基于RGB視頻數據的深度行為分類模型發展綜述之二
摘 要
理解視頻中的人體行為在視頻監控、自動駕駛以及安全保障等領域有著廣泛的應用前景。目前視頻中的人體行為分類研究是對分割好的視頻片段進行單人的行為分類。對視頻中的人體行為分類研究已經從最初的幾種簡單人體動作到幾乎包含所有日常生活的幾百類行為。上篇官微文章詳細介紹了基于RGB視頻數據的兩種深度行為分類模型,本文將介紹第三種深度行為分類模型——基于3D卷積神經網絡的,并對三種模型進行分析和對比。
基于 3D卷積網絡深度行為分類模型
視頻特征學習的難點在于時序特征的學習。表現良好的雙流架構在基于2D CNN挖掘空間信息的同時,不斷探索時序上運動特征的表達方式。這里的運動特征指的是視頻幀外觀的改變。視頻本身就是一個3D體,用3D卷積的方式獲取視頻中的空時特征顯然是更直觀的,3D卷積網絡(3D ConvNets)比2D卷積網絡更適用于時空特征的學習。3D卷積與2D卷積的區別如圖1所示,圖中(a)(b)是2D卷積核分別應用于單幀圖像和多幀圖像(或者是單通道圖像,多通道圖像),輸出2D特征圖,(c)是3D卷積核應用于3D視頻體,輸出的3D特征圖保留了時間維度的信息。

圖 1 2D與3D卷積示意圖
Baccouche等人[1]和Ji等人[2]首先提出了3D卷積網絡,使用3D卷積核同時處理空間和時間維度,然而該3D卷積模型淺層且參數量巨大,十分臃腫。Karpathy [3]等人在研究如何使用2D CNN來融合時間信息時,發現在單個視頻幀上運算的網絡與處理整個視頻空時體的網絡表現差異很小,因此認為時間維度上的建模對于行為識別的精度并不重要。Facebook在2015年提出C3D[4],該模型實現了與2014年雙流法接近的視頻行為分類的精度。它使用3D卷積和3D池化以及全連接層構成了11層的淺層網絡(如圖2),其最大的優勢在于速度,然而C3D的模型大小卻達到321MB,甚至大于152層ResNet[5]的235MB模型。這樣的模型訓練起來是困難的,且無法在像ImageNet這樣大規模圖片數據集上預訓練,淺層的網絡也限制了模型的分類性能。2017年,Facebook實驗室的Du Tran[6]等人又在殘差網絡框架下重新實現了C3D,使得推理速度快了兩倍的同時模型參數也少了兩倍。

圖 2 C3D模型示意圖
