Python爬取電子課本,送給居家上課的孩子們
在這個全民抗疫的日子,中小學生們也開啟了居家上網(wǎng)課的生活。很多沒借到書的孩子,不得不在網(wǎng)上看電子課本,有的電子課本是老師發(fā)的網(wǎng)絡鏈接,每次打開網(wǎng)頁去看,既費流量,也不方便。今天我們就利用python的爬蟲功能,把網(wǎng)絡鏈接的課本爬下來,再做成PDF格式的本地文件,讓孩子們隨時都能看。本文案例爬取的網(wǎng)絡課本見下圖:
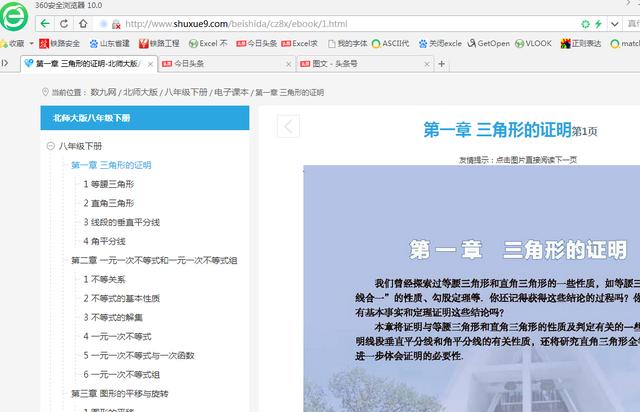
圖1 電子課本首頁
實現(xiàn)思路為兩部分:
- 用python從網(wǎng)站爬取全部課本圖片;
- 將圖片合并生成PDF格式文件。
具體過程:
一、爬取課本圖片
爬蟲4流程:發(fā)出請求——獲得網(wǎng)頁——解析內(nèi)容——保存內(nèi)容。
根據(jù)上篇python批量爬取網(wǎng)絡圖片里講過的知識,網(wǎng)頁里的圖片有單獨的網(wǎng)址,爬取圖片時需要先爬取出圖片網(wǎng)址,再根據(jù)圖片網(wǎng)址爬取圖片。
1、發(fā)出請求:
首先找出合適的網(wǎng)址URL,因是靜態(tài)網(wǎng)頁網(wǎng)址,我們可直接用瀏覽器地址欄的網(wǎng)址,下圖2中紅框位置即為要用的網(wǎng)址,復制下來就行。
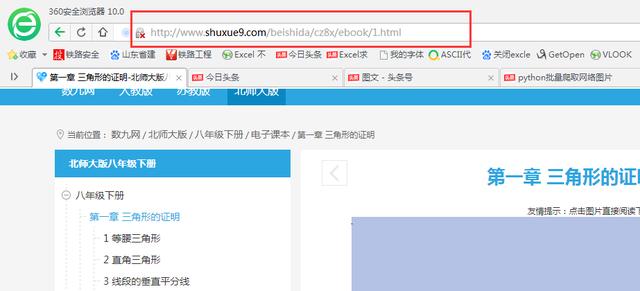
圖2 瀏覽器地址欄網(wǎng)址可用于發(fā)出請求
網(wǎng)頁網(wǎng)址為:http://www.shuxue9.com/beishida/cz8x/ebook/1.html
2、發(fā)出請求獲得響應:
- url = http://www.shuxue9.com/beishida/cz8x/ebook/1.htmlresponse = requests.get(url)
3、解析響應獲得網(wǎng)頁內(nèi)容:
- soup = BeautifulSoup(response.content, 'lxml')
4、解析網(wǎng)頁內(nèi)容,獲得圖片網(wǎng)址:
- jgp_url = soup.find('div', class_="center").find('a').find('img')['src']
5、向圖片網(wǎng)址發(fā)出訪問請求,并獲得圖片(因為該網(wǎng)址僅有圖片,不需用find解析):
- jpg = requests.get(jgp_url).content
6、保存圖片:
- f = open(set_path() + number + '.jpg','wb')f.write(jpg)
其中,set_path()是提前建好的用于存放圖片的路徑,代碼見下,也可直接寫上想用的路徑:
- def set_path(): path = r'e:/python/book' if not
- os.path.isdir(path): os.makedirs(path) paths = path+'/'
- return(paths)
7、存在問題:
以上就完成了課本圖片的爬取,我們打開文件夾,發(fā)現(xiàn)只有一張圖片被下載了,后面的都沒。這是因為瀏覽網(wǎng)頁時,每個頁面都有不同的網(wǎng)址,我們試著分析一下,發(fā)現(xiàn)電子課本的每一頁網(wǎng)址很有規(guī)律:
- 第1頁網(wǎng)址:http://www.shuxue9.com/beishida/cz8x/ebook/1.html
- 第2頁網(wǎng)址:http://www.shuxue9.com/beishida/cz8x/ebook/2.html
- ......
