













程序員必備!關系型數據庫架構的超強總結
1. 前言
本文總結一下接觸過的關系型數據庫常用的幾種架構及其演進歷史。
分析數據庫架構方案的幾個視角用發生故障時的高可用性、切換后的數據一致性和擴展性。每個產品都還有自己獨特的優勢和功能,這里不一定會提到。
2. Oracle數據庫的架構方案
ORACLE數據庫既能跑OLTP業務,也能跑OLAP業務,能力是商業數據庫中數一數二的。支持IBM小機和x86 PC服務器,支持多種OS。同時有多種數據庫架構方案供選擇,成本收益風險也各不相同。
A. IBM AIX HACMP + ORACLE9I + EMC
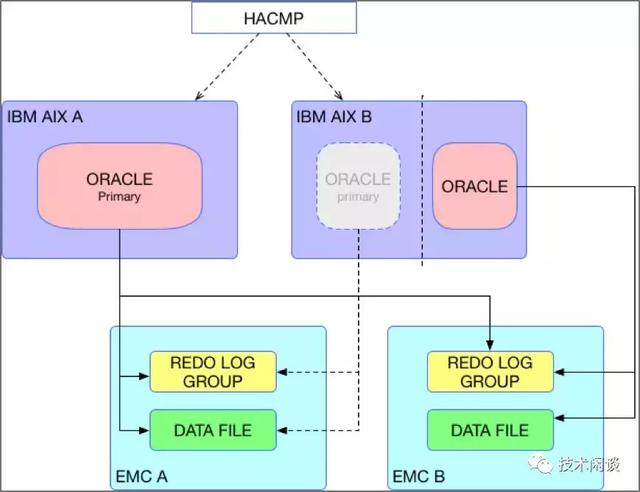
圖 1 :IBM AIX HACMP + ORACLE9I + EMC
架構說明:
1. 兩臺IBM AIX A和B。AIX A運行Oracle Primary實例,AIX B分出部分資源虛擬一個OS C,運行Oracle Standby實例。AIX B剩余大部分資源空閑,用于未來起另外一個OraclePrimary實例。
2. 兩臺存儲(EMC只是舉例)A和B,分別直連兩臺AIX A和B。存儲A存放Primary實例的日志和數據,也存放Standby實例的Redo(圖中未畫出,只有在角色未Primary時有效)。存儲B存放Standby實例的日志和數據,也存放Primary實例的Redo文件。
3. AIX也可以換普通的x86_64 PC服務器,HACMP換為支持linux的集群軟件。如Veritas HA。
功能:
1. 高可用:Oracle Primary實例不可用時,HACMP起用AIX B上的Oracle Primary實例。存儲A不可用時,將AIX C上Standby實例Failover為Primary實例。
2. 數據一致性:Redo文件在兩個存儲上都有保留,Standby實例在Failover之前應用Primary的Redo,理論上即使是Failover也不丟數據。
3. 擴展性:數據庫性能由主機aix和存儲能力決定,都可以向上擴展,成本會陡升,且有上限。