為了進一步提高3D CNN模型的泛化能力,P3D[7]將三維卷積核分解為二維空間卷積和一維時間卷積((2+1)D卷積)(如圖3)。
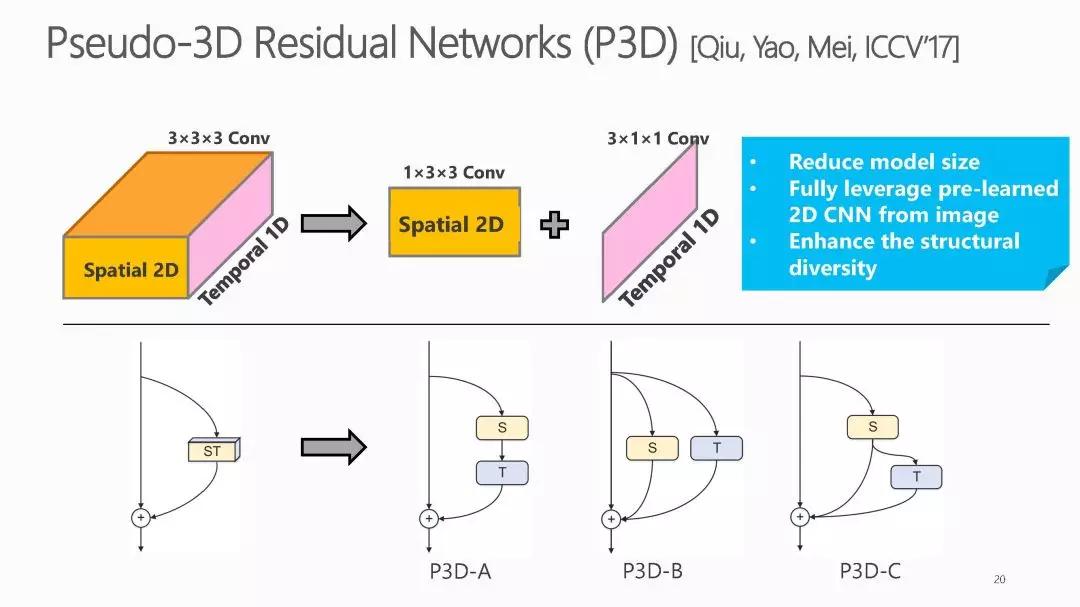
圖 3 3D卷積分解成(2+1)D卷積
Pseudo-3D(P3D)[7]在殘差學習[5]的框架下,將2維的殘差單元中的卷積核全部擴充成3維的卷積核,并將3*3*3的卷積核分解為一個1*3*3的二維空間卷積和3*1*1的一維時域卷積。P3D模型加深了模型深度的同時,提高了視頻人體行為分類的精度,并且相比于原始的C3D降低了模型大小。I3D[8]是基于ImageNet預訓練的Inception-V1骨干網絡,將網絡中的2D卷積核和池化核都擴展為3D的,同時結合雙流網絡處理連續多幀的 RGB圖像和光流圖像。使用大型視頻數據集Kinetics預訓練后,I3D模型在更小的UCF 101數據集上展現了優越的性能,成為了后續研究工作重點比較的模型。2018年Facebook和谷歌deepmina團隊又分別在P3D和I3D的基礎上,進一步探究3D空時卷積在行為識別中的作用,相繼提出了R(2+1)D [9] 和S3D [10]。兩個網絡都采用了將3D卷積核分解為2D卷積核加1D卷積核的形式(如圖3),證明了從長期時序上學習視頻的時間動態特征的必要性。R(2+1)D模型相比3D網絡,在不增加模型參數量的情況下,具有更強的表達能力且更易優化,尤其是在網絡層數加深時。S3D模型在準確率、模型容量、還有計算效率上都實現了比原始的I3D更好的性能,在S3D模型基礎上S3D-G增加了上下文特征門控機制,進一步提高了行為分類的精度。視頻的行為分類任務應用2D可分離卷積大大提升了精度與計算能力,受此啟發,facebook在2019年最新的一個研究工作CSN[11],考慮了卷積運算中通道交互的因素,將一個3D卷積核分為的傳統卷積,用于通道交互;的深度卷積用于局部空時交互。CSN在顯著減少模型參數量的同時又提升了精度,其中的通道分離對模型有正則化的作用,避免了過度擬合。本文在UCF101數據集和kinetics數據集上對上述3D網絡模型的參數量,計算效率,以及分類精度做了對比。(如表1所示)。
表 1 在UCF101和kinetics數據集上比較3D卷積模型

