性能提升25倍:Rust有望取代C和C++,成為機(jī)器學(xué)習(xí)首選的Python后端
在機(jī)器學(xué)習(xí)開發(fā)領(lǐng)域,如果我們縱觀全局,撇除所有微小的細(xì)節(jié),那么就可以提煉出機(jī)器學(xué)習(xí)開發(fā)中的兩大不變步驟:模型訓(xùn)練和預(yù)測(或推斷)。如今,機(jī)器學(xué)習(xí)的首選語言是 Python(除非你的工作環(huán)境有一些不尋常的約束才會(huì)有所不同),而這篇文章會(huì)帶你走過一段新的旅程。希望當(dāng)你看到最后會(huì)發(fā)現(xiàn),使用 Rust 作為 訓(xùn)練后端 和 部署平臺(tái) 的主意并不像聽起來那樣瘋狂或令人困惑(除了標(biāo)題提到的性能提升外,這種做法的好處其實(shí)還有很多)。
為什么選擇 Python?
我們可以花很多時(shí)間討論機(jī)器學(xué)習(xí)開發(fā)中使用的各種工作流,但如果說我們通常是以一種 探索性 的方式來訓(xùn)練模型,這通常是沒有爭議的。你有一組數(shù)據(jù),然后把它們切成許多片段從而更好地理解它們,接著嘗試各種方法來解決你所關(guān)注的特定問題。(在谷歌街景圖片中識(shí)別出小貓?天氣預(yù)報(bào)?抑或是作物產(chǎn)量優(yōu)化?做什么你來定!)
這一路上會(huì)有很多陷阱,最后你嘗試使用的大多數(shù)技術(shù)都不是開箱即用的,因此重點(diǎn)在于 快速的原型設(shè)計(jì) 和 迭代 改進(jìn)。
對(duì)于像 Python 這樣的動(dòng)態(tài)編程語言,這是一個(gè)理想的使用場景。
更重要的是,你要考慮到大多數(shù)機(jī)器學(xué)習(xí)實(shí)踐者會(huì)有統(tǒng)計(jì)學(xué)、數(shù)學(xué)、物理或類似學(xué)位的背景,卻不是計(jì)算機(jī)科學(xué)專家,也就是說他們(我也一樣✋)幾乎沒有接受過軟件工程實(shí)踐和工具方面的訓(xùn)練。
雖說 Python 同時(shí)支持函數(shù)式和面向?qū)ο蟮哪J剑憧梢允褂妹钍斤L(fēng)格,憑借其腳本功能來快速上手。它的入門門檻很低,隨著你的經(jīng)驗(yàn)提升,越來越精于此道,Python 也會(huì)與你一同成長。
但是,僅僅易用是遠(yuǎn)遠(yuǎn)不夠的:訓(xùn)練機(jī)器學(xué)習(xí)模型需要大量的繁瑣運(yùn)算,而 Python 絕對(duì)不是最快的編程語言。
于是我們看到 NumPy(1995/2006)、SciPy(2001)、Pandas(2008)和 Scikit-learn(2007)魚貫入場。如果沒有這樣一個(gè)用于機(jī)器學(xué)習(xí)和科學(xué)計(jì)算的、高質(zhì)量且覆蓋全面的工具包,Python 就不會(huì)取得今天的地位。
然而,如果你深入背后探究一番,就會(huì)發(fā)現(xiàn)那里沒有多少 Python 的位置:你正在使用 Python 來編排和利用 一個(gè) C 和 C++ 例程的強(qiáng)大內(nèi)核。
Python 是這些系統(tǒng)的前端,用戶用 Python 這個(gè)用戶界面將它們輕松地粘合在一起。C 和 C++ 才是你的后端,是幕后的魔力源泉。
確實(shí),這是 Python 經(jīng)常被忽略的特性:使用其 外函數(shù)接口(FFI)與其他編程語言互操作相當(dāng)容易。特別是,Python 庫可以將需要大量數(shù)字運(yùn)算的程序代碼委派給 C 和 C++,這是 Python 科學(xué)生態(tài)系統(tǒng)中 所有 基礎(chǔ)庫都在使用的策略。
當(dāng)然,技術(shù)永遠(yuǎn)無法決定一切。社會(huì)學(xué)因素對(duì)于大多數(shù)項(xiàng)目的成功(或消亡)都是至關(guān)重要的,即使有些人覺得這難以接受。
因此我們應(yīng)該再補(bǔ)充一些背景:Python 是一個(gè)開放源代碼項(xiàng)目(嗨,MATLAB!),它在學(xué)術(shù)機(jī)構(gòu)中的滲透水平是不可忽略的;而且事實(shí)上,當(dāng)深度學(xué)習(xí)走進(jìn)聚光燈下時(shí),與它相關(guān)的多數(shù)科學(xué)生態(tài)系統(tǒng)已經(jīng)建立完畢了。
事后看來,將 Python 視為會(huì)在機(jī)器學(xué)習(xí)領(lǐng)域占據(jù)統(tǒng)治地位的強(qiáng)大候選者是很自然的事情,結(jié)果也并不出人意料。
我們今后還應(yīng)該繼續(xù)使用 Python 嗎?