B. x86 + ORACLE RAC + EMC
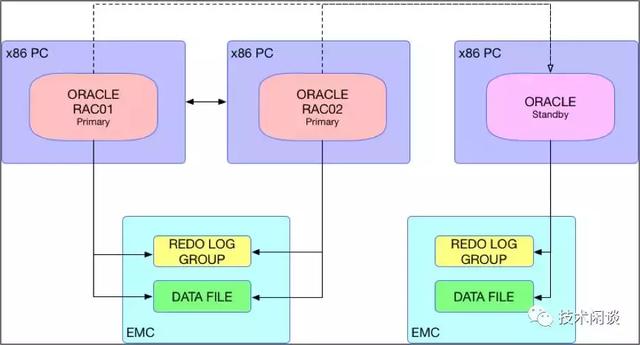
架構說明:
1. 兩臺主機A和B可以是AIX,也可以是x86_64普通PC服務器,彼此網絡直連,同時連接共享的存儲EMCA,A和B分別運行一個RAC Primary實例。
2. 主機C可以是AIX或x86_64普通PC服務器,直連另外一個存儲B,運行Standby實例。也有的架構會有多個Standby實例,其中一個Standby實例也是RAC。
功能:
1. 高可用:Oracle RACPrimary實例無論哪個不可用,另外一個都可以自動接管服務。如果Primary實例的存儲A不可用,則將Standby實例Failover為Primary實例。
2. 數據一致性:如果Primary實例也將一組Redo 成員輸出到B存儲,則理論上可以絕對不丟數據。否則,極端情況下,Failover可能會因為缺少Primary的事務日志而失敗,此時直接激活Standby實例為Primary實例,可能會丟失少量數據。
3. 擴展性:數據庫計算能力不足可以水平擴展(添加RAC節點),存儲能力不足可以向上擴展(存儲擴容)。
C. Oracle Dataguard 共享Redo
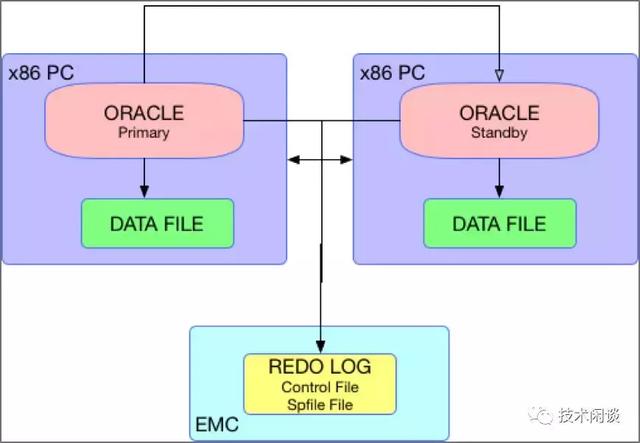
架構說明:
1. 普通x86服務器A和B,分別運行Oracle的Primary和Standby實例。彼此網絡直連,同時連接一個共享存儲。
2. Primary和Standby實例的Redo和控制文件、spfile都放在共享存儲上,所以占用空間非常小。數據文件放在本機上,通常是高速存儲(如SSD或者PCIE接口的Flash設備)。
功能:
1. 高可用:當Primary實例不可用時,將Standby實例Failover為Primary實例。如果共享存儲不可用,則兩個實例都不可用。通常會有第三個Standby實例。
2. 數據一致性:Standby實例在Failover之前應用Primary實例的Redo文件,不丟失事務日志,數據強一致。
3. 擴展性:無。
