













人類終于創造了惰性人工智能……
許多文章解釋了強化學習(RL)的概念,但鮮有文章解釋如何切實地設計實現現實世界中的強化學習。
小芯這次想分享人工智能范式轉變課程,討論設計權衡問題,并深入研究技術細節。
那么,我們開始吧!
首先,喝酒?
想象一下你身處聚會,有點微醺或酩酊大醉,自愿參加一個飲酒游戲,想要打動一個(或多個)頗具魅力的泛泛之交。
有人蒙住你的眼睛,給你一杯或一瓶啤酒,喊道:“倒酒!”
你會怎么做?
可能會有以下反應:該死,我應該怎么做?怎樣能贏!要是輸了怎么辦!?
游戲規則如下:在10秒內把啤酒灌滿,盡可能接近玻璃杯上的標記。可以把啤酒倒進倒出。
RL(強化學習)解決方案面臨著類似的任務,高大上且有意義,歡迎了解。
現實世界中的啤酒問題
環保共享單車業務存在一個大問題。一天中,每個單車停放處(杯)的共享單車(啤酒)數量過多或不足。
紐約市單車停放處的單車過剩(左圖)和不足(右圖)
對于騎自行車的人來說,這十分不便,并且要花費數百萬美元來管理運營,也不劃算。不久前,筆者在紐約大學的團隊任務是提供人工智能解決方案,將人工干預降到最小,幫助管理自行車庫存。
目標:每天將各個單車停放處的數量保持在1至50之間(想想杯子上的標記)。這在共享經濟中被稱為“再平衡問題”。
限制條件:由于運營限制,團隊每天每小時只能移動1、3或10輛單車(可以倒入或倒出的啤酒量)。當然,他們可以選擇什么都不做。團隊移動的單車越多,價格越昂貴。
惰性RL(強化學習)解決方案
團隊決定使用RL (強化學習),它克服了傳統方法的許多局限(例如基于規則和預測)。
如果想了解RL(強化學習)以及一些關鍵概念,喬納森·輝(JonathanHui)撰寫了一篇很棒的介紹,托馬斯·西蒙尼尼(ThomasSimonini )詳細解釋了解決方案中應用的RL算法Q-Learning。
事實證明,人類創建了極具惰性的人工智能。當單車存量超過60輛時,它通常會選擇不執行任何操作或執行最少操作(移動1或3輛自行車)。似乎有違常理,但這是非常明智的。
根據直覺,可能會移動盡可能多的單車以將其保持在50輛以下,尤其是在停放處停滿時。但是,RL(強化學習)識別出移動成本(移動的單車越多,成本越高)以及在某些情況下成功的機會。考慮到所剩時間,根本不可能實現目標。它知道最好的選擇是“放棄”。因此,放棄比繼續嘗試要付出更少的代價!
所以呢?當人工智能做出非常規決策時,類似于谷歌Alpha Go研發的著名Move 37 and 78 ,它們會挑戰人類的偏見,幫助打破知識的魔咒,并將人類推向未知的道路。
創造人工智能既是一種發明,也是一種探索人類內心活動的旅程。——DeepMind創始人德米斯·哈薩比斯 (Demis Hassabis)在《經濟學人》雜志《2020年的世界》(The World in 2020)一文中所言。
但是,請保持謹慎。人類價值體系無可替代,因此人類不會一落千丈或迷失自我。
哲學知識已經足夠了,現在現實一點吧
RL如何管理單車停放處?
下圖顯示了在有無RL的情況下,一天當中單車的停放量。
- 藍色線是無RL情況下的單車停放趨勢。
- 黃色線是最初RL情況下移出單車的趨勢,很昂貴。
- 綠色線是訓練有素的RL,它僅移出足以滿足目標的單車,更能了解成本。
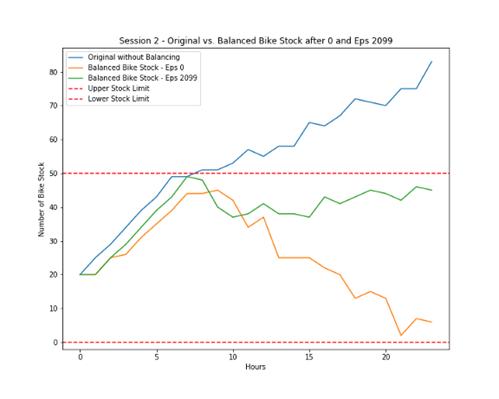
作者分析
RL如何決定該做什么?
以下是經過98,000次訓練后RL解決方案Q表的快照。它解釋了RL如何根據停放處(垂直數據)上的自行車數量來決定做什么(水平數據)。RL不太可能選擇用紅色進行操作。看看底部的紅色區域。
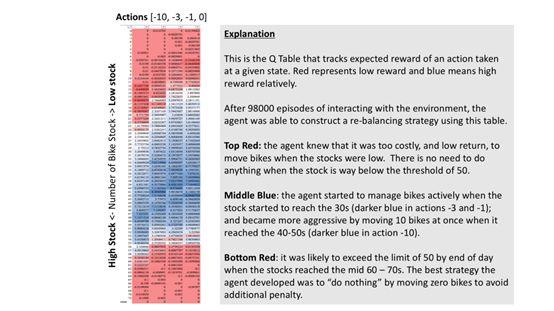
作者分析
RL能有多智能?以下圖表介紹了RL對停放處的管理情況。通過深入學習,RL可以將整體成功率逐步提高到98%,令人印象深刻。
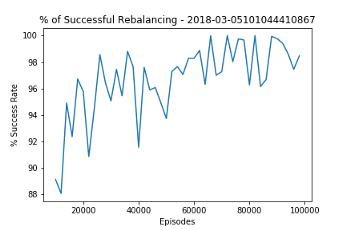
作者分析
希望大家喜歡這篇文章,并由衷地期待RL在現實世界中展示出的潛力。
