前面我們簡要地介紹了將 Python 作為機(jī)器學(xué)習(xí)開發(fā)首選編程語言的部分原因。
但世界并不是靜止不變的:背景環(huán)境的變化可以大大改變?nèi)藗儗?duì)哪種工具是“最佳工作工具”的認(rèn)識(shí)。
一些最新趨勢可能會(huì)加強(qiáng) Python 在機(jī)器學(xué)習(xí)領(lǐng)域的地位。
微服務(wù)
微服務(wù)架構(gòu)目前在架構(gòu)設(shè)計(jì)方法中占主導(dǎo)地位:公司用松散的容器化服務(wù)集合來運(yùn)行他們的業(yè)務(wù),這些服務(wù)通過網(wǎng)絡(luò)相互通信。
運(yùn)行一個(gè) Polyglot 堆棧從未如此簡單:你的主應(yīng)用程序和業(yè)務(wù)邏輯的精華都可以用 Java 編寫——當(dāng)你想利用機(jī)器學(xué)習(xí)來確定某筆信用卡交易是合法還是欺詐時(shí),你可以發(fā)出一個(gè) POST 請(qǐng)求到一個(gè) Python 微服務(wù)上。
數(shù)據(jù)科學(xué)家和機(jī)器學(xué)習(xí)工程師用 Python 執(zhí)行模型探索的日子已經(jīng)一去不復(fù)返了,如今我們將所有內(nèi)容移交給“生產(chǎn)團(tuán)隊(duì)”,后者會(huì)用公司選擇的語言全面重寫邏輯。
DevOps
你構(gòu)建,你運(yùn)行——Werner Vogels(亞馬遜 CTO)
既然我們談?wù)摰氖菢I(yè)務(wù),那就必須強(qiáng)調(diào)一點(diǎn):機(jī)器學(xué)習(xí)模型不是憑空存在的,它們是公司要啟動(dòng)、優(yōu)化或改進(jìn)的產(chǎn)品或過程的一部分。
因此,僅由數(shù)據(jù)科學(xué)家組成的團(tuán)隊(duì)就能取得顯著的成績——是很天真的想法。你需要的東西遠(yuǎn)不止這些。
如果要獲得成功的機(jī)會(huì),則需要從產(chǎn)品到軟件工程的各種技能的組合。
那么這樣的團(tuán)隊(duì)?wèi)?yīng)該使用哪種編程語言?
記住 JavaScript 的興起歷程:同一個(gè)人使用 JavaScript 和 NodeJS,就可以同時(shí)處理系統(tǒng)的前端和后端工作(“全棧”)。
作為通用編程語言的 Python 提供了相同的便利。你可以將其科學(xué)堆棧用于機(jī)器學(xué)習(xí)開發(fā),并利用其框架(Django、Flask 和 FastAPI 等)進(jìn)行模型部署,再通過 REST 或 gRPC API 提供預(yù)測。
很好,不是嗎?