UCF 101數據集雖然是流行的視頻行為分類標準,但研究者們都有的共識是其有限的視頻數據量無法支持從頭開始訓練較深的CNN網絡。上述3D CNN研究工作都關注對3D卷積核的分解,主要動機之一是將3D卷積核分解為2D卷積核和1D卷積核之后,其中的2D卷積核可以使用圖像數據進行預訓練,對于已標注視頻數據的需求也會大大減少。Kinetics大規模視頻數據集的出現給3D CNN的發展提供了新的前景。Hara等人[12]應用Kinetics數據集訓練了基于殘差網絡及其擴展版本的不同深度的3D CNN網絡,發現Kinetics的數據量已經足夠支持訓練152層的深度Resnet 3D網絡,并且這樣訓練出來的簡單的3D CNN結構的分類精度已經可以和I3D相比。Wang等人[13]則是在I3D三維網絡的基礎上,使用ResNet-101骨干網絡,通過加入非局部模塊來獲得視頻中更長距離的空時依賴關系,這樣使得模型NL-I3D在僅輸入RGB視頻幀的情況下,行為分類的性能已經十分優越。
先進方法的比較分析
基于雙流架構,RNN網絡以及3D網絡的深度行為分類模型示意圖如圖4所示。
a)Two-Stream b)LSTM c)3D ConvNet
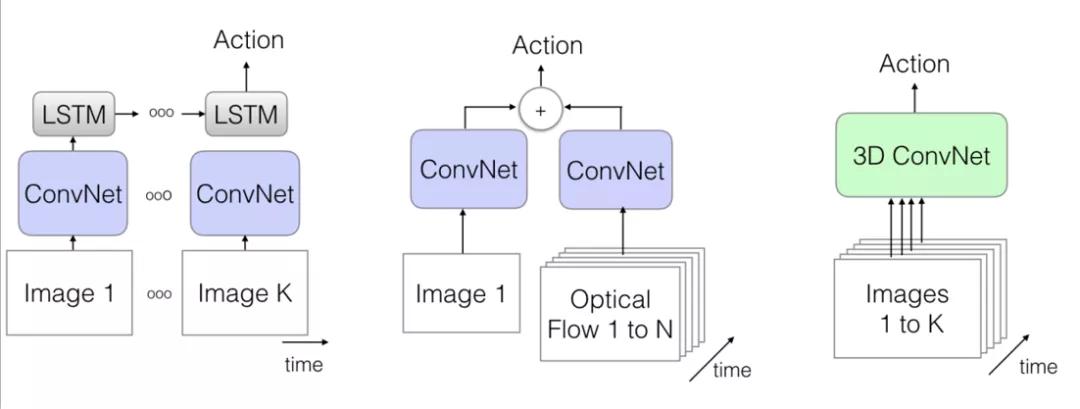
圖 4 基于RGB視頻數據的三種深度行為分類模型示意圖
為了進一步提升模型的性能,研究者們在各個方面不斷努力,包括使用多種輸入數據形式(RGB圖像,RGB差,光流圖像,扭曲光流,運動矢量等等),探究時序上的融合方法,將2D卷積核擴展為3D卷積核,提取關鍵視頻幀,增加注意力機制等等。概括來講,對于這三種深度行為分類模型的研究,重點在于如何更有效地挖掘更具有判別力的空域外觀信息和更長期的時序運動信息。三種深度行為分類模型在UCF 101和Kinetics數據集上的性能如表2所示。
表 2 深度行為分類模型在UCF 101和Kinetics數據集上的性能對比 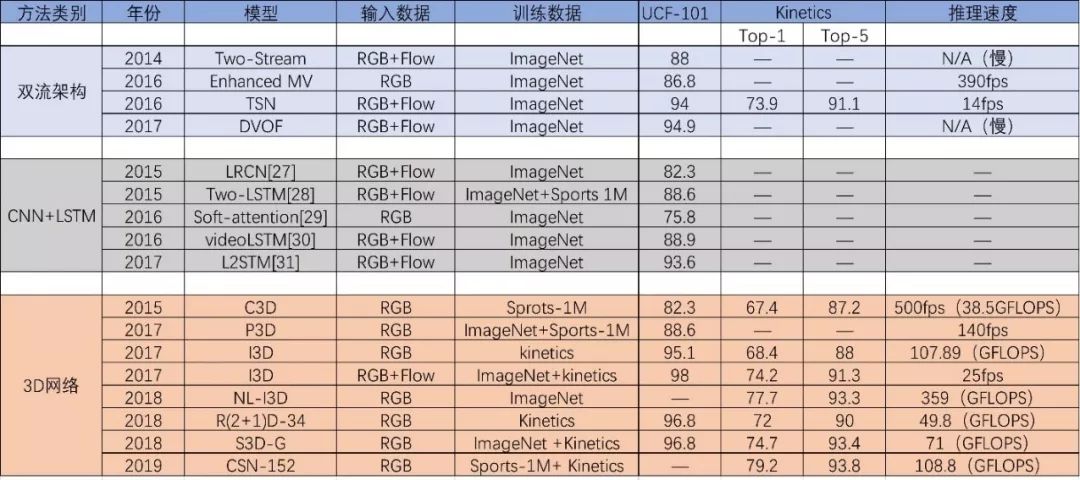
