本來以為過年了要好好寫文章,因為疫情的關系,新增的不少的需求。希望這場疫情早日過去吧,武漢加油。今天我們來聊一聊數據庫遷移,這個其實非常的常見,例如我們要從自己的機房將數據遷移到騰訊云或者阿里云這些線上服務,或者我們有時候需要把一個業務拆分成多個子業務,為了減少系統的耦合,我們通常也會選擇拆庫,這就需要進行數據遷移。很多公司,在進行數據遷移的時候,都會選擇停服來處理,這是一種偷懶的方法,數據遷移能不能做到不停服呢?今天我們來介紹下這個高速換輪胎的技術,數據庫遷移。
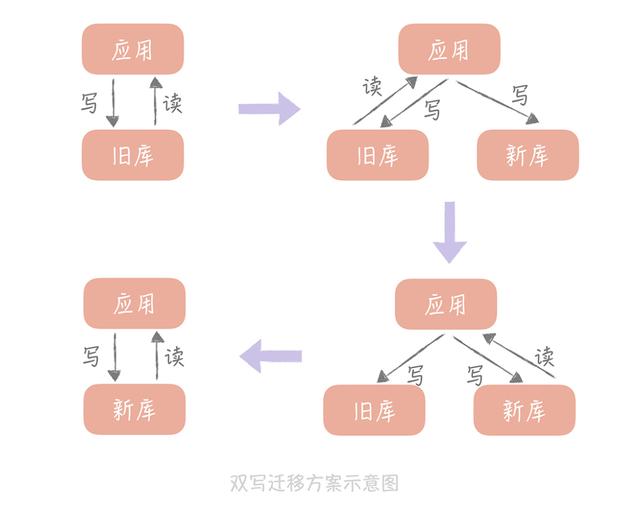
這個是最常見的數據遷移的一個流程。一開始,我們的應用都是讀寫舊的數據庫,這個時候我們還沒有開啟數據遷移。緊接著,我們會有一個新的數據庫,一般來說,這個時候,我們會開啟雙寫,什么是雙寫呢?就是對數據庫的寫操作,我們既寫到舊庫,又寫到新庫。如果擔心因為雙寫而造成的耗時增加,我們可以選擇異步同步的模式,但是異步勢必增加了系統的復雜性,我們需要把失敗的日志記錄下來,以便后期進行處理。
在第二步的時候,我們仍然是讀取舊數據庫的數據,這個時候對線上的業務幾乎是沒有影響的,接下來,我們可以準備讀取新庫的數據,為了減小影響,我們可以采用一定的灰度策略,先讓部分流量讀取新庫,然后再慢慢擴大灰度范圍,這個時候所有的寫請求還是雙寫的,一旦發現有問題,可以回退到第二步甚至是第一步,減少對業務的影響。當服務穩定下來之后,我們可以去掉對舊庫的寫入,這樣子就能完成一次數據遷移。
相信很多人會問,說的容易。那么對于歷史數據,怎么遷移到新庫呢?這里我們介紹兩種常見的方法,一是懶惰遷移,二是主動遷移。什么是懶惰遷移呢?這個是從英文單詞Lazy翻譯過來的,就是如果這行數據沒有被使用到,我們就不管他,如果它被使用到,那么我們就把它遷移過來。一般我們會使用一個key-value來記錄下哪些key被懶惰遷移過,當我們更新舊表的時候,如果發現這個key沒有被遷移,那么就順路把他寫到新表里面,并且更新下鍵值數據,表示這個key已經被遷移過了,后面雙寫的時候,直接雙寫即可,無需進行數據遷移。
另外一個是主動遷移,有些數據,可能在進行數據遷移的時候就沒被訪問過,例如用戶可能幾個月不登錄,你不能因為數據遷移就把他拋棄了。所以我們需要對這些冷數據進行數據遷移,簡單來說,就是掃取數據庫中的存量數據,然后將他們寫入新的數據庫即可。