連鎖效應(yīng)
Python 擁有一個(gè)龐大的機(jī)器學(xué)習(xí)生態(tài)系統(tǒng);
你希望自己的機(jī)器學(xué)習(xí)算法或機(jī)器學(xué)習(xí)框架能被采納:所以你使用 Python 編寫代碼(或使用 FFI 為它提供 Python 綁定);
Python 生態(tài)系統(tǒng)變得更強(qiáng)大了。
循環(huán)往復(fù)。
答案
明天我們可能還是會(huì)用 Python 來編寫機(jī)器學(xué)習(xí)軟件。
我們會(huì)永遠(yuǎn)使用它嗎?不太可能,這就像在問自己,從現(xiàn)在起 10 年后計(jì)算機(jī)產(chǎn)業(yè)的未來會(huì)是什么樣。
但是我不會(huì)押注說未來 5 年我們就能看到 Python 的落日。
所以呢?這篇文章不是要談 Rust 的嗎?
沒錯(cuò)!
但更重要的是,在開始談?wù)撜}之前消除所有可能的誤解。
我不相信 Rust 會(huì)取代 Python 成為機(jī)器學(xué)習(xí)的首選語言——這事完全沒有任何苗頭,不管是今天還是未來,這都不是什么趨勢。
這兩門語言無法迎合相同的人群,并且它們針對(duì)的是不同的約束條件,做了不同的優(yōu)化工作,解決的是一系列不同的問題。
但是 Rust 在機(jī)器學(xué)習(xí)世界中有自己的一席之地。
Rust 具有 取代 C 和 C++,成為機(jī)器學(xué)習(xí)負(fù)載首選的 Python 后端 的巨大潛力。
為什么是 Rust?
沒有比這本書的 序言 更好的答案了:
例如,“系統(tǒng)級(jí)”地處理內(nèi)存管理、數(shù)據(jù)表示和并發(fā)性的底層細(xì)節(jié)。傳統(tǒng)上,這種編程領(lǐng)域被視為是神秘的王國,只有少數(shù)一些已經(jīng)花了足夠的時(shí)間學(xué)習(xí),以避免其臭名昭著陷阱的人們才能踏入其中。即使是實(shí)踐它的那些人們也要謹(jǐn)慎行事,以免他們的代碼易受攻擊、容易崩潰或損壞。
Rust 消除了那些舊有的陷阱,并提供了一套友好而精致的工具來幫助你披荊斬棘,打破這些障礙。那些需要“深入”到較底層控制的程序員可以使用 Rust 來做到這一點(diǎn),而不必承擔(dān)崩潰或出現(xiàn)安全漏洞的常見風(fēng)險(xiǎn),也不必領(lǐng)悟多變的工具鏈的精髓所在。更好的是,這種語言旨在引導(dǎo)你自然地開始使用在性能和內(nèi)存使用方面效率出色的可靠代碼。
Rust 以徹底領(lǐng)先的信心水平提供了與 C 和 C++ 相當(dāng)?shù)男阅堋?/p>
你相信編譯器知道你所不知道的內(nèi)容:換句話說,你從“這到底是什么?”安全地轉(zhuǎn)到了“讓我們?cè)谏a(chǎn)中運(yùn)行這些代碼!”的這條路線上。
這大大降低了入門的門檻。
讓更多的人(又包括我✋)可以編寫高性能的機(jī)器學(xué)習(xí)算法。
越來越多的人可以為他們每天使用的那些項(xiàng)目的后端做出貢獻(xiàn)。
這會(huì)催生一個(gè)更大的社區(qū)、更多的實(shí)驗(yàn)和更可持續(xù)的項(xiàng)目——換句話說,催生一個(gè)更健康、更多樣化的生態(tài)系統(tǒng)。
回到我之前提到的那些趨勢,你會(huì)再次發(fā)現(xiàn)全棧帶來的強(qiáng)大力量:負(fù)責(zé)模型探索的那個(gè)人(使用 Python)可以深入研究并使用 Rust 重寫其熱路徑,來優(yōu)化最終解決方案。。
但在 實(shí)踐 中這樣做的難度如何呢?
用 Rust 實(shí)現(xiàn)聚類算法能快多少?
我為 RustFest 2019 準(zhǔn)備了一個(gè) 研討會(huì):我們使用 ndarray(一個(gè) NumPy 的 Rust 等效方案)從零開始實(shí)現(xiàn)了 K-Means 聚類算法。
幾周前,我寫了一些關(guān)于研討會(huì)的 筆記,相關(guān)材料 可以在 GitHub 上找到:它由一系列測試驅(qū)動(dòng)的練習(xí)構(gòu)成,每個(gè)步驟都為最終解決方案作出了貢獻(xiàn)。
我不能忽視這個(gè)問題:與 scikit-learn 相比,Rust 中 K-Means 的范例實(shí)現(xiàn)有多快?
