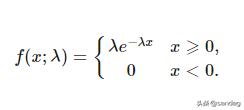數據科學中的常見的6種概率分布(Python實現)
介紹
擁有良好的統計背景對于數據科學家的日常工作可能會大有裨益。每次我們開始探索新的數據集時,我們首先需要進行探索性數據分析(EDA),以了解某些特征的概率分布是什么。如果我們能夠了解數據分布中是否存在特定模式,則可以量身定制最適合我們的機器學習模型。這樣,我們將能夠在更短的時間內獲得更好的結果(減少優化步驟)。實際上,某些機器學習模型被設計為在某些分布假設下效果最佳。因此,了解我們正在使用哪個概率分布可以幫助我們確定最適合使用哪些模型。
不同類型的數據
每次我們使用數據集時,我們的數據集都會代表總體的樣本。然后使用這個樣本,我們可以嘗試了解其概率分布,以便我們可以使用它對總體進行預測。
假設我們要根據一組數據來預測房屋的價格,我們可以找到一個包含舊金山所有房價的數據集(我們的樣本),進行一些統計分析之后,我們就可以對美國其他任何城市的房價做出相當準確的預測(我們的總體)。
數據集由兩種主要類型的數據組成:數值(例如整數,浮點數)和標簽(例如名字,電腦品牌)。
數值數據還可以分為其他兩類:離散和繼續。離散數據只能采用某些值(例如,學校中的學生人數),而連續數據可以采用任何實際或分數值(例如,身高和體重的概念)。
從離散隨機變量中,可以計算出概率質量函數,而從連續隨機變量中,可以得出概率密度函數。
概率質量函數給出了變量可以等于某個值的概率,概率密度函數的值本身并不是概率,需要在給定范圍內進行積分。
自然界中存在許多不同的概率分布,在本文中,我將向大家介紹數據科學中最常用的概率分布。
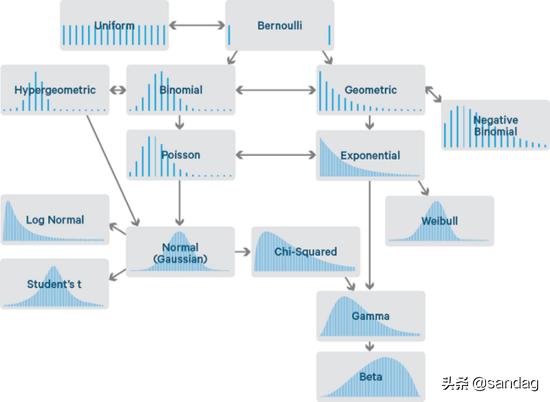
在本文中,我將提供有關如何創建每個不同概率分布的代碼。首先,讓我們導入所有必要的庫:
- import pandas as pd
- import numpy as np
- import matplotlib.pyplot as plt
- import scipy.stats as stats
- import seaborn as sns
伯努利分布
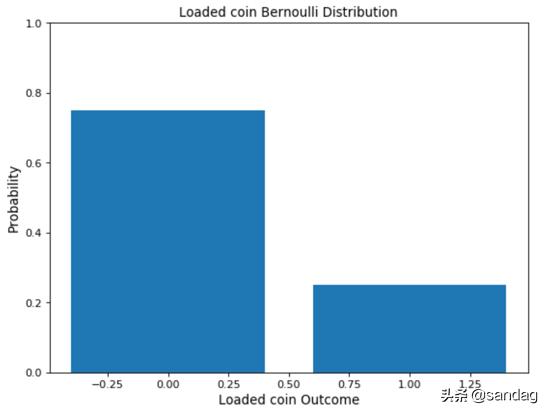
伯努利分布是最容易理解的分布之一,可用作導出更復雜分布的起點。這種分布只有兩個可能的結果,一個簡單的例子就是拋擲偏斜/無偏硬幣。在此示例中,可以認為結果可能是正面的概率等于p,而對于反面則是(1-p)(包含所有可能結果的互斥事件的概率總和為1)。
- probs = np.array([0.75, 0.25])
- face = [0, 1]
- plt.bar(face, probs)
- plt.title('Loaded coin Bernoulli Distribution', fontsize=12)
- plt.ylabel('Probability', fontsize=12)
- plt.xlabel('Loaded coin Outcome', fontsize=12)
- axes = plt.gca()
- axes.set_ylim([0,1])
均勻分布
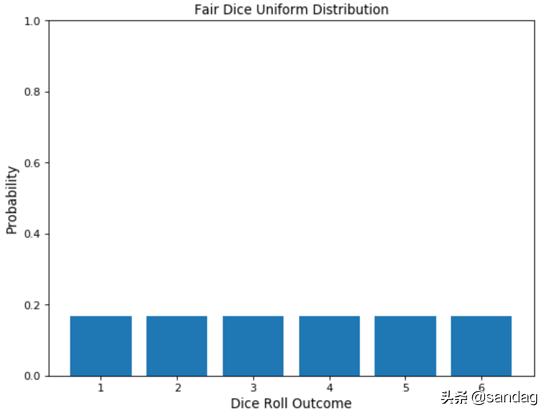
均勻分布可以很容易地從伯努利分布中得出。在這種情況下,結果的數量可能不受限制,并且所有事件的發生概率均相同。例如擲骰子,存在多個可能的事件,每個事件都有相同的發生概率。