3. MySQL數據庫的架構方案
A. ADHA (Alibaba Database High Availability)
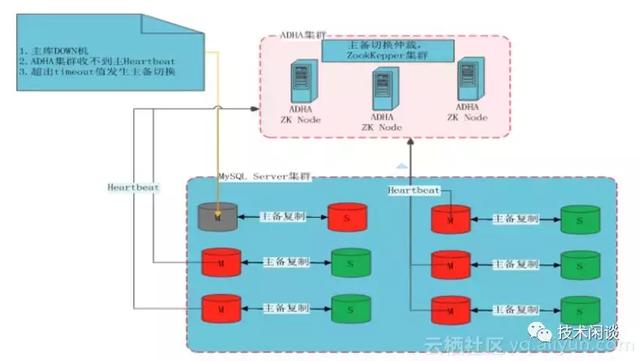
架構說明:
1. 使用MySQL Master-Master架構,雙向同步,Slave只讀。
2. 使用Zookeeper集群做實例不可用監測和防止腦裂。
功能:
1. 高可用:Master實例不可用后,將Slave激活。可用性優先。如果Slave延時超出一定閥值,放棄切換。zk集群三節點部署,可以防止腦裂。
2. 數據一致性:為盡可能少的減少數據丟失,推薦開啟單向半同步技術。同時在老Master恢復后會盡可能的彌補未及時同步到新Master的數據。由于同步依賴Binlog,理論上也是無法保證主從數據絕對一致。
3. 擴展性:可以做讀寫分離,可以新增slave擴展讀服務能力。
B. MHA (Master High Availability)
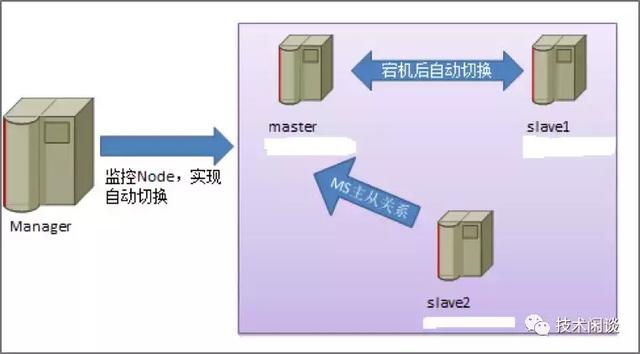
架構說明:
1. 從MySQL主從同步架構衍生出來的,使用半同步技術,所以至少有兩個從實例(Slave)。所以整體架構為一主兩從,兩個從庫不是級聯關系。
功能:
1. 高可用:Master不可用時,自動從兩個Slave里選出包含Binlog最多的Slave,并提升為Master。同時更改另外一個Slave的Master為新的Master。Master異常時,Slave上的拉取的Binlog如果有丟失(master或者slave故障時),很容易出現復制中斷,因此這種高可用機制并不總是有效。
2. 數據一致性:為了盡可能少的丟失Binlog,主從同步推薦使用半同步技術。在網絡異常的情況下,半同步有可能降級為異步同步。MHA只是盡最大程度保證數據不丟失。且由于同步依賴的是Binlog,主從的數據理論上也并不能保證嚴格一致。
3. 擴展性:可以提供讀寫分離服務,可以新增slave節點擴展讀服務能力。
C. PXC (Percona XtraDB Cluster)
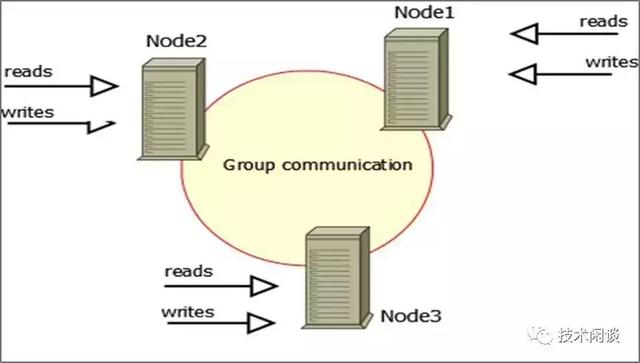