我和一群同樣對(duì)此問題剛到好奇的人在 RustFest 度過了兩天 實(shí)現(xiàn)日,最后給出了答案。
如果沒有 @sitegui、@dunnock 和 @ThomAub,這個(gè)過程會(huì)花費(fèi)更長的時(shí)間:非常感謝你們的幫助!
實(shí)現(xiàn)
我用 Rust crate 發(fā)布了一個(gè)清理過的 K-Means 實(shí)現(xiàn):linfa-clustering(https://crates.io/crates/linfa-clustering)。linfa-clustering 是 linfa(https://crates.io/crates/linfa)的一個(gè)子集——我們稍后會(huì)詳細(xì)討論后者。
從源代碼中你可以看出來,重點(diǎn)在于清晰易懂的優(yōu)化配置:它是 Lloyd 算法 的實(shí)現(xiàn)范例。
大多數(shù)提速機(jī)會(huì)都沒有得到利用,并且肯定還有進(jìn)一步調(diào)優(yōu)和打磨的空間——例如,它只將多線程用于分配步驟,而更新步驟還是單線程的。
為了進(jìn)行正面比較,我為此編寫了 Python 綁定(https://github.com/LukeMathWalker/linfa-python):linfa is on PyPi(https://pypi.org/project/linfa/),作為 Python 庫。
我想重點(diǎn)對(duì)比一下:
- 訓(xùn)練時(shí)間;
- 推理時(shí)間,模型 作為一個(gè) gRPC 微服務(wù) 公開時(shí)所測得的時(shí)間。
我們測量將模型作為微服務(wù)公開來提供預(yù)測需要的時(shí)間,這更接近在實(shí)際生產(chǎn)環(huán)境中使用此代碼的表現(xiàn)。
你可以在 GitHub 上獲得重現(xiàn)基準(zhǔn)測試的說明、結(jié)果和代碼(https://github.com/LukeMathWalker/clustering-benchmarks)。
訓(xùn)練基準(zhǔn)測試
使用 pytest-benchmark)在一個(gè) 100 萬點(diǎn)的數(shù)據(jù)集上訓(xùn)練 K-Means 模型時(shí),linfa 的 訓(xùn)練 速度是 scikit-learn 的 1.3 倍。
庫 平均訓(xùn)練時(shí)間(毫秒)
Linfa(Rust 上的 Python 包裝器) 467.2
Scikit Learn 604.7(慢 1.3 倍)
總體而言,它們的速度比較接近——由于分配步驟是并行的,linfa 可能會(huì)稍微快一些。
如果你對(duì)這個(gè)結(jié)果感到疑惑,請(qǐng)?jiān)傧胍幌耄何覀冋趯⒁粋€(gè)只花了兩天時(shí)間的 教學(xué)研討會(huì) 實(shí)現(xiàn)與目前最完善的機(jī)器學(xué)習(xí)框架所使用的實(shí)現(xiàn)進(jìn)行比較。
太瘋狂了。
從基準(zhǔn)測試代碼中可以看到,linfa K-Means 實(shí)現(xiàn)提供了一個(gè)類似于 scikit-learn 的界面。
