疫情之下,如何設計百萬并發的IM系統?
近期隨著武漢新型肺炎疫情的蔓延,很多教育機構也提供了“停課不停學”的在線直播教學服務,這也是一大直播互動場景。
圖片來自 Pexels
IM 系統的高并發場景
IM 系統中,高并發多見于直播互動場景。比如直播間,在直播過程中,觀眾會給主播打賞、送禮、發送彈幕等,尤其是明星直播間,幾十萬、上百萬人的規模一點也不稀奇。
直播互動場景具有這樣的特點:流量峰值具有“短時間快速聚集”的突發性、流量隨著開播和結束而劇烈波動,因而會帶來很大的高并發壓力。
IM 系統的高并發解決方案
網關全量轉發
我們先看兩張圖:
可以看到這兩張圖很像,但也有不同之處。
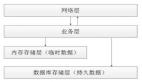
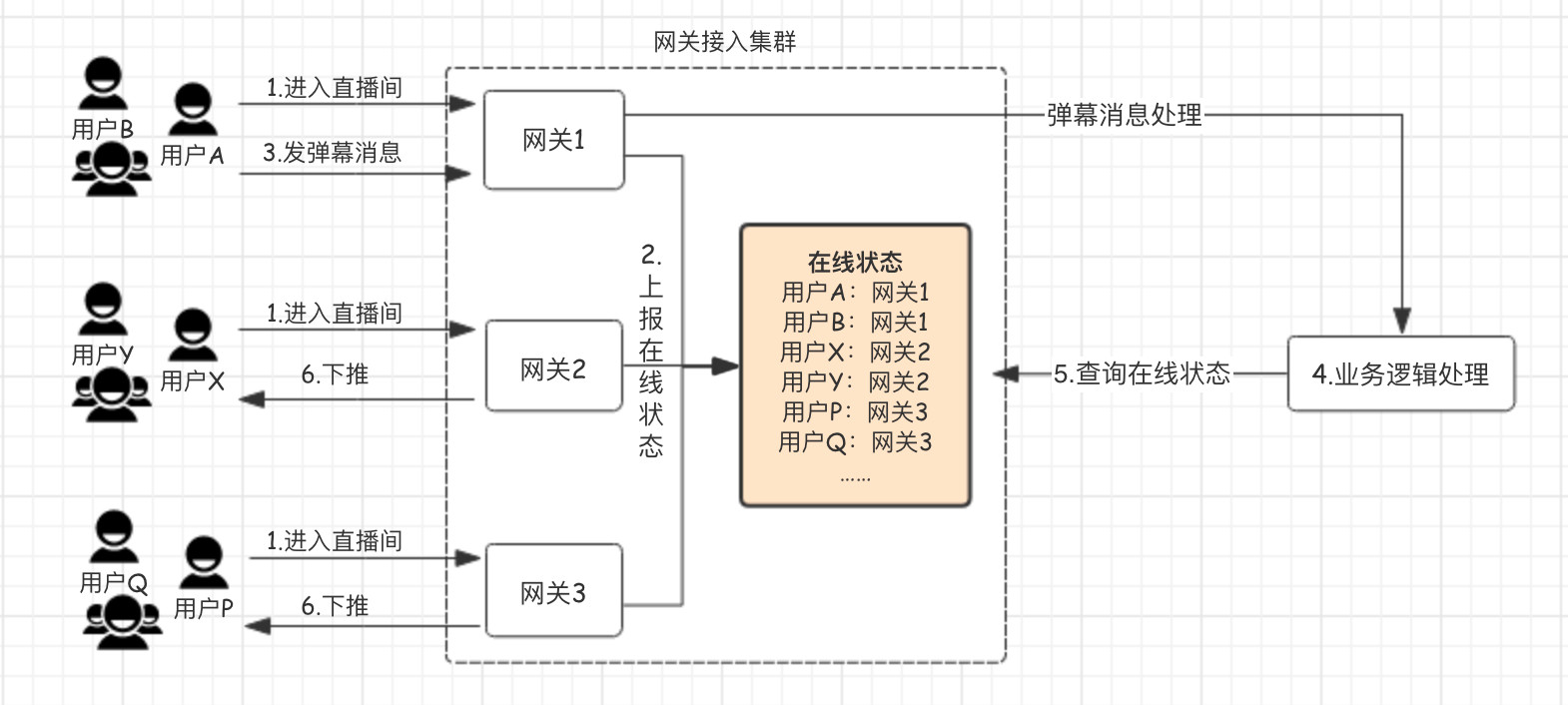
上面的圖是普通聊天場景的流程圖:
- 用戶通過網關機進入直播間。
- 網關會保存、維護所有進入直播間用戶的在線狀態。
- 用戶 A 發送一條彈幕消息,經過一系列處理。
- 通過網關機維護的用戶在線狀態,查詢出同一直播間其他用戶的網關機,將消息投遞到這些網關機上。
- 網關機將消息推送給用戶的設備。
也就是:通過維護一個全局的“在線狀態”,邏輯層在確定好接收人后,通過這個“在線狀態”查詢接收人所在的網關機,將消息投遞給這臺網關機,最后由網關機通過長連接進行投遞。
問題來了!如果是一個 10w 人的直播間,每發送一條消息,就要對這個“在線狀態”進行 10w 次的查詢,更何況是多人、高頻的消息發送呢?
