云“戰疫”:8天擴容100萬核,我們是這樣監控的
疫情當前,科技向善,騰訊應用都開始支撐各大遠程工作、教育的場景,眾所周知的“騰訊課堂”、“微信課堂”,“騰訊會議”在抗擊疫情中做出了很大的貢獻,數億人成為了這些系統的用戶。通過可視、互動的遠程有效溝通、交流,一定程度保障了生產、學習工作的有序進行。
筆者有幸參與了騰訊云的這次“戰疫”工作,監控系統有效地支撐了幾大應用場景。
01 業務的監控需求
騰訊會議放量較早、騰訊課堂、微信課堂也相繼放量,應對海量的用戶場景需求,我們分析系統的主要需求表現在:
1. 如何了解設備整體水位與資源趨勢?
前面提及過,各大系統基于視頻云技術搭建,視頻云本身存在較多的視頻、音頻處理工作,設備量的需求日益增長。每天面對數萬核、數十萬核的設備量需求,雖然每個模塊有各自的負載特點,但大盤層急需準確把控整體系統水位,從而判斷整體設備需求趨勢。跟后端的設備供應部門準確、有效地提出需求。
2. 如何針對有可能出現的問題,第一時間做出有效分析?
比如:
a. 如何避免在海量指標中把控重點指標?
從單維指標到多維指標,系統的指標上萬個,且由于歷史原因,指標散落在不同BG的數個監控系統,如果對于重點指標缺乏有效的抽象、監控。不分主次地處理,可能忽略重要指標的把控,引起嚴重后果。

圖一、錯綜復雜的立體式監控系統
b. 監控系統如何有效監測上述這些指標,使告警斂到合適范圍?
常見的監控手段為閾值監控,對業務形態比較熟練的開發、運維人員在指標上設置一個“恰當”的閾值,一旦偏離閾值,系統即發送告警到開發人員。
然而閾值設置的合理性不易判斷。在數千萬、上億用戶的場景下,閾值少設或多設 0.01% 都代表數千、上萬人的體驗受損,而且不同時間的數據,數據也會呈現一定的周期規律性,如圖二所示,簡單的閾值告警顯然無法滿足多樣化的業務需求。
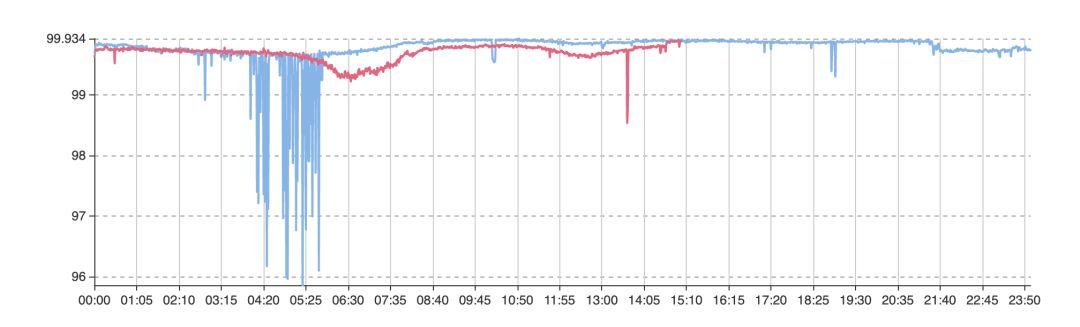
圖二、 無法判斷“閾值”的業務指標曲線
c. 問題發現的第一時間,開發、運維人員迫切需要知道問題的表現根因。以便快速介入處理,如何準確發現根因?