- 第n頁網(wǎng)址:http://www.shuxue9.com/beishida/cz8x/ebook/n.html
每頁上的圖片網(wǎng)址各不相同,沒規(guī)律。我們可以根據(jù)規(guī)律用循環(huán)方式,對網(wǎng)址發(fā)起訪問,獲得圖片后,自動循環(huán)訪問下一個網(wǎng)址......最終獲得全部圖片。
8、設置循環(huán)提取:
在以上全部過程納入到一個for循環(huán)里,根據(jù)網(wǎng)頁,我們可以看到共有152頁,設置循環(huán)后完整代碼為:
- import requests , osfrom bs4 import BeautifulSoupfor i in range(1,
- 153):# 發(fā)出請求 url = "http://www.shuxue9.com/beishida/cz8x/ebook
- /{}".format(i)+".html" response = requests.get(url)# 獲得網(wǎng)頁
- soup = BeautifulSoup(response.content, 'lxml')# 解析網(wǎng)頁得到圖片網(wǎng)址
- jgp_url = soup.find('div', class_="center").find('a').find('img')
- ['src']# 發(fā)出請求解析獲得圖片 jpg = requests.get(jgp_url).content#
- 設置圖片保存路徑 p = r'e:/python-book' if not os.path.isdir(p):
- os.makedirs(p)# 保存圖片 f = open(p + '/' + str(i) +