在表2數據中,基于RNN的行為分類模型的推理速度沒有具體體現,但是從模型復雜度來看,其推理速度與雙流法和3D網絡相比沒有任何優勢,同時分類精度也有一定差距。這是因為基于RNN網絡的分類模型雖然能進行更長期的時序建模,但其聚合空間信息以及表示時序上運動的能力都很有限。在2017年之前,雙流架構良好的性能表現使得研究者們對雙流架構的關注度非常高,相比之下3D網絡的發展則十分緩慢。但是2017年之后,3D網絡的關注度明顯提高,原因可以歸結于三點:(1)可以利用現有的數據訓練深度3D網絡。P3D,I3D等2D CNN擴展的3D網絡可以使用大規模的圖片數據集Imagenet進行預訓練,并且大型視頻數據集kinetics的提出使直接訓練更深的3D網絡成為可能。(2)光流無法很好地建模時序上的動態變化,并且計算量很大。2017年Facebook實驗室探究了光流在行為分類中的作用,發現光流實際上無法提供與外觀互補的運動信息,它能有效提高行為分類的精度是因為光流對圖像外觀的不變性。(3)視頻本身是空時體,用3D網絡進行空時建模更為直觀。
應用于視頻中行為分類的深度模型追隨著圖像任務上深度學習模型的發展步伐,從最初的11層的淺層3D網絡C3D到在ResNet深度殘差框架下擴展的3D網絡Res-C3D,以及在ResNet-152層上實現的199層的P3D和152層的CSN,研究模型的深度越來越深,這極大地歸功于可訓練公開視頻數據量的增加。在對3D空時建模不斷地探索中,研究者們都試圖在進一步提高行為分類精度的同時減少模型的參數和加快運算速度。這些研究都證明了3D空時卷積應用于視頻上比2D卷積更具優勢。因為視頻本身是空時三維體,時間維度的信息對理解視頻來說是必不可少的。
到目前為止,基于RGB視頻數據的深度行為分類模型的研究取得了不錯的分類效果,在目前最大規模的視頻數據集Kinetics上分類精度達到了93.8%。然而,上述深度行為分類模型的研究都是基于對分割好的視頻片段進行單人行為的分類。我們必須清醒的認識到,在真實的場景中,理解視頻中的人體行為仍具有很大的挑戰。
1、真實的視頻場景中復雜的背景,光照變化、人體外貌變化、攝像機視角以及運動速度等不確定因素,都會影響深度行為分類模型的性能。
2、真實視頻流中包含了大量長時間的非動作冗余視頻段。在對人體行為分類的基礎上,進一步提取明確人體行為的時間邊界,則是視頻時序行為檢測任務。該任務也有研究者不斷在當前深度行為分類模型的基礎上嘗試解決,但效果和速度都低于當前的應用要求。
3、基于RGB視頻的深度行為分類模型能夠從視頻圖像幀中獲得細致的外觀紋理特征,但是很難在空間和時間上對不同的人體運動建模。因此很難適用于多人的場景中。