- from sklearn.datasets import make_blobs
- import pytest
- from linfa import KMeans
- from sklearn.cluster import KMeans as sk_KMeans
- @pytest.fixture(scope="session", autouse=True)
- def make_data():
- return make_blobs(n_samples=1000000)
- def test_k_means_rust(benchmark, make_data):
- dataset, cluster_index = make_data
- model = KMeans(3, max_iter=100, tol=1e-4)
- labels = benchmark(model.fit_predict, dataset)
- assert len(labels) == len(cluster_index)
- def test_k_means_python(benchmark, make_data):
- dataset, cluster_index = make_data
- # Using the same algorithm
- model = sk_KMeans(3, init="random", algorithm="full", max_iter=100, tol=1e-4, n_init=1)
- labels = benchmark(model.fit_predict, dataset)
- assert len(labels) == len(cluster_index)
我也想給你介紹 Rust 版本——界面看起來略有不同(出于某種原因,我可能會(huì)在另一篇博客文章中談?wù)摯耸拢悄憧梢暂p松地找出相同的步驟:
- use linfa::clustering::{generate_blobs, KMeans, KMeansHyperParams};
- use ndarray::array;
- use ndarray_rand::rand::SeedableRng;
- use rand_isaac::Isaac64Rng;
- fn main() {
- // Our random number generator, seeded for reproducibility
- let mut rng = Isaac64Rng::seed_from_u64(42);
- // For each our expected centroids, generate 1000 data points around it (a "blob")
- let expected_centroids = array![[10., 10.], [1., 12.], [20., 30.], [-20., 30.]];
- let dataset = generate_blobs(10000, &expected_centroids, &mut rng);
- // Configure our training algorithm
- let n_clusters = 4;