架構說明:
1. 可以兩個節點,推薦三個節點(防腦裂),組成一個Cluster。三節點同時提供讀寫服務。數據是獨立的三份,不是共享存儲。
2. 事務提交是同步復制,在所有從節點都同步提交。
功能:
1. 高可用:三節點同時提供讀寫服務,掛任意一個節點都沒有影響。
2. 數據一致性:數據強同步到所有節點,不丟數據。要求有主鍵,某些SQL不支持同步。
3. 擴展性:事務提交是同步復制,性能受限于最差的那個節點。
4. 其他:多主復制,但不能同時寫同一行數據(樂觀鎖,會報死鎖類錯誤)。另外,有寫放大弊端。
4. 分布式數據庫中間件的架構方案
A. 分布式數據庫DRDS
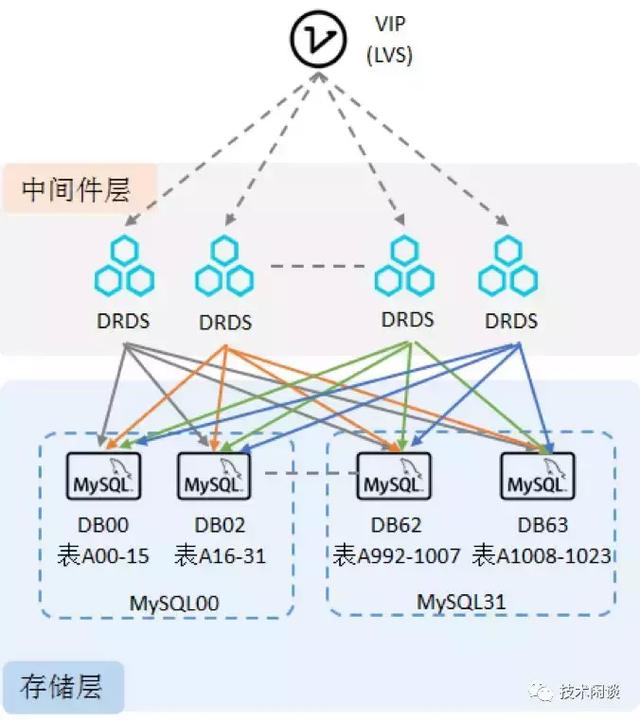
架構說明:
1. DRDS Server節點是一組無狀態的程序,響應SQL請求并做分庫分表路由轉換和SQL改寫、聚合計算等。支持庫和表兩級維度拆分,支持多種靈活的拆分策略,支持分布式事務。
2. MySQL節點主要是存儲數據、主備雙向同步架構,外加MySQL的PaaS平臺提供高可用切換、自動化運維能力。
3. 圍繞這個架構的還有數據同步組件(精衛),實現小表廣播、異構索引表等能力。
4. 該架構最新版本在只讀實例基礎上實現了MPP并行計算引擎,支持部分OLAP查詢場景。
功能:
1. 高可用:計算節點(DRDS Server節點)的高可用通過前端負載均衡設備實現,存儲節點(MySQL)的高可用靠ADHA實現。RTO在40s左右,RPO>=0。
2. 數據一致性:MySQL主備同步是半同步或者異步。ADHA最大可能的降低MySQL故障切換時的主備不一致概率,理論上無法保證絕對強一致,RPO>=0。
3. 擴展性:計算和存儲節點都可以分別擴容。存儲的擴容通過MySQL實例的增加以及數據的遷移和重分布等。
4. 運維:故障時,主備強切后,會有一定概率出現主備同步因為數據不一致而中斷。
B. 分布式數據庫TDSQL
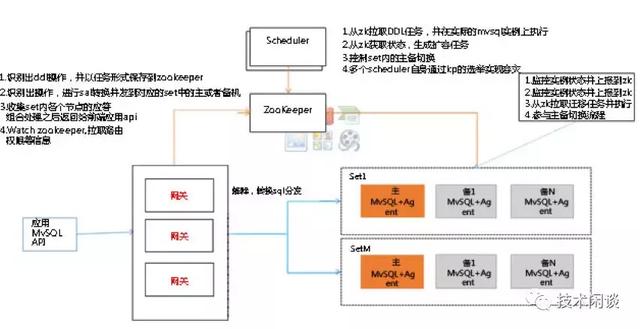
架構說明:
