾數等方式解決。由于數據在某些自變量之間具有共線性,因此某些變量會被刪除。在所有標簽當中,只有 29% 的二進制值為 1,其他部分的二進制值則為 0。為了解決這個問題,我們采用 SMOTE(合成少數過采樣技術)。SMOTE 能夠從少數類當中創建合成樣本,而非簡單復制數據。獨熱編碼在谷歌平臺上往往難于實現,這是因為該平臺無法以有意義的方式對提取到的信息進行分組。
現在,我們將利用原始與特征工程處理后的數據,對 Azure 及谷歌的 AutoML 平臺進行整體有效性分析。
數據科學家對陣 AutoML 平臺

數據科學家: 我們嘗試了多種不同模型,而后發現 XGBoost 與神經網絡模型的性能最好。我們在其中主要關注 AUC ROC 評分,以便將模型結果與 AutoML 平臺創建的模型進行比較。XGBoost 模型的 AUC ROC 得分為 0.77,神經網絡模型的 AUC ROC 得分則為 0.74。
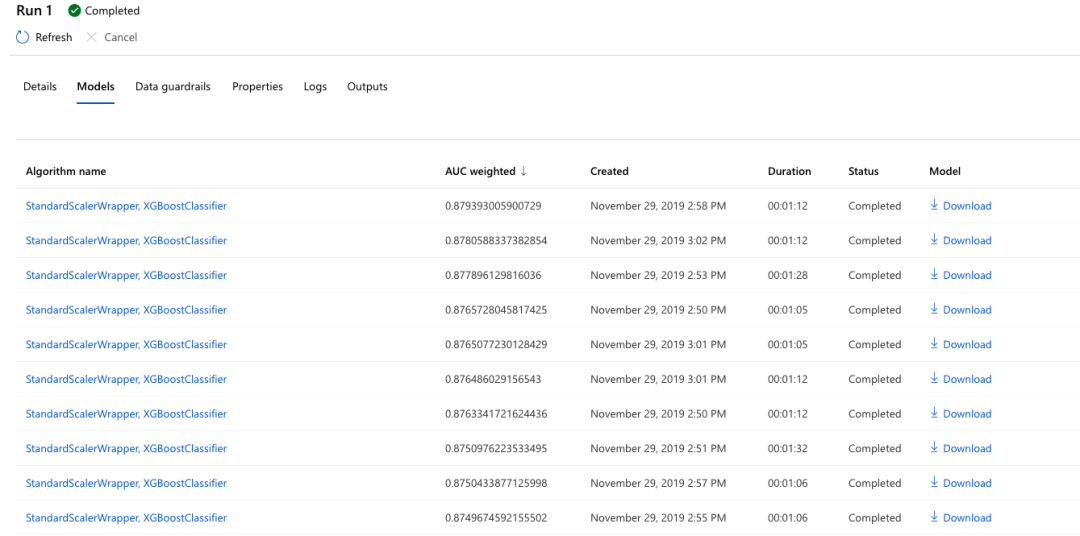
使用原始數據的 AutoML 平臺: 同樣采用 XGBoost,谷歌的性能水平要比 Azure 了一些。谷歌的 AUC ROC 得分為 0.881,Azure 則為 0.865。由于相關信息被劃定為專有信息,因此我們無法得知谷歌平臺到底選擇了哪種模型。另一方面,Azure 則會準確告知其運行了多少個模型,每個模型的得分是多少,以及訓練各個模型所花費的時間。
使用處理后數據的 AutoML 平臺: 現在,我們希望測量經過特征工程處理的數據集又將在 AutoML 上擁有怎樣的性能表現。我們注意到:谷歌的性能有所下降,Azure 性能則得以改善。如前所述,谷歌 AutoML 在處理獨熱編碼方面存在問題,其設計思路在于自主進行特征工程。因此,以獨熱碼變量的形式提供特征工程數據,反而會導致其整體性能下滑。在這輪測試中,Azure 的性能由 0.865 提升到了 0.885。
下圖所示,為 Azure 在數據集上運行的各套模型:
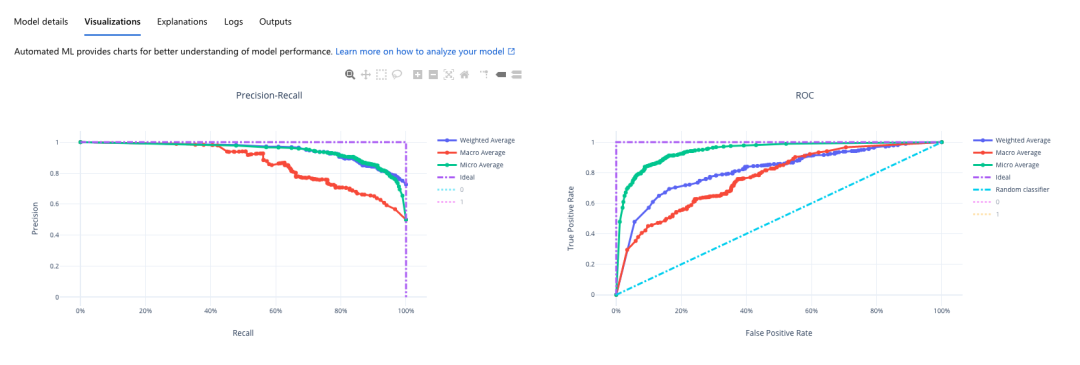
