基于RGB視頻數據的深度行為分類模型發展綜述之一
摘要:
理解視頻中的人體行為在視頻監控、自動駕駛以及安全保障等領域有著廣泛的應用前景。目前視頻中的人體行為分類研究是對分割好的視頻片段進行單人的行為分類。對視頻中的人體行為分類研究已經從最初的幾種簡單人體動作到幾乎包含所有日常生活的幾百類行為。近些年來基于RGB視頻數據的先進深度行為分類模型可以分為三類:基于雙流架構的、基于循環神經網絡RNN的和基于3D卷積神經網絡的。本文將詳細介紹前兩種深度行為分類模型。
一、視頻行為分類
當前人體行為識別的研究主要分為兩個子任務:行為分類和時序行為檢測。行為分類一般是對分割好的視頻片段進行行為分類,每一個視頻片段僅包含一個行為實例。然而,現實生活中大部分視頻都是未分割的長視頻,因此時序行為檢測任務從未分割的長視頻中檢測出行為的開始、結束時間以及行為類別,一段長視頻中一般包含一個或多個行為實例。行為分類是時序行為檢測的基礎,時序行為檢測是比行為分類更復雜的研究任務,行為分類的經典模型(如TSN,C3D,I3D等)也被廣泛用于時序行為檢測任務當中。現在視頻中人體行為識別的研究工作大部分都致力于提高行為分類模型的性能,并且研究最廣泛的是對單人行為的識別。
二、評估數據集
對于數據驅動的深度學習方法來說,龐大的視頻數據量顯然能夠提升模型的性能。本文選用了最新且規模更大視頻數據集kinetics,來分別比較最新的基于RGB視頻輸入數據的行為分類模型的性能,同時也使用典型的視頻數據集UCF101, 幫助分析和比較經典的深度行為分類模型。UCF 101和Kinetics數據集的評估度量標準都是是平均精度均值(mAP)。在對視頻中的行為進行分類時,每一個視頻片段都會預測一個行為標簽。假設有C個行為類別,每個視頻片段都對應一個有C個元素的列表,每個元素代表著該視頻屬于行為c的概率,并將C個類別標簽按照概率值從高到底排序。假設一共有n個視頻片段,并取一個視頻片段的預測得分列表中的前k個值,P(k)分別是類別標簽排名在前k的預測概率值,rel(k)是指示函數,表明第k個標簽是否是真陽性(true positive),如果是則為1,否則為0。因此,某個行為類別的平均精度(AP)的計算方式是
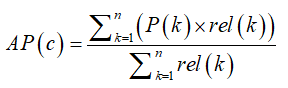
平均精度均值(mAP)是所有類別的平均精度求和后再取均值。
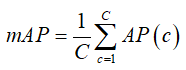
UCF 101數據集一般只取預測概率最高的標簽作為預測標簽(k=1,top-1)。而Kinetics數據集中,細粒度的行為類別劃分導致一個視頻片段可能包含多種動作。例如,開車”時“發短信”,“彈奏尤克里里”時“跳草裙舞”,“跳舞”時“刷牙”等等。所以在Kinetics數據集上進行評估時,通常選擇得分最高的前5個標簽作為預測的行為類別標簽(k=5,top-5)。本文在比較模型的推理速度時,選用了兩個評價指標。一個是每秒幀率(FPS) ,即每秒模型可以處理的視頻幀的數量。另一個是每秒浮點運算次數(GFLOPS)。本文中顯示的GFLOPs指標均采用32幀的視頻片段作為模型的輸入數據。
三、深度行為分類模型
在視頻人體行為分類的研究中,關鍵且具有挑戰性的一個問題是如何從視頻的時序維度上獲得人體的運動信息。基于RGB視頻的深度學習方法根據時序建模方式的不同可以分為基于雙流架構的,基于循環神經網絡(RNN)的和基于3D卷積神經網絡的。早期將深度學習方法擴展應用于RGB視頻中的一個經典嘗試是,擴展2D卷積神經網絡形成雙流架構,分別來獲得視頻幀的空間特征以及幀間的運動特征。隨后有研究將循環神經網絡(RNN)與卷積神經網絡(CNN)結合,試圖學習更全局的視頻時序信息。考慮到視頻本身是多了時間維度的3D體,3D網絡則直觀地使用3D卷積核來獲得視頻的空時特征。這些基于RGB視頻的行為分類方法主要關注兩點:(1)如何在視頻中提取出更具有判別力的外觀特征;(2)如何獲得時序上視頻幀外觀的改變。在介紹這類深度學習的方法之前,不得不首先提一下經典的手工提取特征的方法iDT(improved Dense Trajectories)[1],是深度學習應用到視頻領域之前性能最好的方法,它通過光流追蹤圖像像素點在時間上的運動軌跡。該方法有個很大的缺點是獲得的特征維度甚至比原視頻還要高,計算速度非常慢。早期的深度學習的方法在和iDT結合之后都能取得一定的效果提升。發展到現在,深度學習方法在視頻行為分類上的性能已較iDT有大幅提升。1、雙流架構2014年Karpathy [2]等人采用兩個獨立流分別獲取低分辨率幀和高分辨率的特征,在時間上采用慢融合的方式擴展了所有卷積層在時間上的連通性,這是將CNN擴展到視頻行為分類的運用,但其性能與傳統方法iDT還有一定的差距。Simonyan首次提出基于光流的雙流(two-stream)架構,分別使用視頻幀和幀間的光流圖像作為CNN的輸入。該方法可以說是CNN擴展到視頻行為分類的首次非常成功的嘗試,在UCF101上的精度達到了88%,優于手工特征提取的方法iDT。結合光流輸入的雙流架構的良好表現激發了后續對許多基于雙流架構的改進。雙流融合法(Two-stream Fusion) [3]在雙流架構的基礎上,使用VGG-net深度模型作為骨干網絡,并提出在最后一個卷積層后融合特征比在全連接層之后融合特征的效果要好。考慮到這兩種雙流方法無法對長期時序結構建模,時序上一次僅能處理連續10幀的堆疊光流場,空域則僅處理單幀圖像。時序分割網絡(TSN) [4]則直接對整段視頻建模,在時序上將整個視頻分段(segment),最后融合不同片段的類別得分,來獲得長期的時序特征,融合后的預測結果是視頻級的預測,在UCF 101數據集上的精度達到了94.2%。TSN的模型如圖1所示。
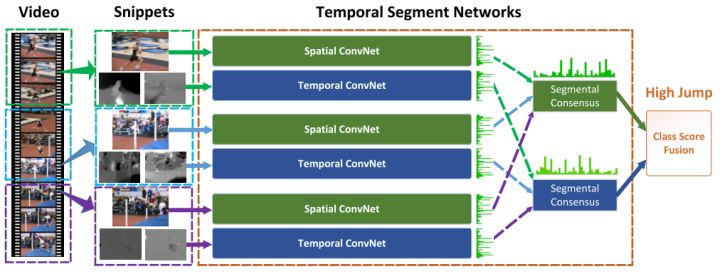
圖 1 時序分割網絡(TSN)模型架構
TSN在UCF 101數據集上的性能表現已經非常優越。Lan等人[5]提出深度局部特征(DVOF),在TSN模型的基礎上利用深度網絡提取局部特征,將聚合局部特征形成的全局特征輸入到淺層網絡進行分類,來糾正局部特征學習到的錯誤的行為標簽信息。時序關系推理(TRN)[6]是2017年MIT周博磊大神基于TSN改進的一個很具有啟發性的研究工作。TRN在時間維度上能夠提取不同尺度的視頻特征,然后使用多層感知機(MLP)融合不同時間尺度的幀間關系,用于學習和推理視頻幀之間的時間依賴關系。