業務故障時,在大盤面,可能看到的是整個成功率(或用戶量)的下降。但引起下降的可能性是較多的。必須在第一時間找到原因,深入排查,以減少業務故障時間。
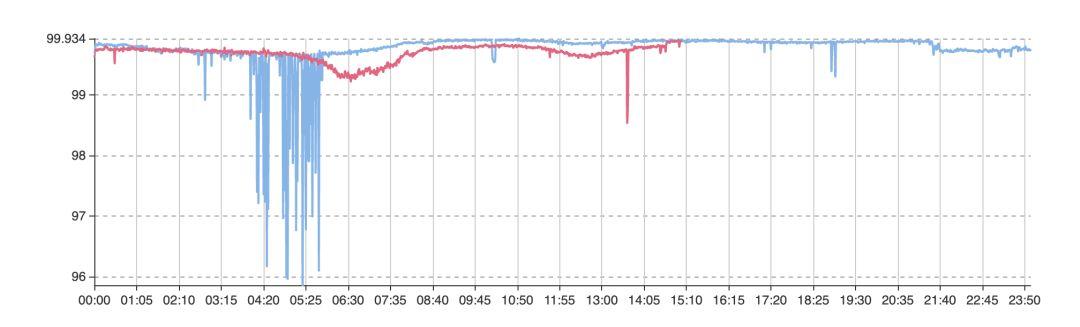
圖三-1 某業務整體大盤成功率曲線
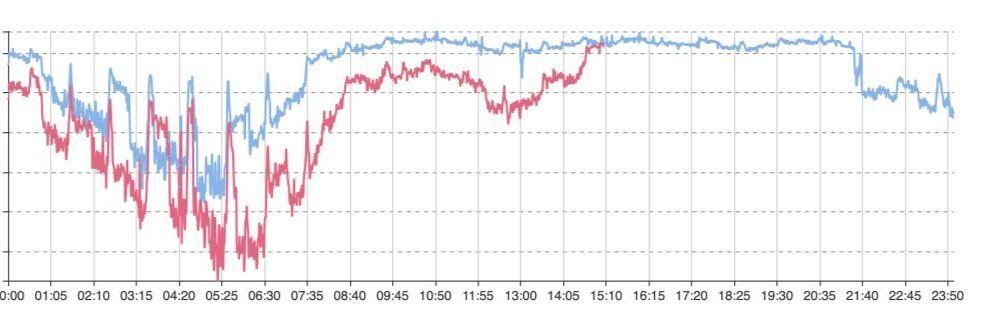
圖三-2 某業務下鉆維度成功率曲線
02 監控解決方案
監控的存在是為業務服務的,團隊一起進行了碰頭,很快形成了解決方案并實施:
一、梳理重點模塊、重點指標。建立直觀的業務可觀測性
基于業務架構剖析、業務形態理解,我們梳理起若干個關鍵指標。所謂關鍵即業務生死指標,這些指標可以從以下維度來衡量:
1、對用戶有損
用戶有損的指標有:在線用戶量,用戶登陸成功率,用戶進房成功率,關鍵接口調用成功率…
2、對收入有損
購買成功率、付費成功率、收入趨勢等 ……
3、資源風險相關
分SET、分模塊CPU負載、出口帶寬等、以便及時介入調度。一般每個SET的容量是有限的,必須及時觀察各SET容量水位及負載趨勢,一方面系統自行進行SET間用戶調度,一方面人為可在必要時進行調度干預。
二、導入自定義 Dashboard 能力