- let hyperparams = KMeansHyperParams::new(n_clusters)
- .max_n_iterations(200)
- .tolerance(1e-5)
- .build();
- // Infer an optimal set of centroids based on the training data distribution
- let model = KMeans::fit(hyperparams, &dataset, &mut rng);
- // Assign each point to a cluster using the set of centroids found using `fit`
- let labels = model.predict(&dataset);
- }
推理基準(zhǔn)測試
如前所述,使用一個(gè)專用微服務(wù)為機(jī)器學(xué)習(xí)模型提供服務(wù),在業(yè)界已是一種既定模式。
但在這些微服務(wù)中,往往很少或幾乎沒有業(yè)務(wù)邏輯:它們無非就是一個(gè) 遠(yuǎn)程函數(shù)調(diào)用 而已。
給定一個(gè)序列化的機(jī)器學(xué)習(xí)模型,我們是否可以完全自動(dòng)化 / 抽象 API 生成?隨著 Tensorflow Serving 越來越受歡迎,我的想法得到了驗(yàn)證。
因此我決定針對(duì)三種場景進(jìn)行基準(zhǔn)測試:
- scikit-learn 的 K-means 運(yùn)行在 Python 的 gRPC 服務(wù)器上;
- linfa 的 K-means(Python 包裝器)運(yùn)行在 Python 的 gRPC 服務(wù)器上;
- linfa 的 K-means(Rust)運(yùn)行在 Rust 的 gRPC 服務(wù)器(tonic,https://github.com/hyperium/tonic)上。
我尚未在這些 gRPC Web 服務(wù)器上做任何形式的調(diào)優(yōu):我們要評(píng)價(jià)的是開箱即用的性能。我再次邀請(qǐng)你查看源代碼(Rust/Python)。
Rust Web 服務(wù)器上的 linfa 每秒處理的請(qǐng)求數(shù)是 scikit-learn 的 25 倍,是 python gRPC 服務(wù)器上的 linfa(Python 包裝器)的 7 倍。
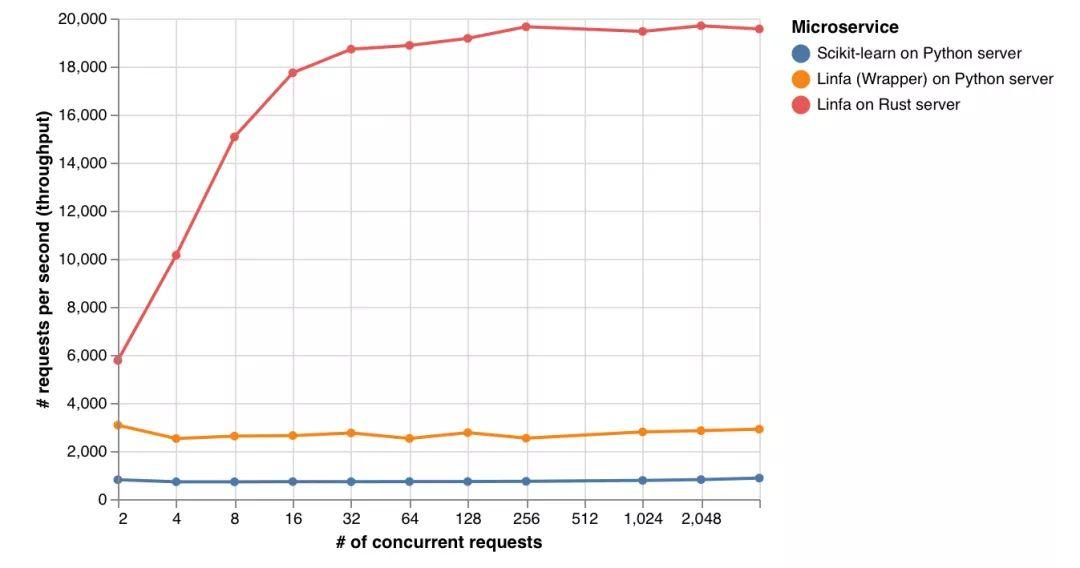
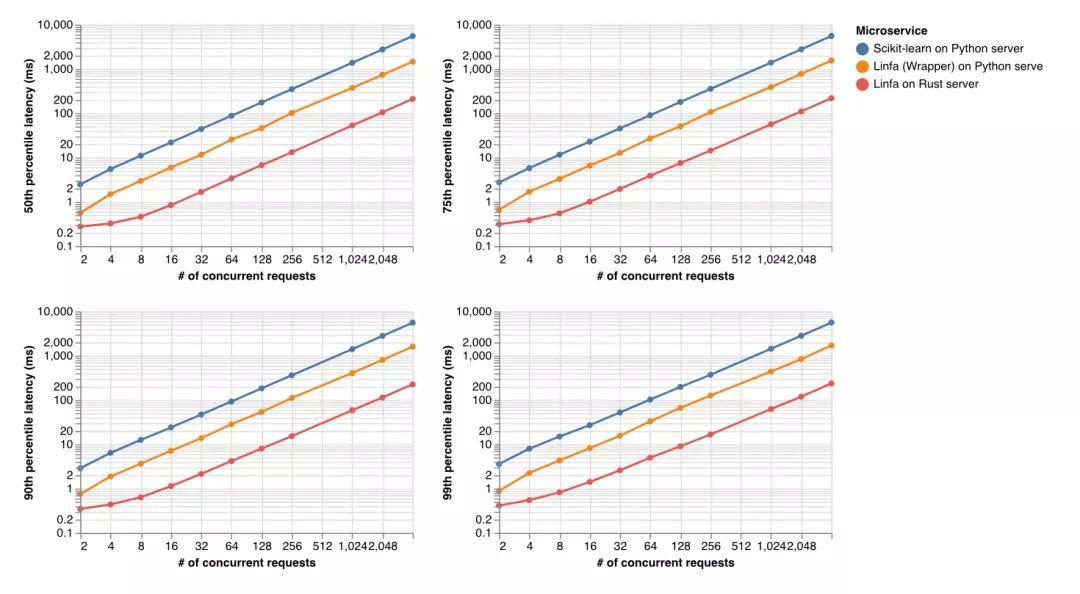
延遲(提供響應(yīng)需要多長時(shí)間)也是如此,其中 Rust Web 服務(wù)器上的 linfa 始終 比 scikit-learn 快 25 倍,比 Python Web 服務(wù)器上的 linfa(Python 包裝器)快 6 倍。
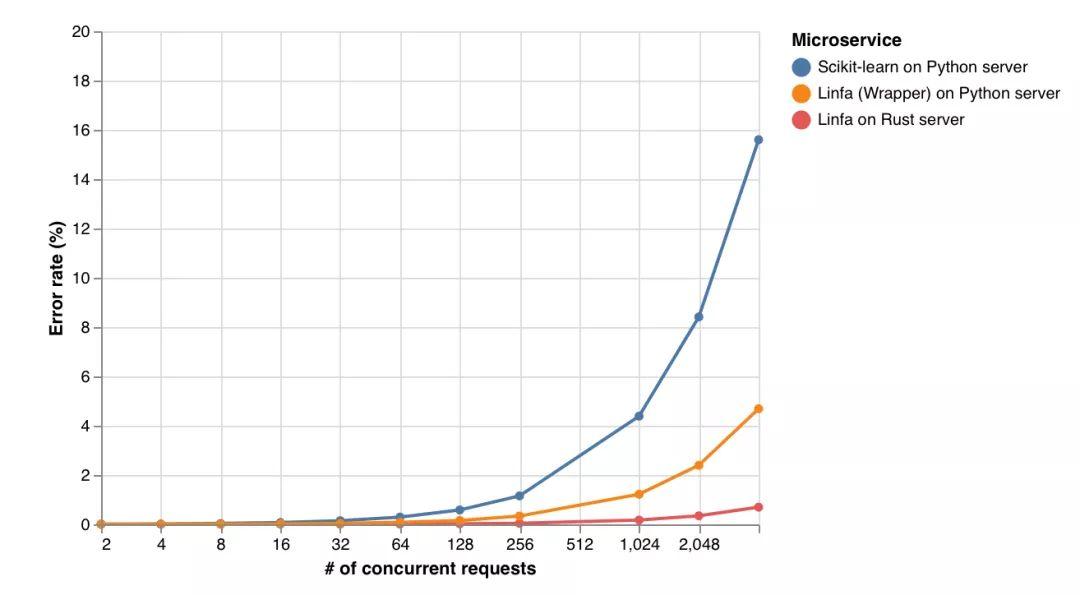
Rust Web 服務(wù)器上的 linfa 在重負(fù)載下的錯(cuò)誤率也是最低的。
新的工作流