我們也可以看到谷歌與 Azure 平臺上的 Precison-Recall 圖、ROC 圖、混淆矩陣以及特征重要度圖:
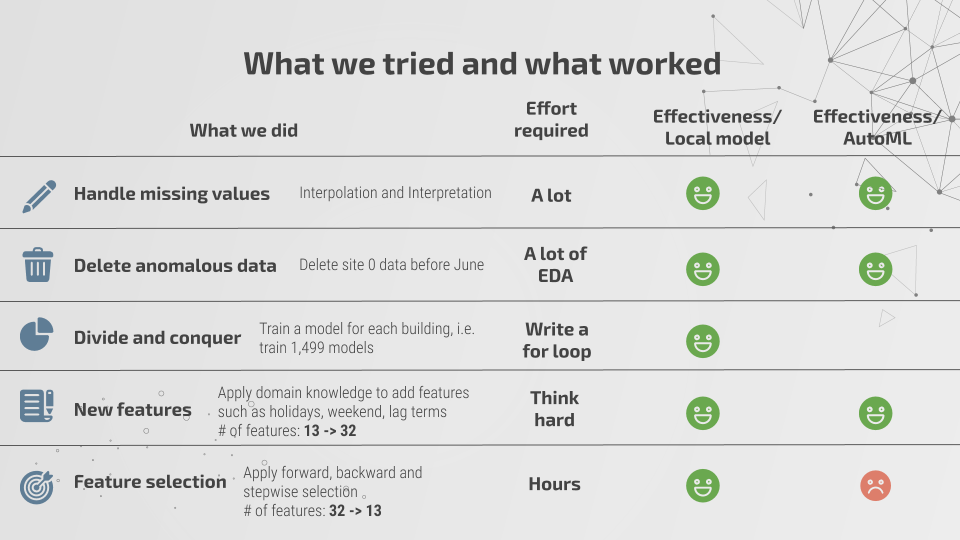
快速(約會)分類數據集測試結論:
- 數據科學家能夠向 AutoML 平臺提供特征工程數據集,從而提高該平臺的性能水平。
- Azure 在具體使用模型方面更為透明;谷歌平臺則拒絕公開模型創建與選擇信息。
- 谷歌無法很好地處理獨熱碼變量。
數據集 2: ASHRAE
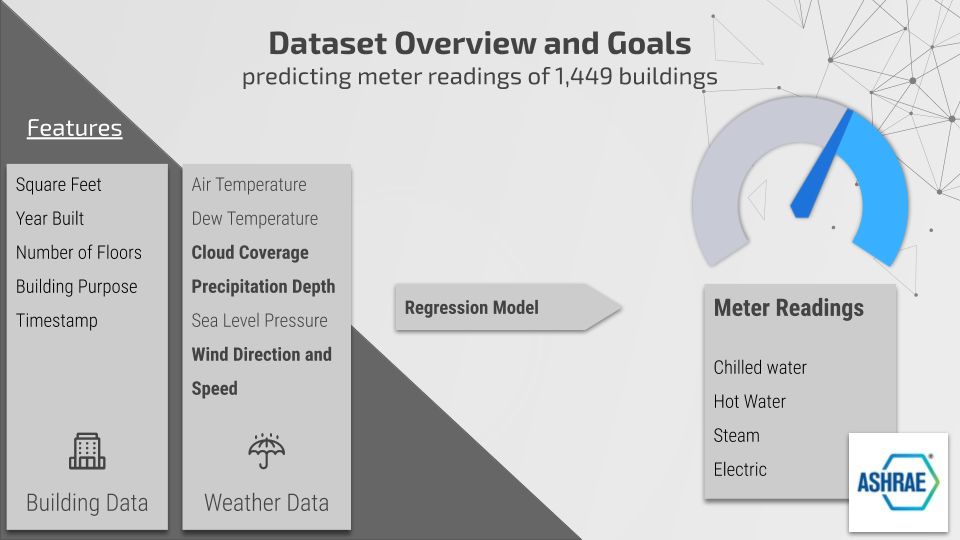
數據集概述
這套數據集來自 ASHRAE Energy Prediction Kaggle 競賽,要求參賽者們開發出一套面向 1449 處建筑物內熱水、冷水、蒸汽以及儀表計數的預測模型。這些數據源自建筑物的一系列相關元數據,包括占地面積、建成時間以及樓層總數;儀表類型與時間戳讀數;帶有時間戳的天氣數據,包括氣溫、云量、降水量、風速、風向以及海平面壓力等。天氣數據由建筑物所在地附近的氣象站提供。
數據科學家的數據預處理與特征工程
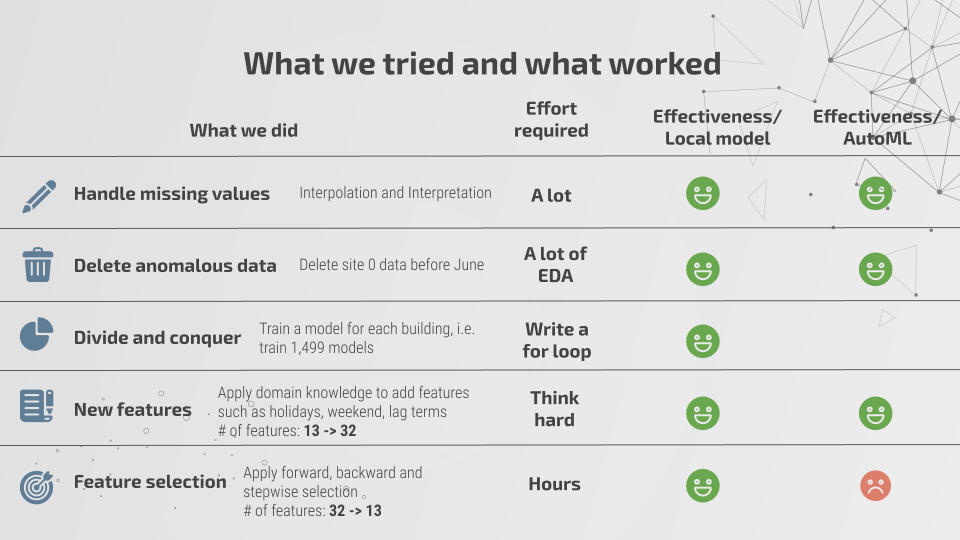
天氣數據集當中同樣存在著嚴重的值缺失問題,可以看到云量與降水量這兩項特征分別存在 50% 與 35% 的缺失比例。部分氣象站甚至壓根不提供云量與降水量數據。為了克服這一障礙,數據科學家們嘗試對氣溫、露水溫度、風速以及海平面壓力等特征進行整理,借此為缺失部分建立插值,并利用這些插值為云量與降水量建立預測模型。
我們利用 10 倍交叉驗證為各項特征選定插值方法,并將其應用于訓練與測試數據。我們運行了一系列模型以預測云量與降水量,但始終未能找到可準確生成缺失值的理想模型。風向測量存在間隔,因此我們將每組數據重構為一組分類變量;由于存在明顯的右偏分布,我們對風速結果進行了對數轉換。此外,我們還構建起其他一些特征,包括假期和周末,同時引入了影響滯后因素。總而言之,我們額外構建起 19 項特征,再加上 13 項原始特征,總計 32 個變量。