- probs = np.full((6), 1/6)
- face = [1,2,3,4,5,6]
- plt.bar(face, probs)
- plt.ylabel('Probability', fontsize=12)
- plt.xlabel('Dice Roll Outcome', fontsize=12)
- plt.title('Fair Dice Uniform Distribution', fontsize=12)
- axes = plt.gca()
- axes.set_ylim([0,1])
二項分布
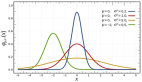
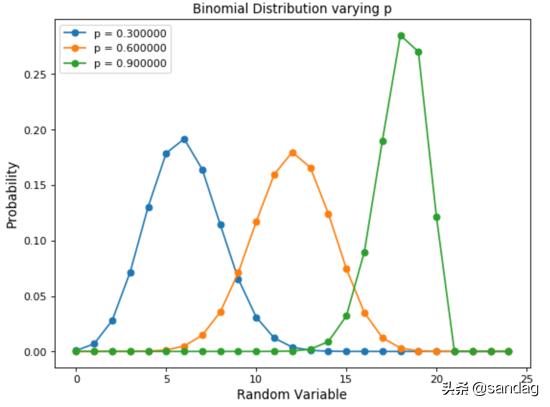
二項分布被認為是遵循伯努利分布的事件結果的總和。因此,二項分布用于二元結果事件,并且所有后續試驗中成功和失敗的概率均相同。此分布采用兩個參數作為輸入:事件發生的次數和試驗成功與否的概率。二項式分布最簡單的示例就是將有偏/無偏硬幣拋擲一定次數。
大家可以觀察一下不同概率情況下二項分布的圖形:
- # pmf(random_variable, number_of_trials, probability)
- for prob in range(3, 10, 3):
- x = np.arange(0, 25)
- binom = stats.binom.pmf(x, 20, 0.1*prob)
- plt.plot(x, binom, '-o', label="p = {:f}".format(0.1*prob))
- plt.xlabel('Random Variable', fontsize=12)
- plt.ylabel('Probability', fontsize=12)
- plt.title("Binomial Distribution varying p")
- plt.legend()
二項式分布的主要特征是:
- 給定多個試驗,每個試驗彼此獨立(一項試驗的結果不會影響另一項試驗)。
- 每個試驗只能得出兩個可能的結果(例如,獲勝或失敗),其概率分別為p和(1- p)。
如果獲得成功概率(p)和試驗次數(n),則可以使用以下公式計算這n次試驗中的成功概率(x)。
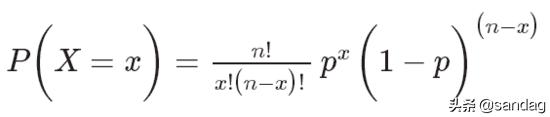
正態(高斯)分布
正態(高斯)分布是數據科學中最常用的分布之一。
我們日常生活中發生的許多常見現象都遵循正態分布,例如:經濟中的收入分布,學生的平均報告數量,平均身高等。此外,中心極限定理說明,在適當的條件下,大量相互獨立隨機變量的均值經適當標準化后依分布收斂于正態分布。
- n = np.arange(-50, 50)
- mean = 0
- normal = stats.norm.pdf(n, mean, 10)
- plt.plot(n, normal)
- plt.xlabel('Distribution', fontsize=12)
- plt.ylabel('Probability', fontsize=12)
- plt.title("Normal Distribution")
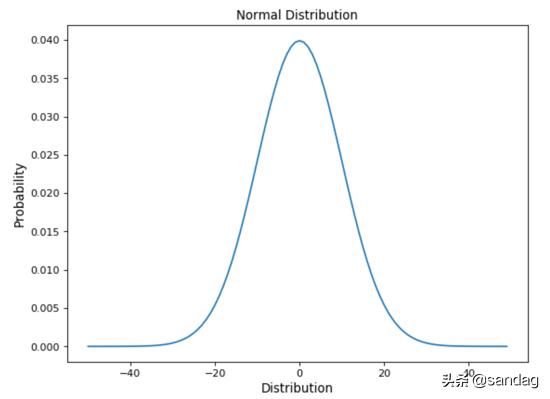
可以看出正態分布的特征:
- 曲線在中心對稱。 因此,均值,眾數和中位數都相等,從而使所有值圍繞均值對稱分布。