- '.jpg', 'wb') f.write(jpg)print("下載完成")
運行程序,即可一次下載全部課本圖片,效果為:
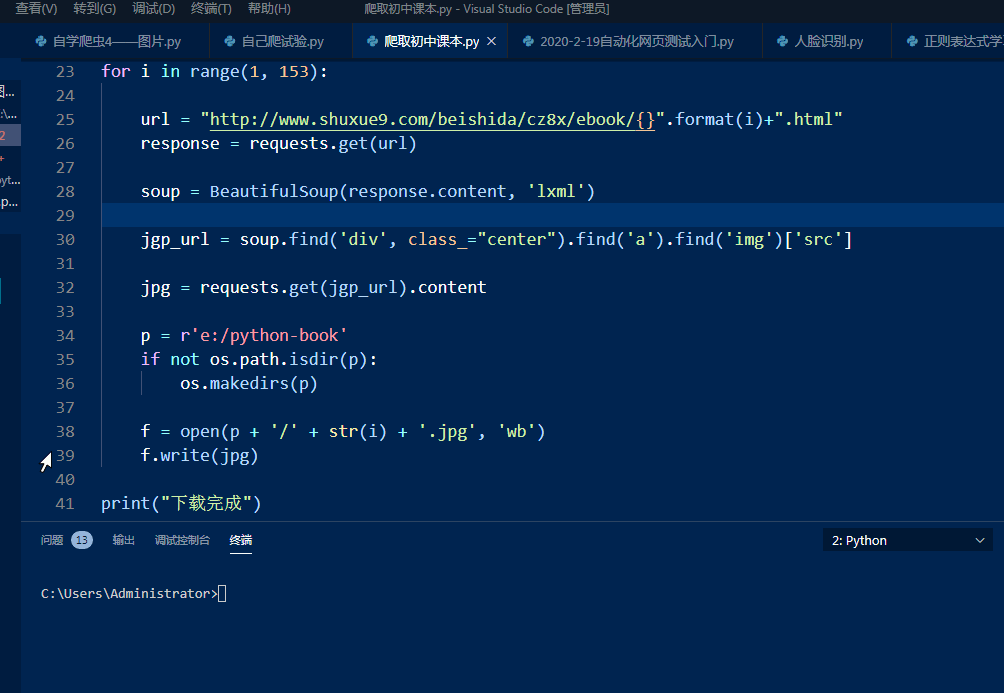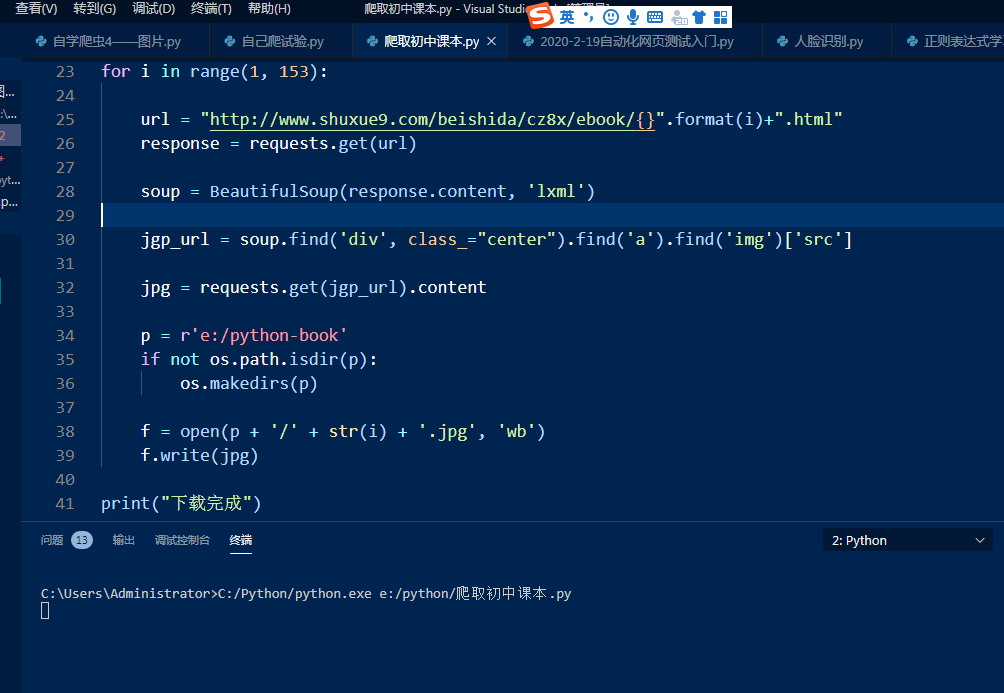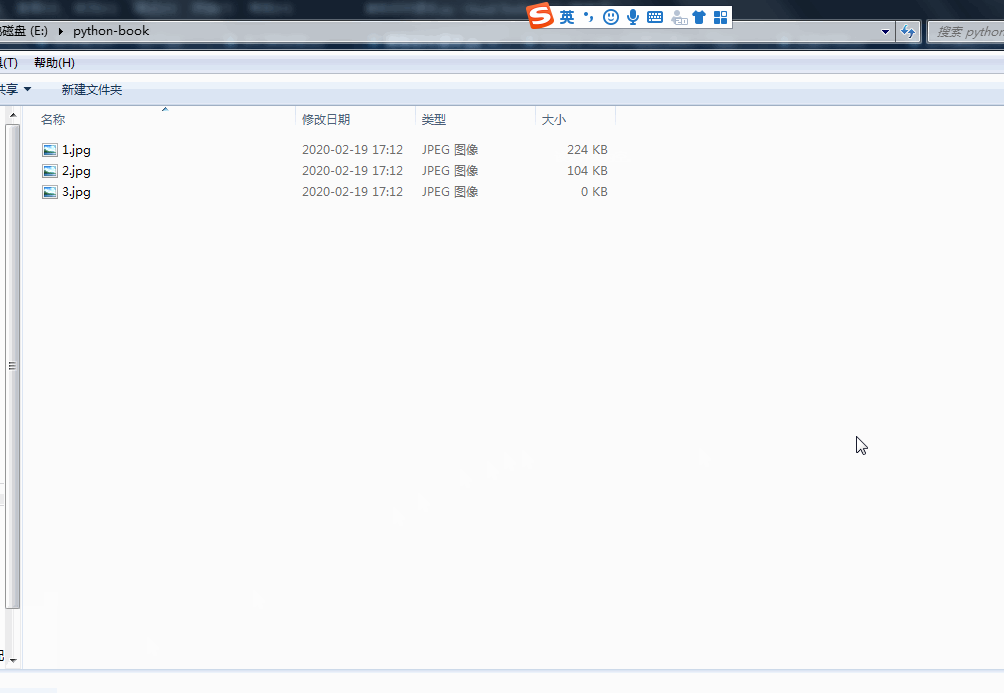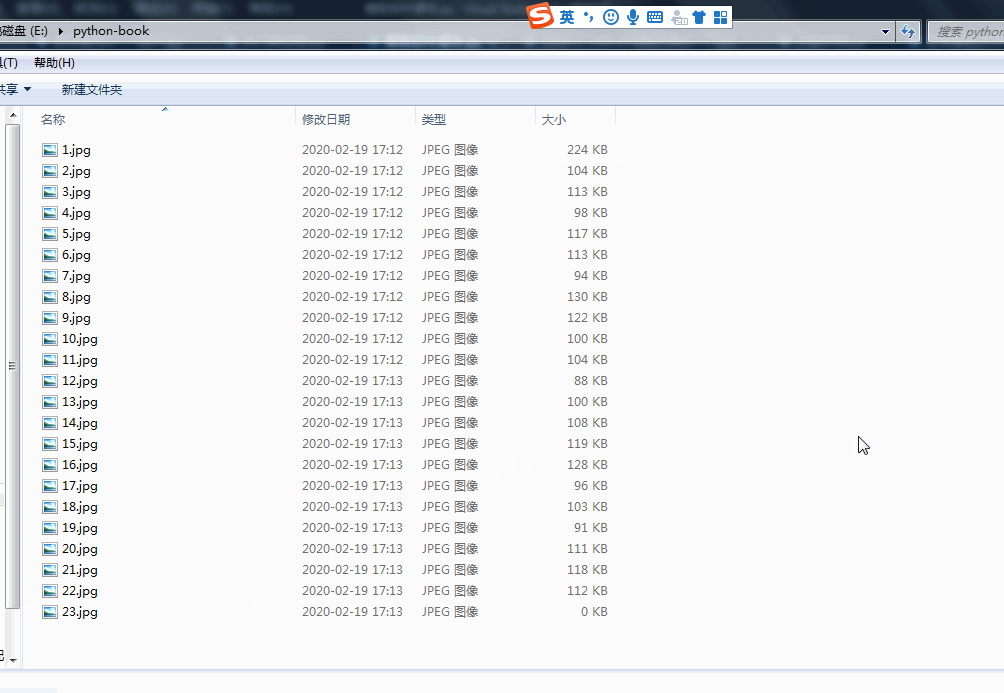
圖3 運行程序下載圖片