最后,我們刪除了一條由氣象站收集到的異常天氣數據,而后利用正向、反向與逐步回歸找出最佳預報特征,因此預測中實際使用的變量為 13 個。
數據科學家對陣 AutoML 平臺

數據科學家: 我們并沒有為所有建筑物構建通用模型,而是為數據集內的每棟建筑物構建起對立的光梯度增強模型,確保訓練與測試集內包含相同建筑物的信息。通過這種方法,我們獲得了 0.773 RMSLE。
使用原始數據的 AutoML 平臺: 經過一個小時的訓練,谷歌云獲得了 1.017 RMSLE;再訓練三個小時,RMSLE 又進一步提升了 0.011。在這輪測試中,谷歌輕松超越 Azure,后者的 RMSLE 為 2.22。當然,這一比較并不算完全公平,因為我們要求 Azure 強制使用隨機森林以返回 RMSLE 結果。
使用處理后數據的 AutoML 平臺: 我們通過谷歌云運行處理后的數據。在經過四個小時的訓練后,谷歌云的 RMSLE 為 1.7,這讓我們相當驚訝。經過進一步調查,我們發現自己的特征選擇方法限制了 AutoML 的性能,因為 AutoML 平臺希望執行自己的特征選擇。我們再次通過兩套平臺運行處理后的數據,且使用全部 32 個變量——而非之前提到的 13 個。這一次,兩套平臺的性能都得到了改善。經過一個小時的訓練,谷歌云的 RMSLE 為 0.755,四小時訓練后的 RMSLE 進一步達到 0.656——這遠遠超過了數據科學家們拿出的結果!經過一個小時的訓練,Azure 的 RMSLE 為 3.826,四小時訓練后的結果則為 3.653。
ASHRAE 數據集測試結論:
盡管 AutoML 是一款強大的預測工具,但仍無法像人類那樣有效進行數據預處理。
將訓練周期延長幾個小時,可以大大提高 AutoML 平臺的性能表現。
必須允許 AutoML 平臺自行選擇特征,否則可能會嚴重影響其性能表現。
將數據科學家在業務問題上的專業知識,同 AutoML 強大的特征選擇、特征預處理、模型選擇以及超參數調優功能相結合,將迸發出強大的能量,為我們帶來寶貴的洞察見解與理想的預測結果。