這項(xiàng)實(shí)驗(yàn)規(guī)模太小,無法得出確切的結(jié)論,而且我相信你可以找到針對(duì) K-Means 的 Lloyds 算法的更快實(shí)現(xiàn)。
但我希望這些結(jié)果足以說服你,Rust 確實(shí)可以在機(jī)器學(xué)習(xí)開發(fā)中發(fā)揮重要作用。所有人只要學(xué)一些 ndarray 的用法(可以試試研討會(huì)提供的材料),就可以寫出這樣的 Rust 實(shí)現(xiàn)——可就因?yàn)?C 和 C++ 的入門門檻,大批機(jī)器學(xué)習(xí)從業(yè)者浪費(fèi)了多少潛能?
如果這還不夠,我還想告訴你,Rust 不僅可以替換掉 Python 的 C 和 C++ 后端——它還可以利用其不斷發(fā)展的異步生態(tài)系統(tǒng)來處理部署工作。
做起來很簡單:
- 使用基于 Rust 的 Python 庫識(shí)別候選模型;
- 序列化最終模型;
- 提供最終模型的路徑和輸入數(shù)據(jù)的預(yù)期模式作為配置;
- 收獲果實(shí)吧。
這絕對(duì)是一個(gè)值得在 2020 年探索的想法。
走下去
如前所述,linfa-clustering 是 linfa 的子集,后者是 Rust 中的通用機(jī)器學(xué)習(xí)框架,我計(jì)劃在 2020 年專注研究這個(gè)框架。
甚至在此時(shí)將其稱為一個(gè)框架還為時(shí)過早:linfa-clustering 之外就沒什么東西了😀。
要實(shí)現(xiàn)其大膽的使命宣言還有很長的路要走,但在機(jī)器學(xué)習(xí)及其相關(guān)領(lǐng)域,對(duì) Rust 生態(tài)系統(tǒng)的興趣愈加濃厚:https://github.com/rust-ml/discussion/issues/1,https://github.com/rust-lang/wg-governance/issues/11,https://github.com/rust-lang/wg-governance/issues/11。
有時(shí)你只需點(diǎn)燃星星之火,即可期待它熊熊燎原。
實(shí)際上,我堅(jiān)信只有社區(qū)努力推動(dòng),才能在 Rust 中扶持、建立和維持一個(gè)機(jī)器學(xué)習(xí)生態(tài)系統(tǒng)——并沒有捷徑可言。
Rust 生態(tài)系統(tǒng)確實(shí)包含豐富的機(jī)器學(xué)習(xí) crates——看看在 crates.io 上搜索 machine learning 會(huì) 返回 多少東西吧。
我們無需從頭開始重寫所有內(nèi)容:我將 linfa 視為一個(gè)元包,一個(gè) Rust 生態(tài)系統(tǒng)中精選的算法實(shí)現(xiàn)的集合。它是滿足你機(jī)器學(xué)習(xí)需求的第一站,就像是 Python 中的 scikit-learn 一樣。
如果這篇文章引起了你的共鳴,請(qǐng)看一看路線圖 (https://github.com/LukeMathWalker/linfa/issues)——我期待你的貢獻(xiàn)!