1. 計算節點:由一組無狀態的網關節點組成,負責SQL路由、MySQL主故障時的路由切換等。
2. 調度系統:用zk集群做元數據管理、監測故障和做數據庫故障切換、彈性伸縮任務等。
3. 存儲節點:MySQL主備架構,一主兩從,做強同步或者異步同步。
4. 支持全時態數據模型
功能:
1. 高可用:網關前端推測也有負載均衡,MySQL主備切換依賴zk判斷,RTO在40s左右
2. 數據一致性:一主兩備使用強同步的時候,基本可以保證RPO=0. 如果是異步,可能切換時會有延遲。
3. 擴展性:通過提升網關能力或者個數來提升計算能力,增加MySQL節點數然后調整數據分布來提升計算和存儲能力。
4. 運維:異常時,可能出現主備由于數據不一致導致同步服務中斷,需要修復。
C. 分布式數據庫 GoldenDB
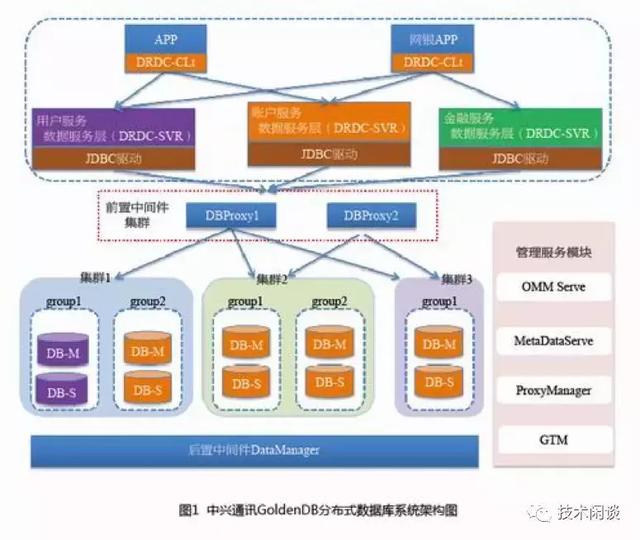
架構上也是分庫分表,跟DRDS原理基本相同。
D. 分布式數據庫 MyCat
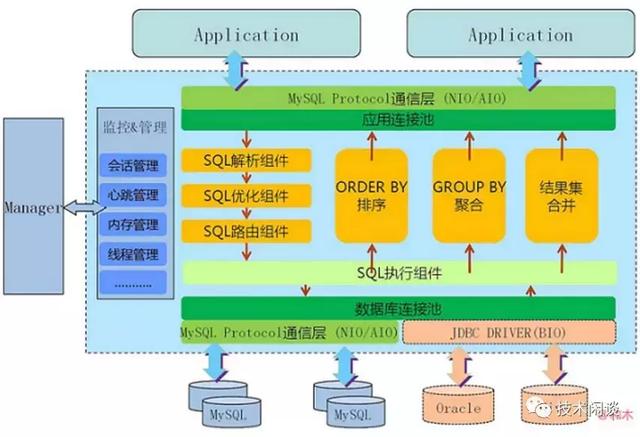
架構原理和功能跟前面兩類基本相同。底層存儲節點還支持Oracle和Hive。
E. 分布式數據庫 HotDB
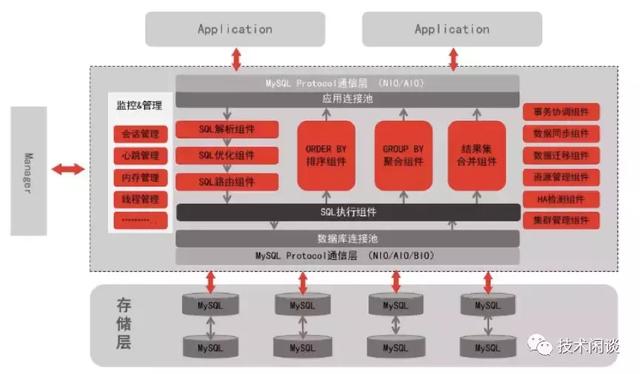
5. 分布式數據庫
A. Google的F1
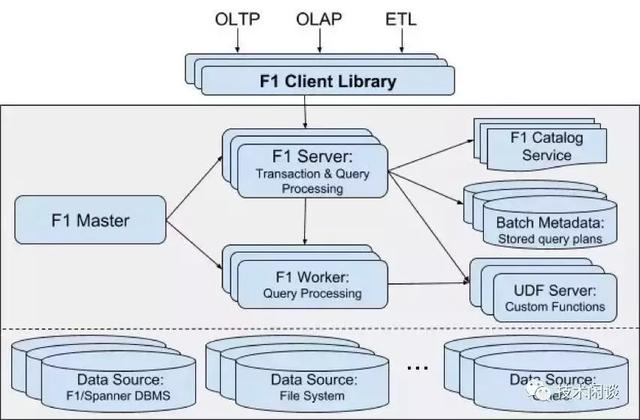
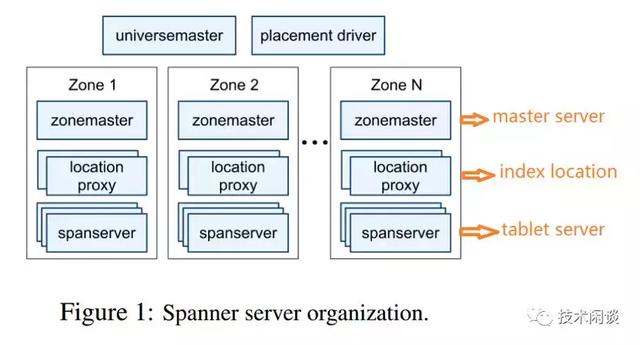
說明:
1. F1支持sql,底層可以支持MySQL和Spanner。選擇Spanner原因主要是Spanner不需要手動分區、使用Paxos協議同步數據并保證強一致以及高可用。
2. Spanner分為多個Zone部署。每個zone有一個zonemaster(管理元數據和spannerserver)、多個spannerserver。
3. Spanner的數據存儲在tablet里,每個tablet按固定大小切分為多個directory。Spanner以directory為單位做負載均衡和高可用,paxos group是對應到directory的。