結論
最后,我們用三個問題來結束此番討論。
AutoML 能替代數據科學家嗎?
答案是否定的。
雖然 AutoML 確實擅長構建模型,但仍然無法勝任大部分數據科學家所熟悉的工作內容。我們需要仰仗數據科學家來定義業務問題,需要他們運用自己的專業知識構建更多具有實際意義的特征。如今,AutoML 還只能處理有限幾種問題類型,例如分類與回歸問題;換言之,它們還無法建立推薦與排名模型。更重要的是,我們仍然需要由數據科學家從數據當中整理出可行洞察,這是單憑 AutoML 所無法做到的。
但是,AutoML 仍能幫助數據科學家為利益相關方創造出巨大的價值。因此,接下來要回答的問題是:我們何時該使用 AutoML?又該如何使用?
數據科學家該如何充分利用 AutoML 平臺?
在這里,我們可以參考以下幾個潛在用例。
性能比可解釋性更重要時:
有時候,利益相關方可能只關注模型精度,而不要求模型必須擁有明確的可解釋性。根據我們的實驗,保證 AutoML 具有合理的特征工程發揮空間似乎有助于性能提升。但在示例當中,兩套平臺只在特征重要度方面體現出一點點可解釋性。換句話說,如果只了解特征重要度就夠了,那么 AutoML 可能會成為實現更高分析精度的理想選項。
生產速度非常重要時:
谷歌與 Azure 都提供將模型部署至生產環境中的便捷方法。例如,谷歌云允許用戶通過幾次點擊快速實現批量與在線預測。它還允許用戶通過 API 將模型部署至自有網站。這些功能,將使得數據科學家顯著加快生產速度并減少實際工作量。
時間較為緊迫時:
數據科學家肩上的擔子可不輕,所以時間對他們來說無比寶貴。在日常工作中,數據科學家需要沒完沒了地參加由產品經理、業務負責人、員工以及客戶組織的會議,維護現有模型、進行數據收集 / 清潔、為下一次會議做準備等等等等。因此,AutoML 將成為節約時間的重要工具,幾次點擊再幾塊小錢,就讓幫助我們訓練出具備一定性能的模型。如此一來,大家就能專注于處理那些最具價值回報的關鍵任務(有時候,把 PPT 做得漂亮一點,可能要比把模型精度提升 1% 重要得多)。
