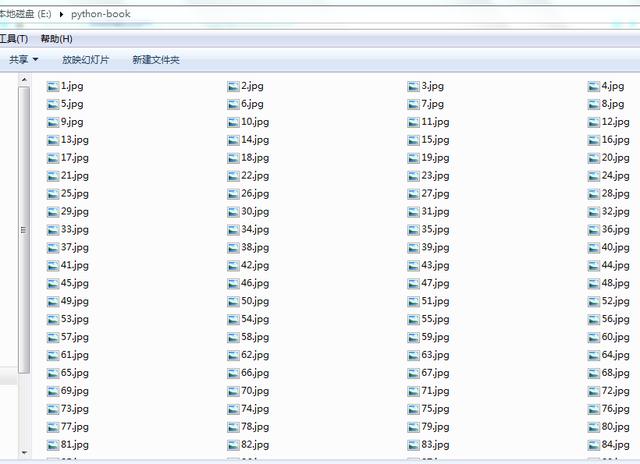
圖4 下載好的圖片
二、將圖片合并生成PDF格式文件
圖片下載完成后,將圖片生成PDF格式才方便使用。網(wǎng)上有專門的軟件,但免費的試用版只能合并幾張圖片。今天教大家一個免費且常用的OFFICE—ppt軟件來將多張圖片合并成一個PDF格式文件。
新建一個PowerPoint空白文件,點擊插入——相冊——新建相冊,
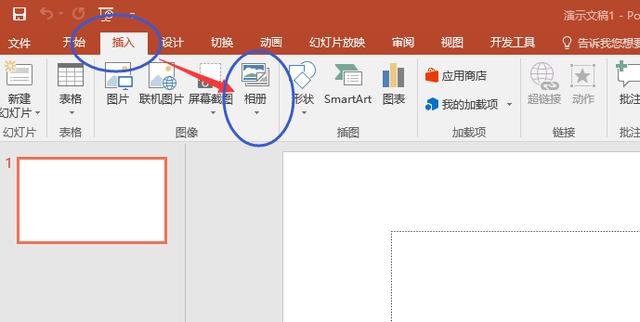