采用 Dashboard 展示以上指標,抽象形成數個作戰視圖。較為常見的 Dashboard 有 Grafana, Kibana 等,我們采用了較常用的開源 Grafana,原因是:
- 非常適合時序展示展示,提供自由的時間選擇功能;
- 易于運維人員自由定制。配置門檻極低;
- 易于適配各種異構數據源, 開發工作量較少。
在原有 Grafana 我們做了以下定制:
- 集成公司 OA 權限控制機制。
- 適配公司內部各監控系統數據源。時序數據庫存儲協議轉換,以有利于 grafana 直接拉取數據,而無需數據轉存,以節約數據存儲成本、獲得較為實時的數據效果。
圖四:自定義 dashboard
三、引入 AIOps 能力
1. 無閾值監控
在之前多次提及過無閾值監控,在此不做過多闡述。基于統計(無監督)及 基于數據特征、人員打標形成的有監督方法。在此次監控保障中發揮了重要力量。
同時工程上我們做了一些場景導入,我們開發了“云監控助手” 移動端。方便用戶自行一鍵訂閱、退訂指標。獲得了較好的告警觸達準確性。避免告警過多騷擾。同時通過用戶的訂閱退訂動作,形成了用戶的興趣點標簽,為后續的告警推薦、模型訓練打下了基礎。
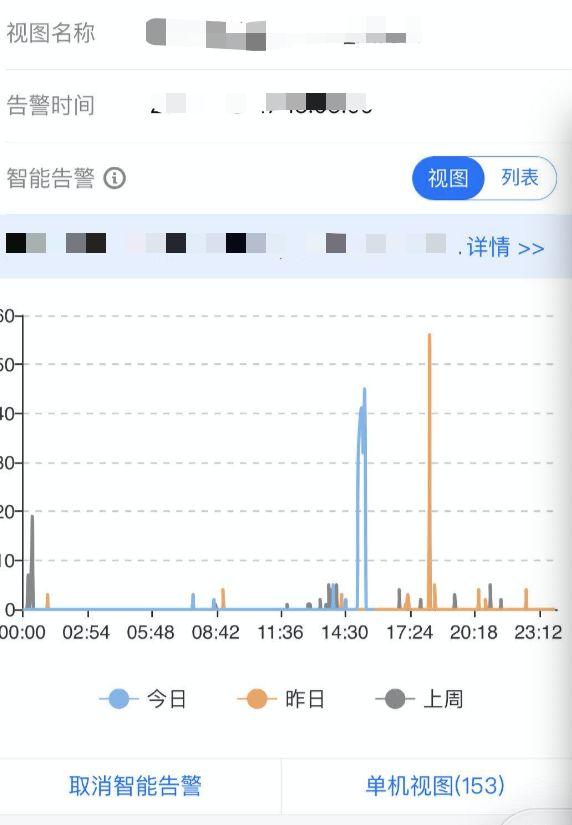
圖五 - 智能告警配置移動端
2. 智能多維