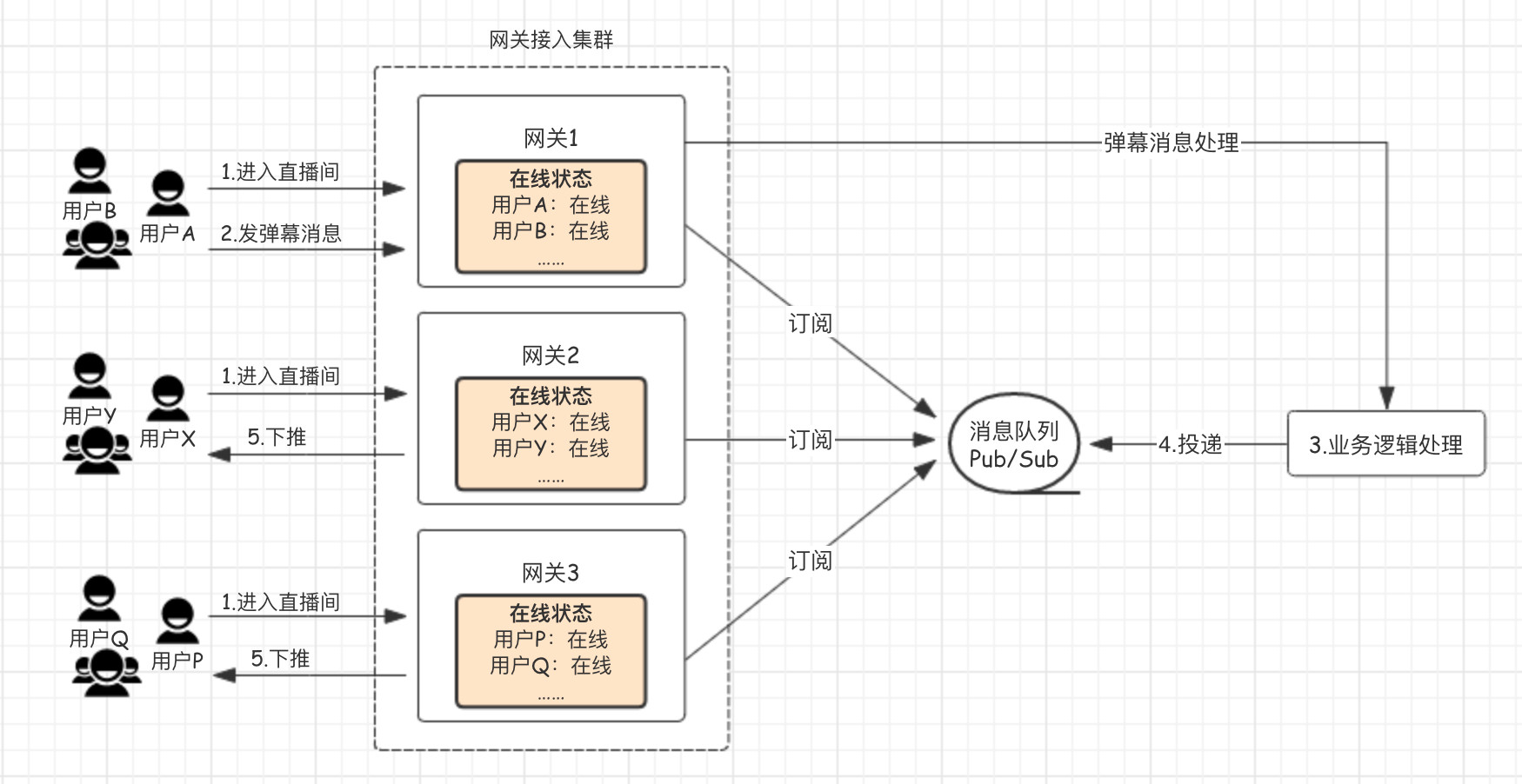
下面的圖是基于上面的流程進行優化后的流程圖,更適用于高并發聊天場景:
- 用戶通過網關機進入直播間,會在每臺網關機本機維護“在線狀態”。
- 用戶 A 發送一條彈幕消息,經過一系列處理,投遞給消息隊列,而每臺網關機均訂閱了這個全局的消息隊列,因而都能收到消息。
- 網關機通過本機維護的用戶在線狀態,將消息推送給用戶的設備。
這個優化的核心就是:不再去精準地確認這個直播間的用戶在哪些網關機上,而是將這個直播間的消息全量投遞給網關機,再由網關機將消息下推給本機連接的用戶設備,也就是下推服務不依賴外部狀態服務。
微服務拆分
對所有業務進行拆分:
- 核心服務:如發彈幕、點贊、打賞等。
- 非核心服務:如直播回放、第三方系統的同步等。
核心服務通過 DB 從庫或者消息隊列的方式與非核心服務解耦依賴,避免被直接影響。
對核心服務進行梳理:容易出現瓶頸點的服務和基本不會有瓶頸的服務。容易出現瓶頸的長連接入服務獨立部署,并且和用戶發送消息的上行操作拆分成各自獨立的通道,這樣能夠使消息上行通道、和推送下行通道互相隔離。
自動擴縮容
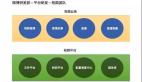
直播互動場景的監控指標一般可以分為兩大類:
- 業務性能指標,比如直播間人數、發消息和信令的 QPS 與耗時、消息收發延遲等。
- 機器性能指標,主要是通用化的機器性能指標,包括帶寬、PPS、系統負載、IOPS 等。
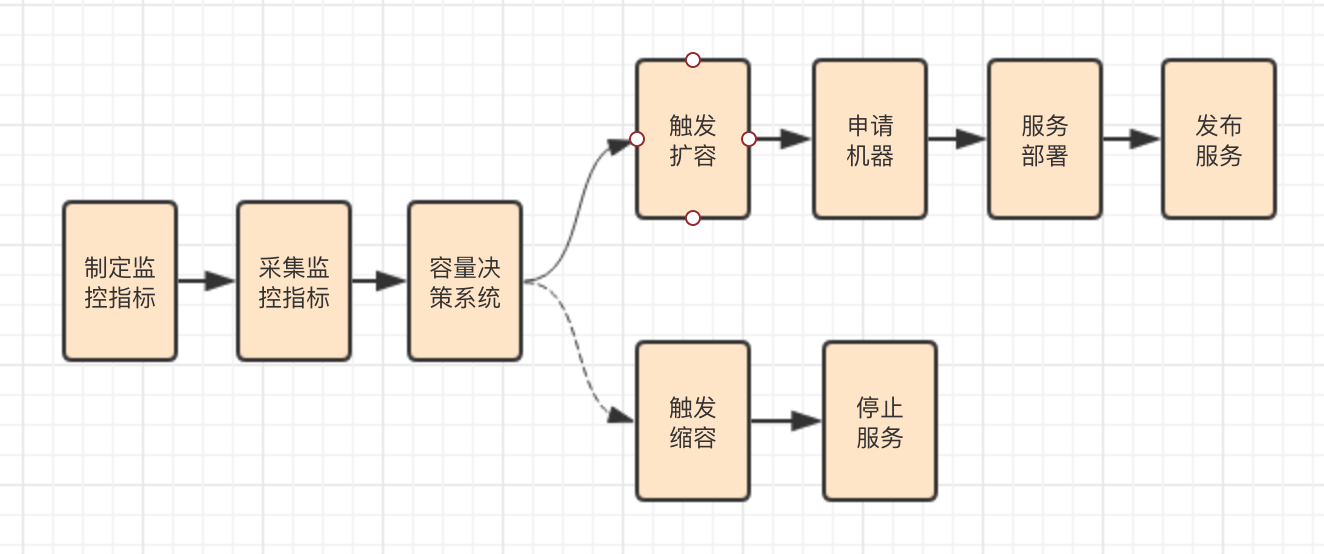