- 分布曲線下的面積等于1(所有概率之和必須等于1)
可以使用以下公式得出正態分布

使用正態分布時,均值和標準差起著非常重要的作用。如果我們知道它們的值,通過概率分布即可輕松找出預測精確值的概率。根據正態分布的特性,68%的數據位于均值的一個標準差范圍內,95%的數據位于均值的兩個標準差范圍內,99.7%的數據位于均值的三個標準差范圍內。
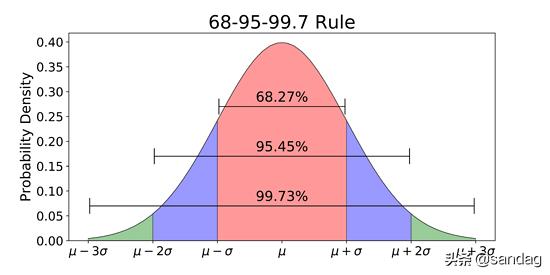
許多機器學習模型被設計為遵循正態分布有最佳效果。以下是一些示例:
- 高斯樸素貝葉斯分類器
- 線性判別分析
- 二次判別分析
- 基于最小二乘的回歸模型
在某些情況下可以通過對數和平方根等變換將非正態數據轉換為正態形式。
泊松分布
泊松分布通常用于查找事件可能發生或不發生的頻率,還可用于預測事件在給定時間段內可能發生多少次。
例如,保險公司經常使用泊松分布來進行風險分析(預測在預定時間段內發生的車禍事故數),以決定汽車保險的定價。
當使用泊松分布時,我們可以確信發生不同事件之間的平均時間,但是事件發生的確切時刻在時間上是隨機間隔的。
泊松分布可以使用以下公式建模,其中λ表示單位時間(或單位面積)內隨機事件的平均發生率。
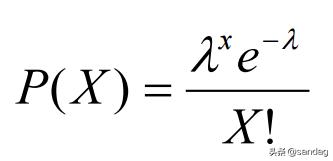
泊松分布的主要特征是:
- 事件彼此獨立
- 一個事件可以發生任何次數(在定義的時間段內)
- 兩個事件不能同時發生
- 事件發生之間的平均發生率是恒定的。
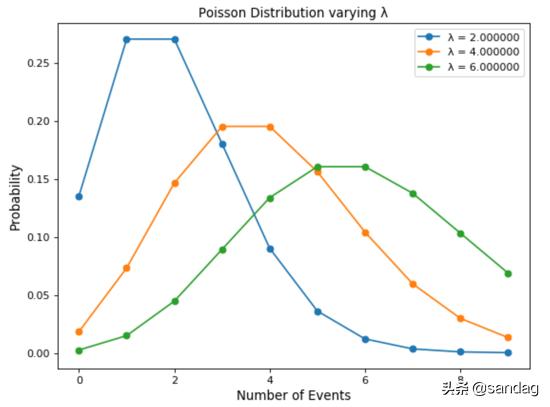
下圖顯示了改變λ的值是如何影響泊松分布的:
- for lambd in range(2, 8, 2):
- n = np.arange(0, 10)
- poisson = stats.poisson.pmf(n, lambd)
- plt.plot(n, poisson, '-o', label="λ = {:f}".format(lambd))
- plt.xlabel('Number of Events', fontsize=12)
- plt.ylabel('Probability', fontsize=12)
- plt.title("Poisson Distribution varying λ")
- plt.legend()
指數分布
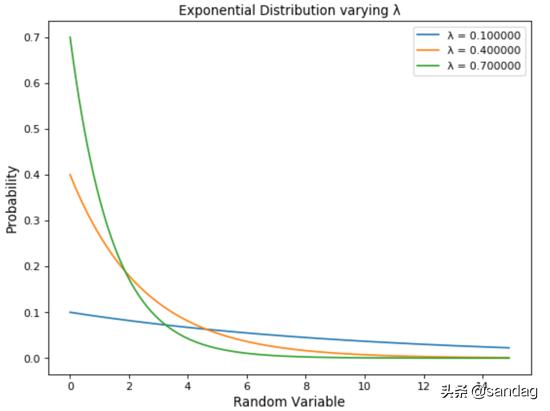
指數分布用于對不同事件之間的時間進行建模。
舉例來說,假設我們在一家餐廳工作,并且希望預測不同顧客來就餐的時間間隔。針對此類問題使用指數分布一個理想的起點。指數分布的另一個常見應用是生存分析(例如設備/機器的預期壽命)。
指數分布由參數λ調節。λ值越大,曲線的斜率變化越快。
- for lambd in range(1,10, 3):
- x = np.arange(0, 15, 0.1)
- y = 0.1*lambd*np.exp(-0.1*lambd*x)
- plt.plot(x,y, label="λ = {:f}".format(0.1*lambd))
- plt.xlabel('Random Variable', fontsize=12)
- plt.ylabel('Probability', fontsize=12)
- plt.title("Exponential Distribution varying λ")
- plt.legend()
指數分布使用以下公式建模