業務人員關注整體業務大盤,同時業務保障工作是一個相對細致的工作,既要保障大盤穩定性,也要隨時診斷導致各種業務異常的根因,現場如戰場,故障場景下,早一秒鐘獲得根因,就能早一秒鐘修復故障,減少損失,多維分析方法是非常快速的問題分析方法,舉兩個例子:
1)客戶端質量
客戶端問題一般出現在:無法登陸、卡慢、無法退出、無法發言、異常中斷等。這種情況下,一般根因上可能與客戶的地域、運營商、客戶端版本相關,利用智能多維較為容易找到客戶端根因匯聚。
2)后端 API 質量
后端 API 質量主要出現在服務間調用,騰訊云用戶API主要表現在WEB端調用后端和用戶應用調用騰訊云。一般根因上可以出現在用戶調用方式(API/WEB),地域、產品、命令字、版本等層面。通過智能多維能迅速找到匯聚。
多維根因分析實現流程如下:
- 統一業務指標上報,抽象Fields(指標) 與 Tags(維度) 上報至集中存儲, 相關技術選型有 Druid, InfluxDB, Prometheus等 。
- 抽象業務關鍵指標, 集中監控關鍵指標。
- 通過無閾值/有規則檢測方法獲得業務異常指標曲線。
- 獲得異常期間故障根因維度。常用算法:決策樹、Adtributor 等。
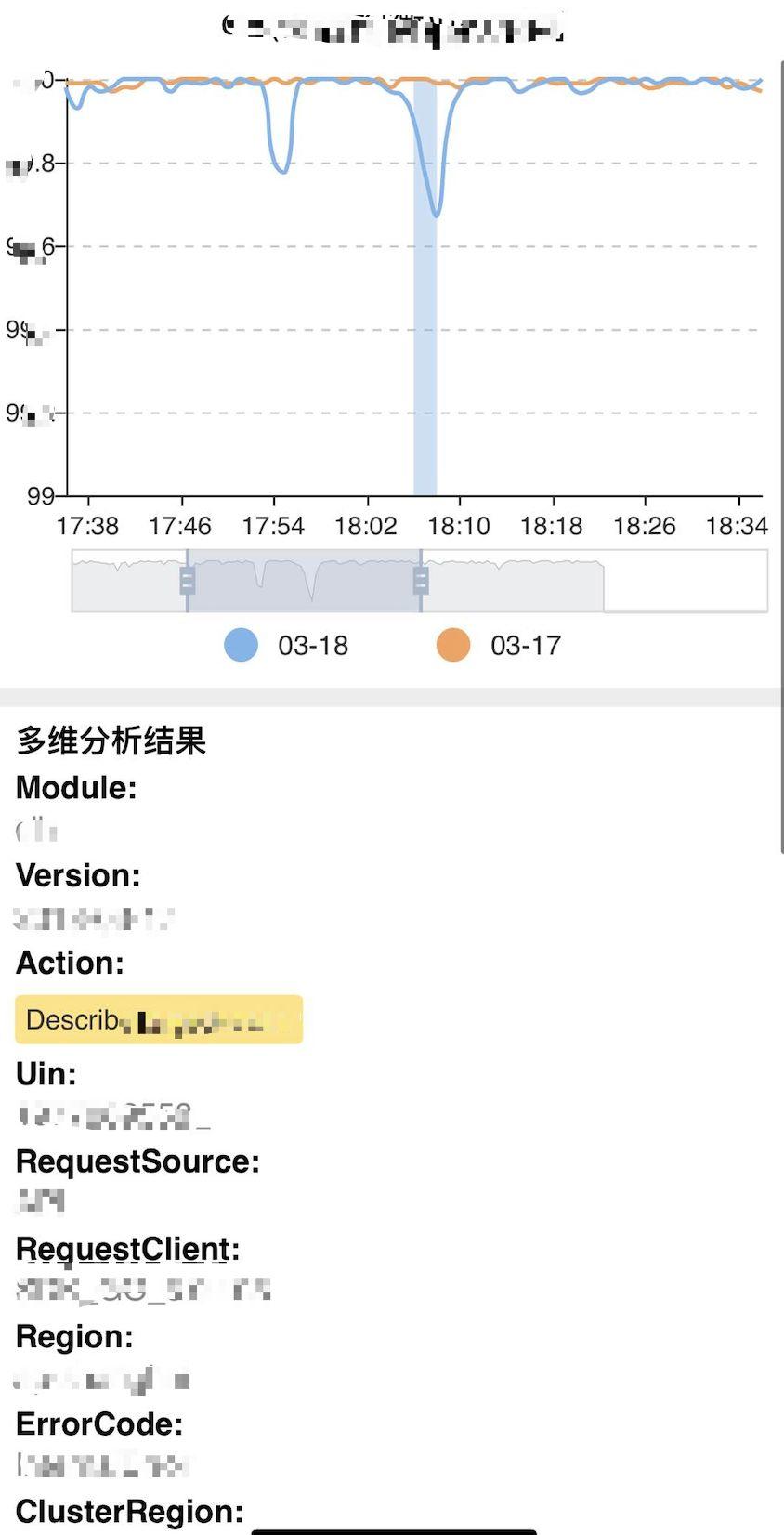
圖六 - 多維根因分析
3. 告警相似性