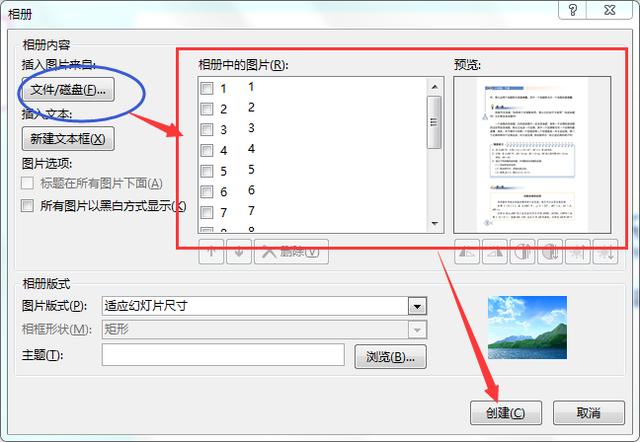
在彈出的窗體里,點擊左上角的“文件/磁盤”,將剛才下載的圖片全部導入進去,導入后的效果如下圖右側(cè)紅框樣式,然后點擊“創(chuàng)建”,保存文件時另存為PDF格式即可。
總結(jié):
至此,從網(wǎng)頁爬取電子課本圖片,生成PDF格式的本地文件就全部完成了。其中,如何找到并提取網(wǎng)頁中的圖片網(wǎng)址,在本頭條上一篇文章里已有詳述,有疑問的可查閱或留言交流。