4. Spanner的TrueTime 設計為分布式事務實現方案提供了一個新的方向(分布式MVCC)。
B. PingCap的TiDB
TiDB主要是參考Google的Spanner和F1的設計,架構上有很多相似的地方。
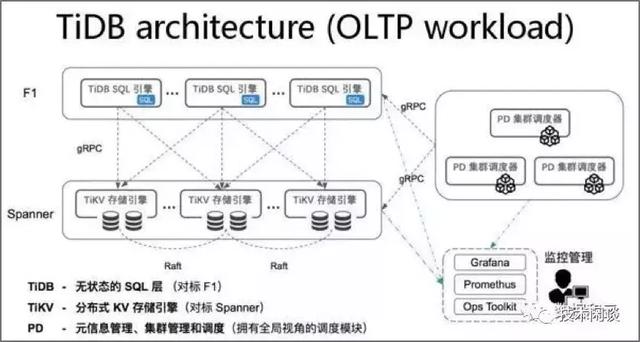
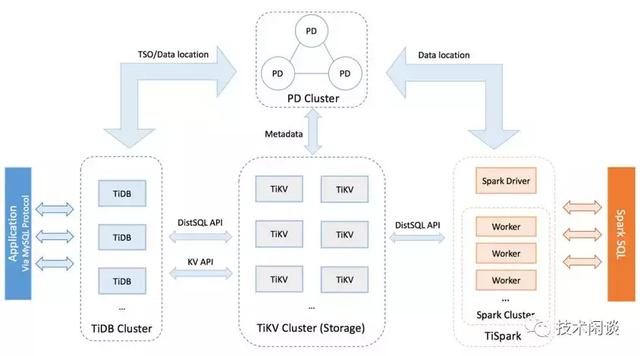
架構說明:
1. TiDB server負責處理SQL并做路由。無狀態,可以部署多個節點,結合負載均衡設計對外提供統一的接入地址。
2. PD Server 是集群的管理模塊,存儲元數據和對TiKV做任務調度和負載均衡,以及分配全局唯一遞增的事務ID。
3. TiKV Server 是存儲節點,外部看是Key-Value存儲引擎,表數據自動按固定大小(如20M,可配置)切分為多個Region分散在多臺TiKV Server上。Region是數據遷移和高可用的最小單位,Region的內容有三副本,分布在三個區域,由Raft協議做數據同步和保證強一致。
4. 支持分布式事務,最早實現全局一致性快照。支持全局一致性備份。
5. 兼容MySQL主要語法。
功能:
1. 可用性:計算節點無狀態部署,結合負載均衡設計保證高可用和負載均衡。存儲節點是三副本部署,使用Raft協議維持三副本數據一致性和同步,有故障時自動選舉(高可用)。
2. 擴展性:計算和存儲分離,可以單獨擴展。存儲節點擴展后,數據會重新分布,應該是后臺異步任務完成,不影響業務讀寫,可以在線擴容。可以用于做異地容災,兩地三中心異地多活(三機房之間網絡延時很小)
3. 數據一致性:計算節點故障不會導致數據丟失,存儲節點故障會自動選舉,新的leader跟老的leader數據是強一致的。
C. Alipay的OceanBase
OceanBase的設計思路跟Spanner類似,但在SQL、存儲、事務方面都有自己的創新。
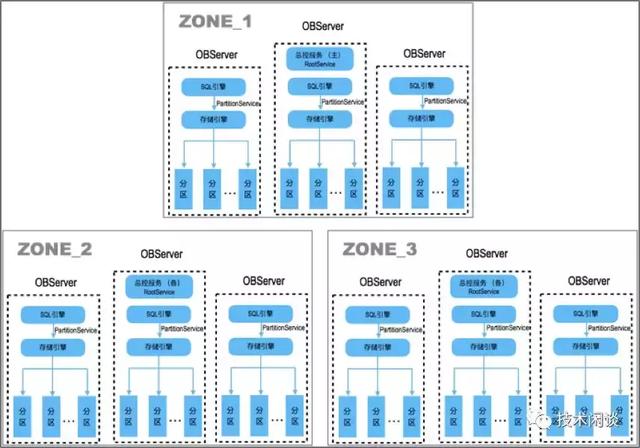
架構說明:
1. 目前版本計算和存儲都集中在一個節點上(PC,OBServer)上,單進程程序,進程包括SQL引擎和存儲引擎功能。