該方法在UCF101上的性能提高并不明顯,這是因為UCF101中的視頻數據表示的動作在空間上的上下文關聯更強,但是論文在時序上下文相關性更強的Something-Something[]視頻數據集上驗證了TRN發現視頻中時序關系的能力。基于光流的雙流架構展現了優越的性能,然而光流的計算需要消耗很大的計算資源。也有方法嘗試能夠代替光流表示運動信息的方法,Zhang等人[7]提出計算運動矢量(motion vector)來代替光流作為CNN的輸入,推理速度能達到每秒390.7幀,作者將光流CNN中學習的特征和知識遷移到運動矢量CNN中期望能彌補運動矢量在細粒度和噪聲上的不足,但是最終模型在精度上還有很大的犧牲。上述雙流方法在UCF101數據集上的性能如表1。
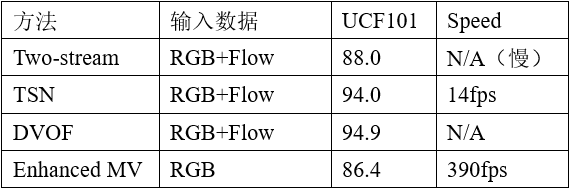
表 1 雙流架構在UCF101數據集上的性能對比
2、RNN網絡CNN是典型的前饋神經網絡,上述基于CNN網絡的模型一次僅能處理有限的視頻幀,如典型的TSN處理一次處理10個視頻幀并通過時序聚合方式獲得更長期的視頻級的預測,C3D則一次處理16幀,I3D則是一次處理64幀圖片。然而在實際生活中,很多常見的人類行為比如握手,飲酒,打電話,或步行、游泳等重復動作的行為通常持續數十秒跨越數百個視頻幀。循環神經網絡(RNN)的循環結構,能夠將先前的信息連接到當前任務,允許信息長期存在,因此可以很好地對序列結構建模。然而早期的 RNN網絡不能對長期的依賴關系進行建模,也不能在很長一段時間內存儲關于過去輸入的信息。理論上講一個足夠大的RNN應該能夠建模任意復雜度的序列,然而在訓練RNN時會出現梯度消失和梯度爆炸問題。RNN網絡的變體,長短期記憶網絡(LSTM)則解決了這個問題。LRCN[8]將LSTM用于在時間序列上對2D卷積網絡提取的幀特征建模,發現這樣的網絡結構顯著提高了那些動作持續時間長和動作的靜態外觀易混淆的行為分類精度。Ng[9]等人比較了特征池化和LSTM兩種時序聚合方式,將CNN輸出的幀級特征聚合成視頻級,說明在整合視頻序列中長期的信息可以實現更好的視頻分類,論文中也通過雙流架構分別使用RGB和光流圖像作為輸入。Sharma 等人[10]開創性地在基于LSTM的網絡中引入了注意力機制,提出了soft-attention LSTM,該模型讓網絡能夠關注視頻幀中與行為類別相關的區域。VideoLSTM[11]則是在soft-attention LSTM的基礎上堆疊了一個RNN用于運動建模并且裝配了增強版的注意力模型,然而復雜的模型結構并沒有明顯地提高性能。上述模型都是采用了CNN+LSTM的形式,使用CNN提取視頻幀特征,并用LSTM直接聚合多個視頻幀來獲得視頻時序上的依賴關系。然而,通過這樣的方式學習到的運動隱含地假設了視頻中的運動在不同的空間位置上是靜止的。Sun[12]等人提出了Lattice LSTM(L2STM),通過學習記憶單元在不同空間位置的獨立隱藏狀態轉換來擴展LSTM,有效地增強了時間上動態建模能力。上述基于RNN網絡的視頻中人體行為分類方法在UCF 101數據集上的精度如表2所示。
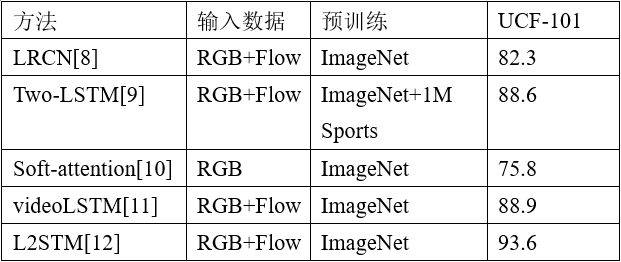
表 2 在UCF101數據集上比較RNN行為分類模型