經過告警檢測后,產生的告警量可能還是不少,能對告警進行合并顯然是非常重要的需求,我們其中的一個解決辦法是先通過聚類算法對各告警源進行聚類(采用one-pass clustering, k-means等方法),各告警間的距離可以采用 Pearson 相似性公式獲得。
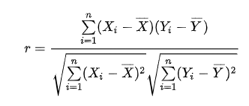
該方法能獲得較好的相似性效果,減少對人員的告警騷擾。
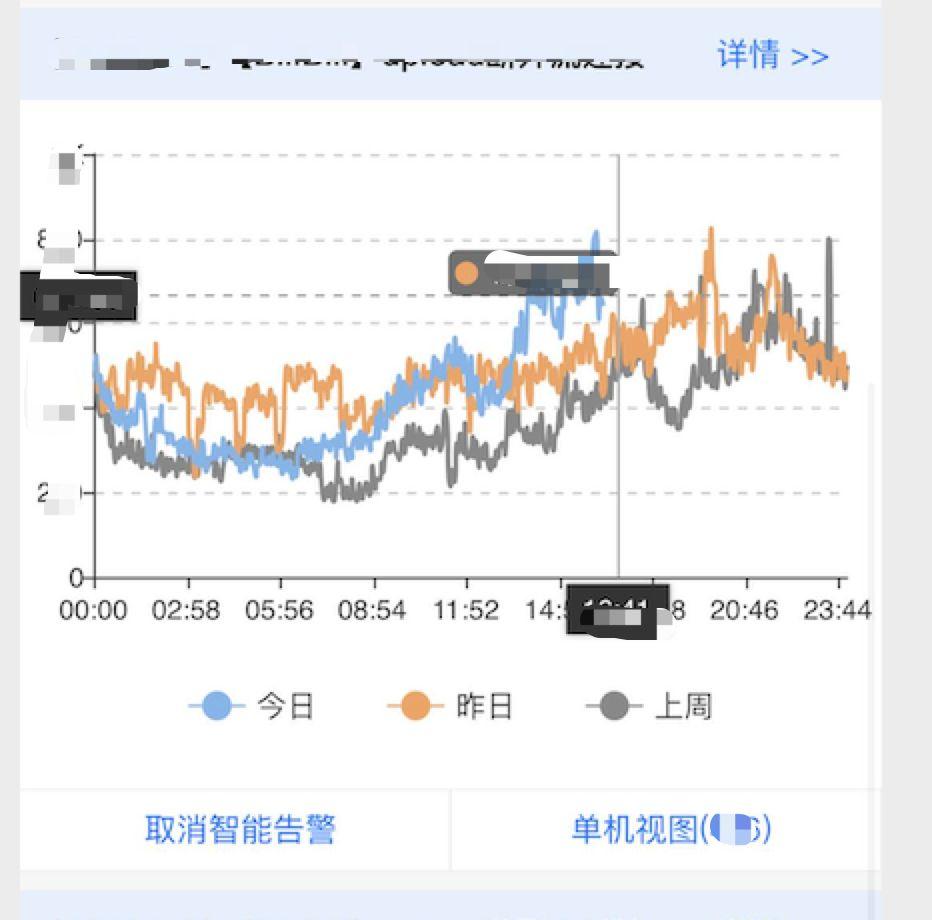
圖六:具有高度相似型的兩個指標
03 用戶反饋分析
用戶反饋分析的技術在騰訊內部已經相對成熟了,在2015年前后就已經相繼推出一些反饋分析功能。對于海量用戶反饋分析,此方法相對比較有效。
較為常見的處理方式是:
- 產品增加投訴入口,用戶的反饋通過接口上報至指定位置。
- 將投訴信息分詞,分詞方法很多,不再詳述。
- 分析詞頻,通過無閾值監控,對突增詞頻做重點分析處理。
但另一方面此類旁路監控,已經相對滯后。最有效的辦法是在問題發生前就解決它,而不是引起投訴后。
04 小記
隨著業務的發展,技術越來越中臺化,業務質量保障越來越重要,如何有效破除數據煙囪,形成統一視圖?監控的本質是數據,如何利用這些數據,及時發現業務問題、有效診斷業務問題,是監控的關鍵目的所在。