通過收集業務性能指標或者機器性能指標,結合模擬線上直播間數據來進行壓測,找出單機、中央資源、依賴服務的瓶頸臨界點,制定相應的觸發自動擴縮容的指標監控閾值,實現自動化。
智能負載均衡
擴容可能會出現舊機器和新機器對于新增流量負載不均衡的問題。
對于長連接入服務前端的負載均衡層來說,大部分都采用普通的 Round Robin 算法來調度,并不管后端的長連接入機器是否已經承載了很多連接。
這樣會導致后續新的連接請求還是均勻地分配到舊機器和新機器上,導致舊機器過早達到瓶頸,而新機器沒有被充分利用。
這是因為負載均衡層支持自定義的均衡算法只能在某一臺負載均衡機器上生效,無法真正做到全局的調度和均衡。最好的辦法是接管用戶連接的入口,在最外層入口來進行全局調度。
比如,在建立長連接前,客戶端先通過一個入口調度服務來查詢本次連接應該連接的入口 IP,在這個入口調度服務里根據具體后端接入層機器的具體業務和機器的性能指標,來實時計算調度的權重。
負載低的機器權重值高,會被入口調度服務作為優先接入 IP 下發;負載高的機器權重值低,后續新的連接接入會相對更少。
小結
上面的一些應對高并發的舉措,不僅僅可以用于直播互動場景,也適用于其他業務場景,而選用什么策略往往是根據業務需求而定。
比如上面提到的全量網關轉發,假如有 50 臺網關節點,原來每臺網關節點只需要取 1 條消息,現在卻需要取 50 條消息,其中有 49 條是無效的。
為了避免每條消息都查詢用戶的在線狀態,所有的消息都發送給所有的網關節點,會造成每臺網關機器的流量成倍數增長和資源的浪費,但這是應對高并發的一個有效方式。
如果是點對點場景,使用全局在線狀態來精確投遞是更好的選擇,如果是群聊和直播的場景推薦使用所有網關來訂閱全量消息的方式,而采用什么方式根據需要來權衡。