加速函數,每個Python程序員都應該了解標準庫的Lru_cache
加速新境界:通過使用簡單的緩存功能,僅需一行代碼即可加速你的函數。
不久前,我構建了一個日常運行的ETL管道,其通過從外部服務中抽取數據來豐富輸入數據,然后將結果加載到數據庫中。
隨著輸入數據的增加,等待外部服務器的響應變得非常費時,這使得ETL進程越來越慢。經過一番調查,我發現與總記錄數(~500k)相比,并沒有太多不同的輸入值(~500)。
因此,換句話說,使用相同的參數調用外部服務時,每個參數大約要重復執行1000次。
像這樣的情況是使用緩存的主要用例。緩存一個函數意味著無論何時首次計算函數的返回值,都會將其輸入和結果放在字典中。
對于每個后續函數調用,首先通過查看緩存來檢查結果是否已經計算過。如果在緩存中找到了,那就很完美,不需要再次計算!如果沒有找到,就計算結果并將輸入和結果存儲在緩存中,以便下一個函數調用時查找到它。
Python標準庫附帶了許多鮮為人知但功能強大的軟件包。對于本示例,將使用functools中的lru_cache。(LRU代表“最近最少使用(Least Recently Used)”,正如字面意思,這明確意味著緩存將保留最近的輸入/結果對。)
從Fun(c)tools中導入lru_cache
把c放進括號中有點像一個蹩腳的笑話,因為這樣functools就變成了fun tools(有趣的工具),使用緩存當然很有趣!
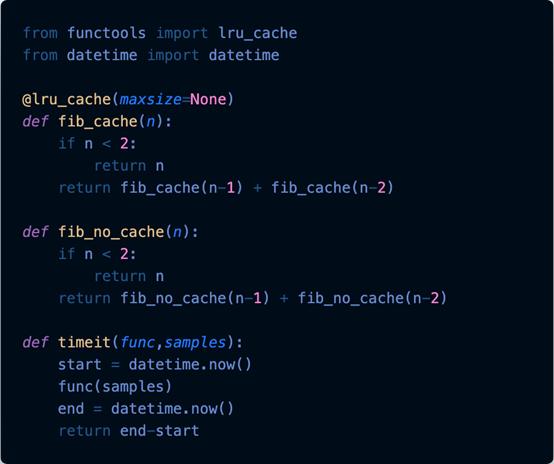
這里無需過多解釋。導入lru_cache并用它來裝飾一個函數,該函數將生成斐波那契數。
裝飾函數意味著將該函數與緩存函數包裝在一起,隨后每當調用fib_cache函數時,都將調用緩存的函數。
比賽開始
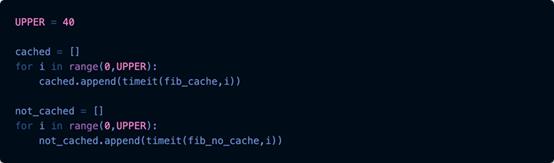
我們進行了一個實驗,計算函數的緩存和未緩存版本從0到40計算所有斐波那契數所花費的時間,并將結果放入各自的列表中。
獲勝者
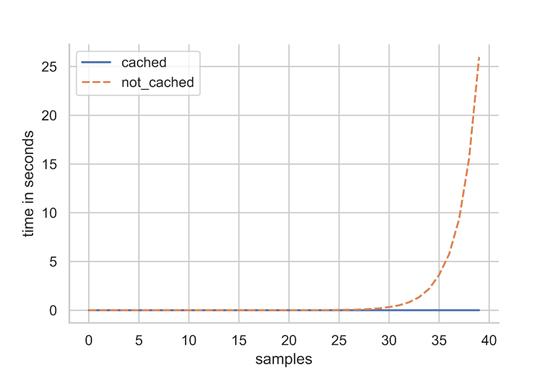
對于較小的斐波那契數,二者并沒有什么大的區別,但是一旦達到約30個樣本,緩存函數的效率增益就開始累加。
我沒有耐心讓未緩存的版本運行超過40個樣本,因為它的運行時間是指數增長的。而對于緩存的版本,它的運行時間只是線性增量。
這就完成了!距離Python緩存僅一行代碼之遙。畢竟它并沒那么可怕。
在初始示例中,我在Pandas數據框上使用了數據轉換。值得一提的是,緩存的函數可以傳遞給Pandas apply,而無需進行其它的任何更改。
是不是很棒?你也來試試吧~