作為一個搞運維的,你真的了解SRE么?
0、為什么誕生 SRE?
- 原因一:企業成本的增長同用戶的增長不成線性變化。但是隨著系統的復雜度提升,組建越來越多,用戶的流量壓力也越來越大,相關的變更也會越來越多,各模塊之間的變更順序也會越來越復雜。在這樣的情況下,單純的靠運維人力的數量提升無法滿足業務的發展需求,而且會提升企業的成本;
- 原因二:傳統的研發團隊和運維團隊天然具有沖突。公司的IT人員的配置:研發(Dev)和運維(Ops),研發部門聚焦在快速構建和快速發布;運維部門關注的是如何避免發生故障,從目標上講就是矛盾的。且隨著 IT 技術的發展,對 IT 從業者的要求也越來越高,既要懂得底層系統,也要懂得數據算法,同時對主流技術還要快速追趕,滿足這樣要求的人才太少;
- 原因三:生產工具為適配生產力發展的必然產物。為了提高IT行業的整體效率和質量,使得從手工運維時代,逐漸過度到腳本工具運維,在發展到平臺數據運維,再到平臺軟件運維,在發展到智能自動化運維。通過一系列手段、工具、理念的進步,將 Ops 技術發展到 DevOps、DataOps、AIOps 等;
一、什么是 SRE?
1.1 SRE 的基本了解
那么區別于研發同學和運維同學,SRE 要做一些什么工作,又要具備什么樣的能力呢?
Google 試從解決 Dev 和 Ops 之間的矛盾出發,雇傭軟件工程師,創造軟件系統來維護系統運行以替代傳統運維模型中的人工操作。SRE 團隊和產品研發部分在學術和工作背景上非常相似,從本質上將,SRE 就是在用軟件工程的思維和方法論完成以前由系統管理員團隊手動完成的任務。
Google 的 SRE 具體會負責哪些?
SRE在Google不負責某個服務的上線、部署,SRE主要是保障服務的可靠性和性能,同時負責數據中資源分配,為重要服務預留資源,SRE并不負責某個業務邏輯的具體編寫,主要負責在服務出現宕機等緊急事故時,可以快速作出響應,盡快恢復服務,減少服務掉線而造成的損失。
SRE 日常工作和職責包含哪些
一般來說,SRE團隊要承擔以下幾類職責:可用性改進、延遲優化、性能優化、效率優化、變更管理、監控、緊急事物處理以及容量規劃與管理。
Tools Don’t create reliability. Humans do. But tools can help.
SRE 的使命
在減少資源消耗的同時,從可用性和性能層面,提升用戶的體驗。
Operations should NOT be a part of SRE missions. Operation is a way to understand production.
1.2 SRE 的技能堆棧
語言和工程實現
- 深入立即開發語言(Java/Golang等)
業務部門使用開發框架
并發、多線程和鎖
資源模型理解:網絡、內存、CPU
故障處理能力(分析瓶頸、熟悉相關工具、還原現場、提供方案)
常見業務設計方案,多種并發模型,以及相關 Scalable 設計
各類底層數據庫和存儲系統的特性和優化
問題定位工具
- 容量管理
- Tracing 鏈路追蹤
- Metrics 度量工具
- Logging 日志系統
運維架構能力
- Linux 精通,理解 Linux 負載模型,資源模型
- 熟悉常規中間件(MySQL Nginx Redis Mongo ZooKeeper 等),能夠調優
- Linux 網絡調優,網絡 IO 模型以及在語言里面實現
- 資源編排系統(Mesos / Kubernetes)
理論
- 機器學習中相關理論和典型算法
- 熟悉分布式理論(Paxos / Raft / BigTable / MapReduce / Spanner 等),能夠為場景決策合適方案
- 資源模型(比如 Queuing Theory、負載方案、雪崩問題)
- 資源編排系統(Mesos / Kubernetes)
二、SRE 是如何解決問題的?
2.1 解耦中臺系統與應用
研發同學為生產環境負責,而SRE為組件或集群的可服務能力和穩定性負責
SRE工程師中大部分是標準的軟件工程師,他們擅長使用系統工程的方法去解決基礎系統中的問題,同時持續的、工程化的解決問題,使得運維的壓力不會隨著上層應用的增加而線性增加(通常20人的SRE團隊,可以支持上千研發同學的應用開發)。同時SRE同學對Unix系統內部細節、1~3層網絡比較了解,可以同研發一起分析應用程序性能問題。
SRE應該更好的進行系統元數據的管理
系統的元數據應該是系統的架構拓撲圖,通過動態、準確的更新元數據可以將采集到的Event、Message、Metric 等數據映射到真實環境中去,并能通過各種手段進行系統健康程度的診斷,是的自動化監控和管理成為可能。
SRE通過穩定性進行抽象,可以通用的解決穩定性問題
為了讓龐大系統的運行效率提高,要不斷的優化系統中的熱點,并將系統中的熱點服務擴展、升級、重構成為一個組建化的服務,這也是SRE中解耦系統的方法。不僅如此,SRE對各個服務的可用性進行標準化定義,將統一的標準應用到不同的服務中去,將穩定性作為各個服務的重要度量指標,通過上述操作,收攏服務治理問題,提供系統的魯棒性。
2.2 明確服務之間的可用性依賴
2.2.1 面向 SLO 編程標準的推行

針對 SLO,我們舉一個例子來說明以下,
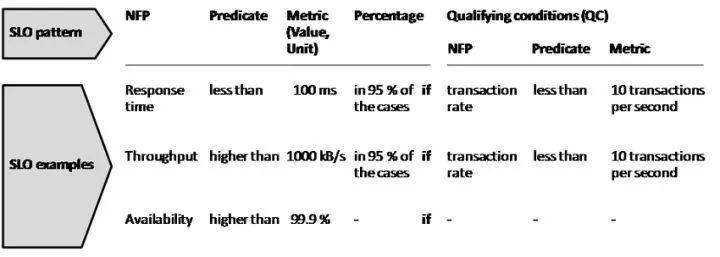
為什么要有 SLO,設置 SLO 的好處是什么呢?
- 對于客戶而言,是可預期的服務質量,可以簡化客戶端的系統設計
- 對于服務提供者而言
可預期的服務質量
更好的取舍成本/收益
更好的風險控制(當資源受限的時候)
故障時更快的反應,采取正確措施
注:
- 關于如何來定義SLO是一個相當復雜的事情,這個使用往往跟用戶體驗有直接的關系,推薦一個實際案例來展開,如何定制自己服務的SLO。
(Case Study: Implementing SLOs for a New Service - https://www.usenix.org/conference/srecon19americas/presentation/lawson)
- 推薦一篇文章,闡述請求延時的SLO如何指定的,具體可以參考鏈接《Latency SLOs Done Right》https://www.usenix.org/sites/default/files/conference/protected-files/srecon19apac_schlossnagle_latency_slides.pdf
- 推薦一篇文章,從請求在系統運行中闡述了一些核型的SLO該如何制定,《How to trade off server utilization and tail latency》https://www.usenix.org/sites/default/files/conference/protected-files/srecon19apac_slides_plenz.pdf
2.2.2 面向 SLO 監控的設計
SLO 結果導向的告警,而不是原因導向的告警
- 四個黃金信號
服務不可用,或訪問速度變慢時,往往會影響到產品的整體質量,目前了解到的一些基礎監控指標就達到上百種,通常的做法是在這些指標當中需要選取平臺或業務比較關注的指標進行監控報警;
Google的網站可靠性工程師小組(SRE)定義了四個需要監控的關鍵指標。
他們稱之為“四個黃金信號”:延遲(Latency),流量(Traffic),錯誤(Errors)和飽和度(Saturation)。這四個信號應該是服務級別非常關鍵部分,因為它們對于提供高可用性的服務至關重要。
- 如何定義高質量的監控:
明確業務服務的SLO(應該與該業務提供給客戶的期望達成一致),并采用合理的SLI來描述;
比如計數信息(總量、成功量)、測量信息(同比、環比);
主觀上監控應該有豐富的內部狀態數據、具備高可觀測性條件;
客觀上具備業務視角,能夠快速定位是全局問題還是局部問題;
系統本身的魯棒性,不會因為某個局部問題影響監控的權威性;
具備quota限制能力,防止出現容量的問題;
報警清理和定期的規則優化,定期進行盤點告警,并優化掉無SLO影響的規則;
2.3 完善的場景化演練
自動化系統的建設中除了要考慮系統的能力外,還要考慮人在其中所發揮的重要作用,畢竟一旦一些突發的時事件若必須由人來處理,則這時刻人的穩定性和準確性也是需要保證的。微軟在SRE大會中提出了一個有意思的觀點:如果一個系統能夠比人做的更好,那人應該知道如何監控這個系統本身。
因此,在保證SLO的情況下,可以做一些攻防演練(關閉SRE系統的UI后,SRE該如何操作?);或構建一個模擬系統,讓人來執行系統;并學習故障的復盤報告等。
三、淺談 SRE 的觀察
3.1 從 SRE 2019 觀察
SRE CONF 2019 傳送門:
- Conference Report:
SRECON AMERICAS 2019 :
https://noidea.dog/blog/srecon-americas-2019
- Conference Program:
SRECON Asia/Pacific 2019 :
https://www.usenix.org/conference/srecon19asia/program
3.2 幾個應該多花精力關注的點
- 系統的可觀測性,換句話說是你真的了解你的系統么?你真的了解你的應用么?(不僅是后臺系統、還有一些移動端系統和應用)要從 Logs 中索取更多的知識,挖掘出更多的內容供 SRE 使用。
- 隨著觀測性要求的不斷提供,靈活、新穎的可視化工具被大家越來越認可,單獨使用線圖進行可視化指標是遠遠不夠了,需要更加新穎和便捷的可視化方案;同時要讓數據產生價值,而不是簡單的可視化,越來越多的公司使用Pipeline來解決相關任務的創建和管理,讓數據清洗和規整后變的更優價值,使得算法產生最大的效用。
- SRE 不僅僅要發現系統中存在的熱點問題,也要能快速解決這些熱點問題,并在以后的架構演進中消除這樣的問題,則系統的自愈能力應該成為每個公司都關注的問題。