2. 表數據存在一個或多個分區(使用分區表),需要業務指定分區規則。分區是數據遷移和高可用的最小單位。分區之間的一致性是通過MultiPaxos保證。
3. 支持分布式事務、2.x版本支持全局一致性快照。支持全局一致性備份。
4. 兼容MySQL主要用法和Oracle標準SQL用法,目前正在逐步兼容Oracle更多功能。如存儲過程、游標和Package等。目標是兼容Oracle常用功能以實現去IOE時應用不修改代碼的目標。
5. 有多租戶管理能力,租戶彈性擴容,租戶之間有一定資源隔離機制。
6. 應用可以通過一個反向代理obproxy或者ob提供的connector-java訪問OceanBase集群。
跟Spanner的關系和區別:
1. Spanner大概2008年開始研發,2012年通過論文對外公開。首次跨地域實現水平擴展,并基于普通PC服務器實現自動高可用和數據強一致。OceanBase在2010年開始立項研發,也是基于普通PC服務器,發展出自己獨特的ACID特性和高可用技術以及拆分技術。
2. Spanner對標準SQL支持不好,不是真正的關系型數據庫,定位于內部應用。OceanBase定位于通用的分布式關系型數據庫,支持標準SQL和關系模型。基本兼容MySQL功能,逐步兼容Oracle功能。
3. Spanner借助原子鐘硬件和TrueTime設計支持全局一致性快照,提供快照讀隔離級別,對節點間網絡延時要求比較高。OceanBase使用軟件提供全局時間服務,實現了全局一致性快照功能。
4. Spanner的內部診斷跟蹤機制很欠缺,OceanBase的內部診斷分析機制功能很完善,是瞄準商業軟件標準去做的。
功能:
1. 擴展性:租戶和集群的彈性伸縮非常方便,可以在線進行,對業務寫影響可控。可以用于兩地三中心異地容災和多活(結合業務做單元化設計)。
2. 可用性:單個或多個observer不可用時,只要分區的絕大部分成員存活,則可以迅速選舉恢復服務(RTO=20s)。
3. 數據一致性:故障恢復后,數據庫數據絕對不丟。RPO=0。


