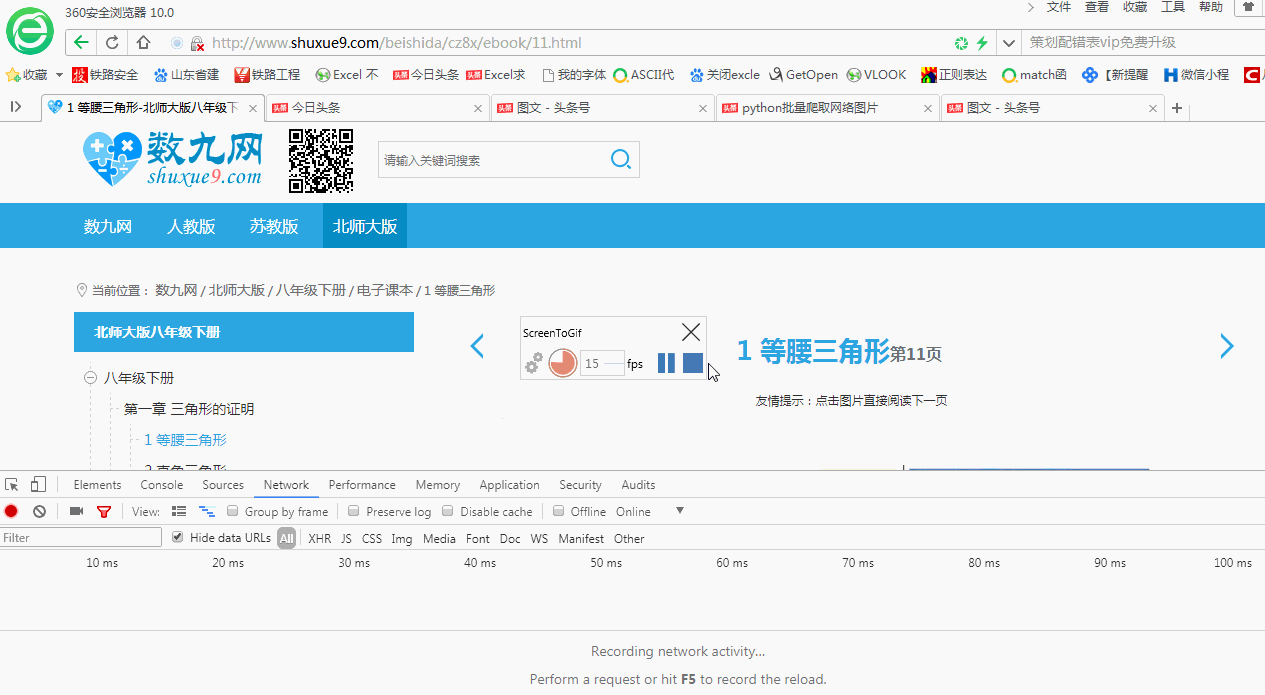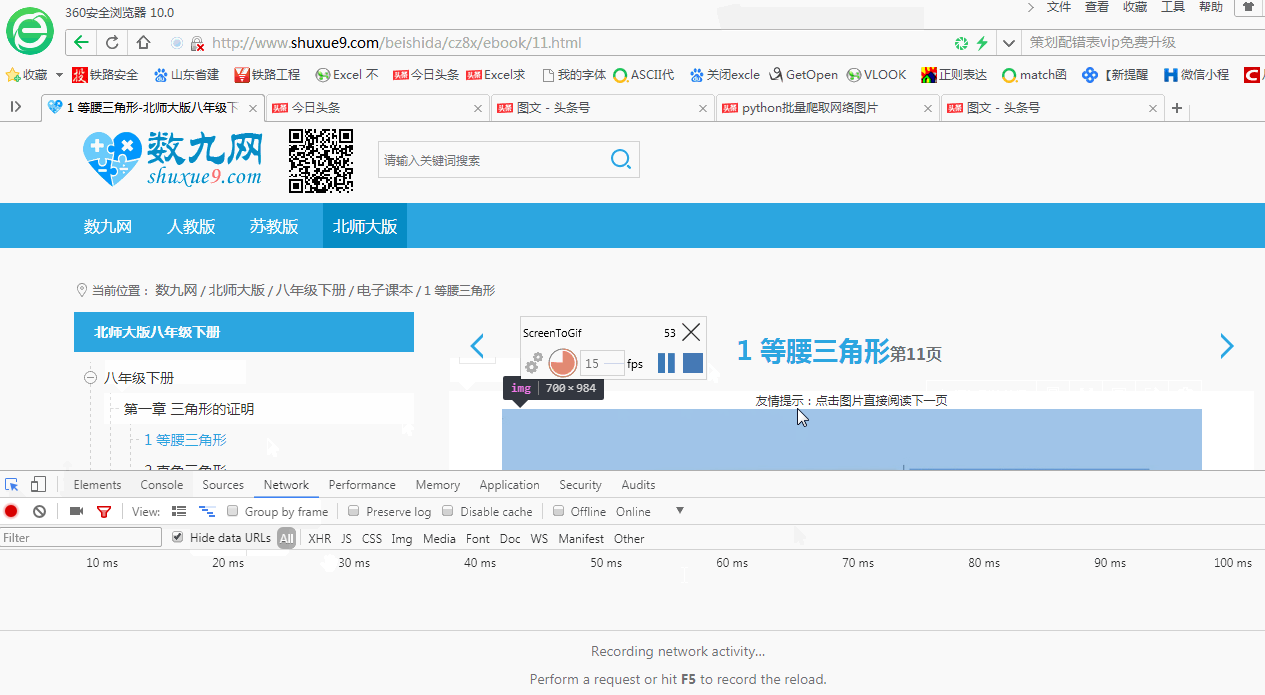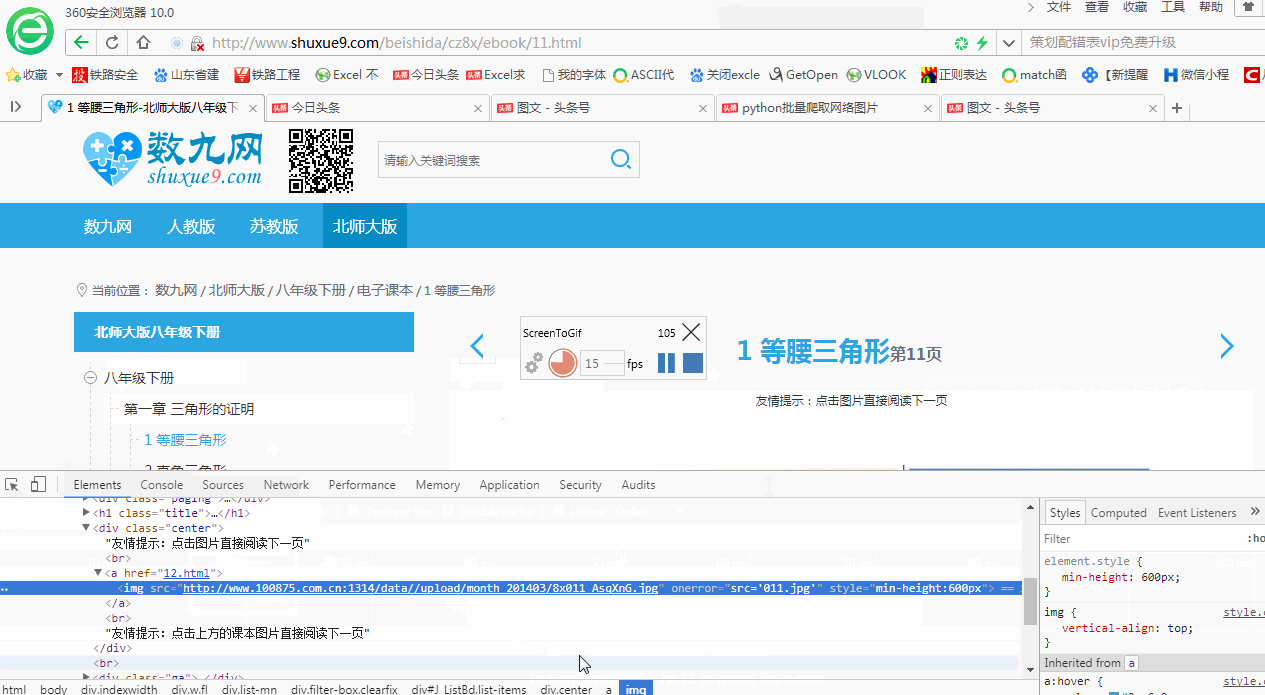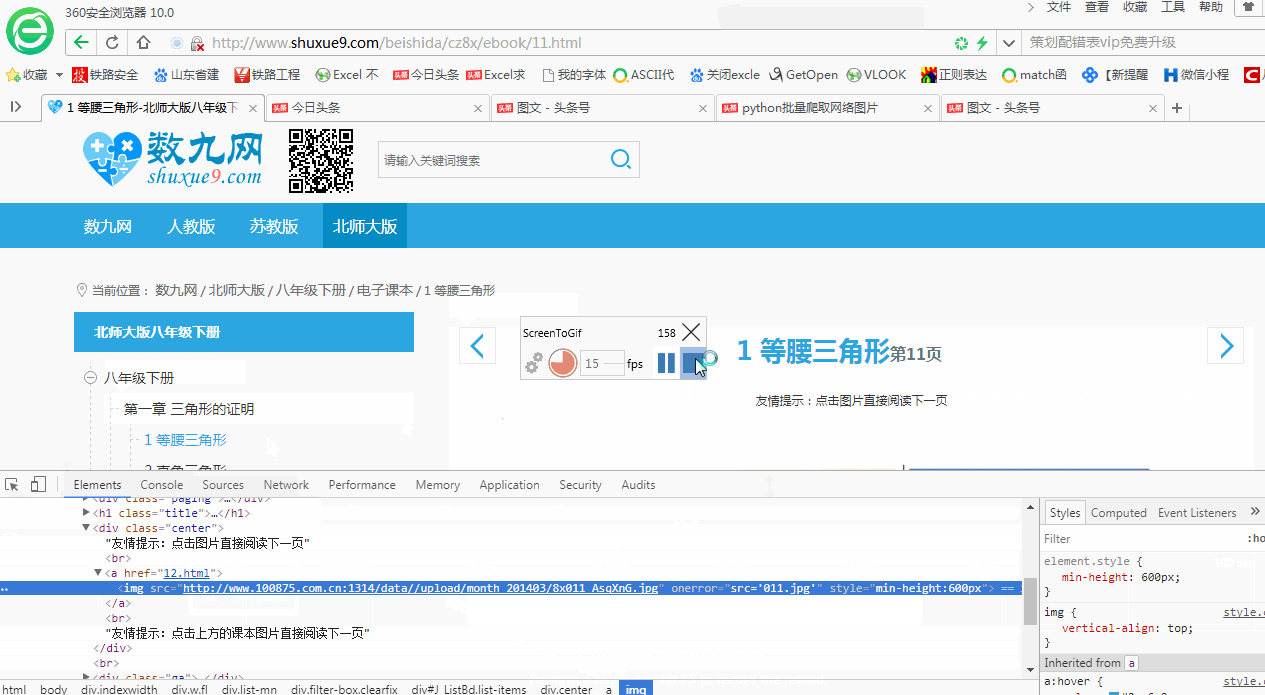
另分享一個從網(wǎng)頁內(nèi)容中找到圖片網(wǎng)址的簡便方法:在打開的開發(fā)者工具界面,點擊左上角的箭頭符號,然后在網(wǎng)頁上點擊想要查找網(wǎng)址的圖片,會自動高亮顯示圖片網(wǎng)址所在位置。如下所示: