













讓數據科學家代替DJ?Python幫你實現
數據科學是一門龐大的學科,它不斷地擴展到新的行業,音樂產業就是其中之一。如果把這些應用程序當作一個“黑匣子”,可以觀察到它的輸入(數據)和輸出(產品)。該項目旨在使用Python操作Spotify音樂數據,其范圍有兩個:
- 證明API(應用程序編程接口)的存在對于向算法提供超精細數據具有重要意義。
- 演示簡單的統計數據(適當應用時)如何對日常行為進行編碼,將其分解為基本要素,并在其基礎上構建有價值的產品。
這個故事,最開始是為了調查音樂背后的統計數據,最后發現方程式背后也有“音樂”……
概念
假設一個情景。作為一名數據科學家,筆者工作的數據公司(Data Corp)記錄了青年營銷部門獲得的可觀利潤,因此公司決定舉辦聚會犒勞年輕的客戶。
在沒有DJ的情況下,主管讓筆者負責音樂,讓派對持續到早上!她給了筆者一些Spotify播放列表,讓筆者最終選定并創建一個。然而,忽視現代音樂趨勢讓筆者遇到一個棘手的問題。
使用Python訪問所有播放列表,提取每個曲目的每個音頻特征進行統計分析,并將最適合(派對)的曲目包裝到最終的播放列表中,如何?當然,這里有一個技術性的問題:一個節拍也聽不到!
為了更好地傳達結果,假定:
#1:個人Spotify播放列表代表的是公司給筆者的。
#2:該聚會的目標群體是18至30歲的年輕人,這意味著……跳舞!然而,他們中的許多人可能會有家人陪伴,也就是說,一小部分客人會更好地享受到歡快的音樂。
#3:在音頻特性中,Spotify只考慮了 danceability, energy, tempo, loudness & valence (見第2節)。那是因為,它們能更好地表達一首曲子是否適合一個舞會。
#4:改進所選播放列表的方法有兩種:刪除或添加分別被視為“壞”或“好”(涉及一個或多個音頻特征)的曲目。筆者只采用后者,以擴大最終的播放列表。
筆者打算按下面的步驟來做:
- 設置運行代碼的環境。
- 請求Spotify API獲取所有相關音樂數據并提供簡要說明。
- 使用Numpy、Pandas和一些附加的Python庫執行EDA(探索性數據分析),以數字和可視化的方式探索候選播放列表。
- 選擇-使用兩種統計技術優化最合適的播放列表。
一、設置
在本節中,設置所需的環境,以便應用分析技術。如果已經準備好下面列出的任何部分,可以跳過它們。
- 申請Spotify開發者帳戶并創建應用程序。[在此過程中,將創建一個客戶ID,并為應用程序提供一個客戶機密]。
- 安裝Jupyter Notebook-一個開源的web應用程序,用于創建/共享包含實時代碼、方程式、可視化和敘述性文本的文檔。
- 安裝Spotipy-用于訪問Spotify Web API和請求的輕量級Python庫-用于尋址API的Python模塊。可以使用CLI(命令行界面)或Jupyter notebook來運行以下命令:
- pip install spotipy
- pipinstall requests
install.py
- 導入必要的庫:
- # Import the libraries
- import os
- import pandas as pd
- import numpy as np
- import json
- importmatplotlib.pyplot as plt
- import seaborn as sns
- import spotipy
- importspotipy.util as util
- fromspotipy.oauth2 importSpotifyClientCredentials
- 執行授權代碼流:
- # Declare the credentials
- cid ='XXXX'
- secret ='XXXX'
- redirect_uri='http://localhost:7777/callback'
- username ='XXXX'
- # Authorization flow
- scope ='user-top-read'
- token = util.prompt_for_user_token(username, scope, client_id=cid,client_secret=secret, redirect_uri=redirect_uri)
- if token:
- sp = spotipy.Spotify(auth=token)
- else:
- print("Can'tget token for", username)auth.py
請注意,與其通過筆記本直接聲明憑證,還不如通過相應地設置環境變量,使它們暫時可用:
- export SPOTIPY_CLIENT_ID="XXXX"
- exportSPOTIPY_CLIENT_SECRET="XXXX"
- exportSPOTIPY_REDIRECT_URI="http://localhost:7777/callback"
二、數據解釋與獲取
Spotify為其開發人員提供了許多表征音軌的音頻特征(有關音頻特性對象的更全面的解釋,請參見此處)。下面列出要使用的特征,并簡要說明:
- Loudness:[-60.0-0db]描述了音軌的整體響度,或者說,聲音的質量,這是與體力(振幅)相關的主要心理因素。
- Energy:[0.0-1.0]描述了對活動和強度的感性測量。充滿活力的音軌讓人感覺快速、響亮和嘈雜。
- Valence:[0.0-1.0]描述音軌聽起來“積極”的程度。高價意味著更積極的聲音(如歡快、歡快等)。
- Tempo:以BPM為單位描述音軌的總體估計節奏(每分鐘節拍),直接從節拍平均的持續時間得出。
- Danceability:[0.0-1.0]根據音樂元素(節奏、穩定性、節拍強度等)的組合,描述一個軌道是否適合跳舞。低值意味著較少的舞步。
數據提取部分分三步完成:訪問用戶播放列表;提取每個播放列表的曲目;提取每個曲目的音頻特征。對于每個步驟,創建一個函數,實現相應的Spotipy方法。
(a)訪問用戶的播放列表
- deffetch_playlists(sp,username):
- """
- Returns theuser's playlists.
- """
- id = []
- name = []
- num_tracks = []
- #Make the API request
- playlists = sp.user_playlists(username)
- for playlist in playlists['items']:
- id.append(playlist['id'])
- name.append(playlist['name'])
- num_tracks.append(playlist['tracks']['total'])
- # Create the final df
- df_playlists = pd.DataFrame({"id":id, "name":name, "#tracks": num_tracks})
- return df_playlists
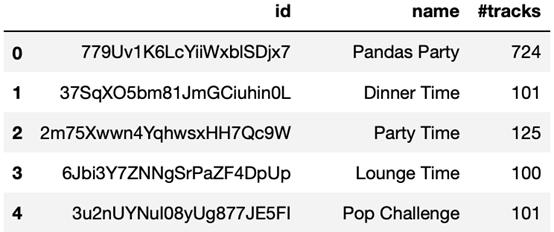
- playlists =fetch_playlists(sp,username)
- playlists= playlists[:4].copy()
- playlists
fetch_plst.py
此函數返回一個數據幀,其中包含用戶播放列表的id、name和曲目數#tracks。顯然,有4個候選播放列表:
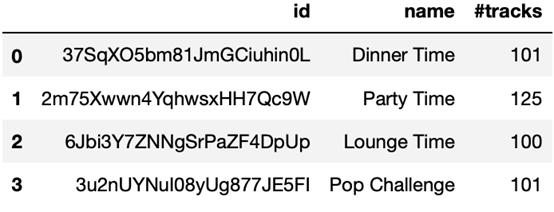
playlists 數據幀
(b) 獲取播放列表的曲目
- deffetch_playlist_tracks(sp, username, playlist_id):
- """
- Returns thetracks for the given playlist.
- """
- offset =0
- tracks = []
- #Make the API request
- whileTrue:
- content = sp.user_playlist_tracks(username, playlist_id, fields=None, limit=100, offset=offset,market=None)
- tracks += content['items']
- if content['next'] isnotNone:
- offset +=100
- else:
- break
- track_id = []
- track_name = []
- for track in tracks:
- track_id.append(track['track']['id'])
- track_name.append(track['track']['name'])
- #Create the final df
- df_playlists_tracks = pd.DataFrame({"track_id":track_id, "track_name": track_name})
- return df_playlists_tracks
fetch_trcs.py
這個函數以playlist_id作為參數,返回一個數據幀,包括每個曲目的曲目 track_id 和 track_name 。不直接調用它,而是在下面的函數中使用它。
(c) 獲取曲目的音頻特征
- deffetch_audio_features(sp, username, playlist_id):
- """
- Returns theselected audio features of every track,
- for the givenplaylist.
- """
- # Usethe fetch_playlist_tracks function to fetch all of the tracks
- playlist =fetch_playlist_tracks(sp, username, playlist_id)
- index =0
- audio_features = []
- #Make the API request
- while index < playlist.shape[0]:
- audio_features += sp.audio_features(playlist.iloc[index:index+50, 0])
- index +=50
- #Append the audio features in a list
- features_list = []
- for features in audio_features:
- features_list.append([features['danceability'],
- features['energy'],features['tempo'],
- features['loudness'],features['valence']])
- df_audio_features = pd.DataFrame(features_list,columns=['danceability', 'energy',
- 'tempo', 'loudness', 'valence'])
- # Set the 'tempo' & 'loudness' in the same range withthe rest features
- for feature in df_audio_features.columns:
- if feature =='tempo'or feature =='loudness':
- continue
- df_audio_features[feature] =df_audio_features[feature] *100
- #Create the final df, using the 'track_id' as index for future reference
- df_playlist_audio_features = pd.concat([playlist,df_audio_features], axis=1)
- df_playlist_audio_features.set_index('track_id', inplace=True, drop=True)
- return df_playlist_audio_features
fetch_aud_ftrs.py
給定 playlist_id 作為參數,此函數返回每個曲目的 track_id, name 和音頻特征(danceability, energy, tempo, loudness, valence)。因此,對于4個播放列表中的每一個,創建相應音頻特征的數據幀:
- df_dinner =fetch_audio_features(sp, username, '37SqXO5bm81JmGCiuhin0L')
- df_party=fetch_audio_features(sp, username, '2m75Xwwn4YqhwsxHH7Qc9W')
- df_lounge=fetch_audio_features(sp, username, '6Jbi3Y7ZNNgSrPaZF4DpUp')
- df_pop=fetch_audio_features(sp, username, '3u2nUYNuI08yUg877JE5FI')
aud_ftrs.py
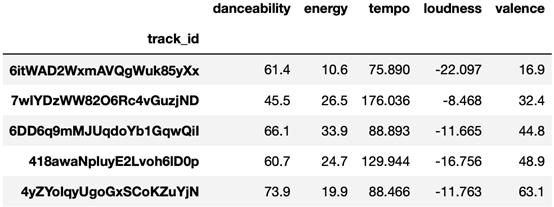
df_dinner 數據框示例
僅僅借助API的力量就獲得了所有必要數據的純編碼!
三、EDA
為了減少混亂,這里不包括數據可視化代碼,但它可以在GitHub repo上使用。
首先,在一個圖中描繪所有播放列表的音頻特征,以便容易地感知哪個最適合聚會。
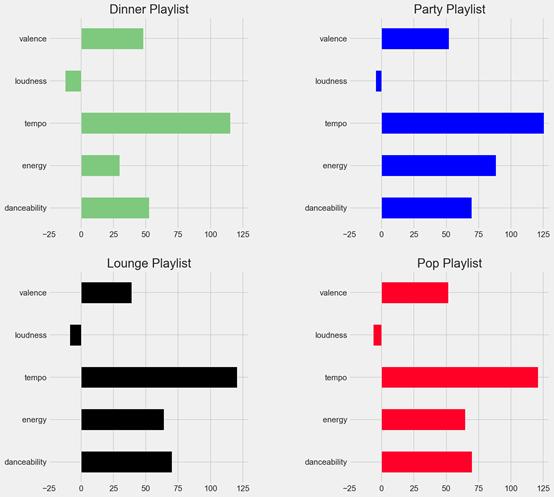
音頻特征水平條形圖
顯然,把特征作為整體來看,Party和Pop播放列表取代了另外兩個。仔細看看這兩個,就能更清楚地了解哪一個占上風…
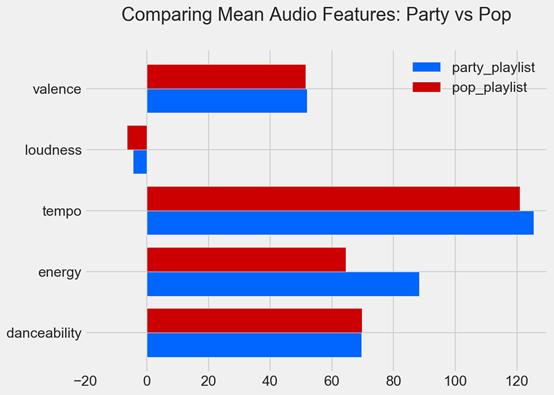
df_party 和df_pop水平橫條圖
除了danceability特征外,其他特征在派對播放列表中更高。這是一個必須選擇和建立,以完善最終的播放列表。
四、播放列表的優化
其主要作用是盡可能增加派對播放列表的音頻特征。但是,增加一個特征可能會減少另一個特性,因此必須考慮優先級。就筆者個人而言,根據假設2,danceability(年輕人)應該是主要特征,下一個特征是valence(家庭成員)。
這些變量是定量的,同時也屬于比率尺度的測量。因此,箱線圖可以有效地描述每個特征的個體分布。這樣的圖表和描述性統計表(通過pandas.DataFrame.describe方法)可以提供關于每個特定四分位數下的值的比例的良好視覺展示。
下面將詳細說明原始的df_party數據框,突出顯示danceability和valence平均值、第二(中位數)和第三個四分位數:
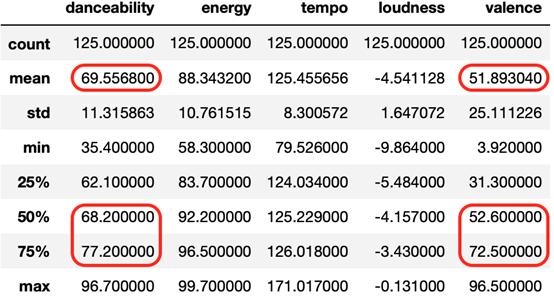
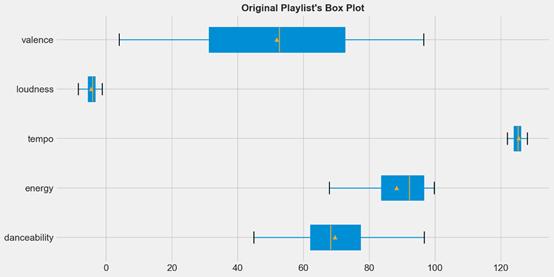
df_party數據的描述性統計和箱線圖
豎直的黃線是中位數,而▴符號代表平均數。一般的目標是“推動”每一個特征的分布盡可能地向右,也就是說,沿著播放列表曲目方向增加,以便獲得一個更好的“聚會”體驗!根據假設4,從df_pop(第二個決賽播放列表)中添加曲目,每次都尋找機會:
- 將平均值向右移動(增加平均音頻特征)
- 或將中位數移到平均值的右側(確保至少50%的歌曲高于平均值)
- 或兩者兼而有之
方法一
一個好的出發點是,抽取一個df_pop的樣本,并將其添加到主樣本(df_party)中,隨機的除外。通過使用pandas.DataFrame.sample()函數和weights參數,可以預先配置danceability值越大,就越有可能對相應的行進行采樣。這種方法產生的數據框是df_party_exp_I(exp代表expanded)。
- # Take a sample from the Pop playlist
- df_pop_sample_I= df_pop.sample(n=40, weights='danceability',random_state=1)
- df_pop_sample_I.describe()
- # Concatenate the original playlist with the sample
- df_party_exp_I= pd.concat([df_party, df_pop_sample_I])
- df_party_exp_I.describe()
sample_I.py
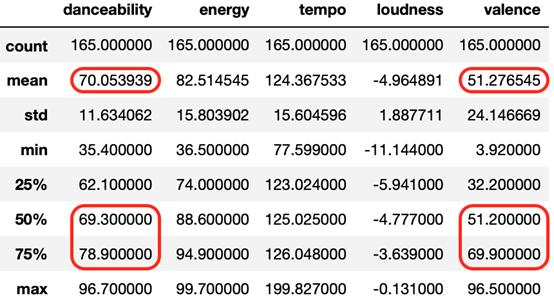
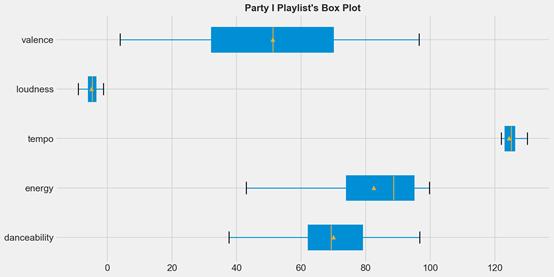
df_party_exp_I描述性統計和方框圖
- 主要音頻特征danceability增加;平均值上升近0.5,其分布也略有優化。中位數從68.20移到69.30,第三(上)四分位數分別從77.20移到78.90。
- 但是, valence特征下降了0.61,四分位都沒有向右移動。鑒于此,應該尋找進一步的優化機會。
方法二
這一次將利用NumPy布爾索引并過濾Pop播放列表,以便只返回滿足指定條件的行。特別是,將danceability和valence特征設置為高于派對播放列表的相應平均值,分別為69.55和51.89。
- # Take a sample from the Pop playlist
- df_pop_sample_II= df_pop[(df_pop['danceability'] >69.55) & (df_pop['valence'] >51.89)].copy()
- # Concatenate the original playlist with the sample
- df_party_exp_II= pd.concat([df_party, df_pop_sample_II])
- df_party_exp_II.describe()
sample_II.py
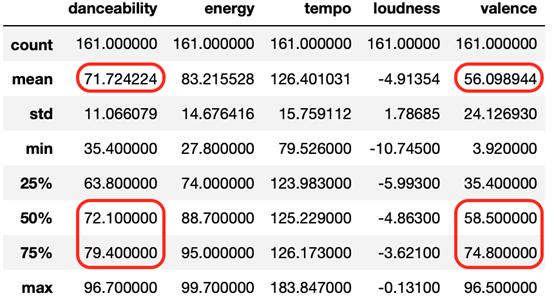
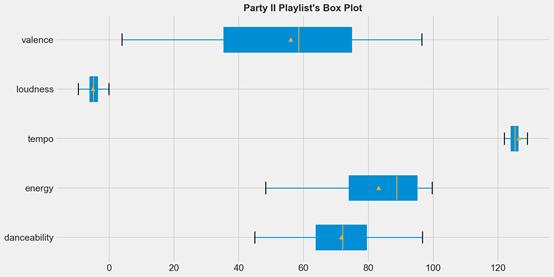
df_party_exp_II描述性統計和方框圖
- danceability增加更多。這次平均值增加了將近2.17!隨著中位數和上四分位數向右移動,沿著該功能的曲目分布也得到了優化,這基本上意味著至少50%的播放列表高于主要聲學功能的“新”較高平均值(71.71)。
- 盡管如此,valence特征下降了4.21,第二和第三個四分位數均高于平均值。
方法三
一個特征的優化并不一定意味著其他特征的優化。為了改善這一缺點,將引入一個方程,其變量是聲學特征,參數是賦予它們的權重。既然非常重視danceability特征,那么相應的權重應該更高。最后分數計算如下:
Score =(danceability *30)+(energy *20)+(tempo *20)+(loudness *10)+(valence *20)
為播放列表的每個單曲計算這個分數(創建一個新的列score),然后計算各自的描述性統計。這樣,可以更好地評估,豐富df_party,同時在每個特征上實現更統一(根據權重)的優化。
簡言之,df_party, df_party_exp_I & df_party_exp_II的平均score分別為7355分、7215分和7416分。很明顯,雖然方法一相比原來的播放列表找到了更好的danceability,但它破壞了派對的整體體驗(平均score從7355下降到7215)。就方法二而言,平均score提高了近62分。然而,也可以不用這兩種方法…
這一次,通過使用新引入的score列,將過濾df_pop數據幀,并獲取注意到score高于df_party平均值的行。因此,增加后者!
- # Take a sample from the Pop playlist
- df_pop_sample_III= df_pop[df_pop['score'] > df_party['score'].mean()].copy()
- # Concatenate the original playlist with the sample
- df_party_exp_III= pd.concat([df_party, df_pop_sample_III])
- df_party_exp_III.describe()
sample_III.py
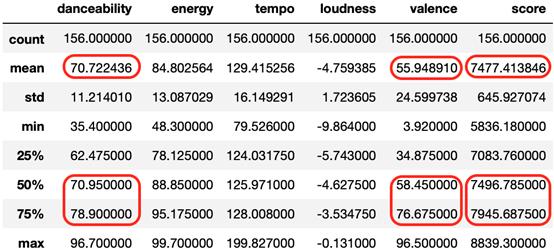
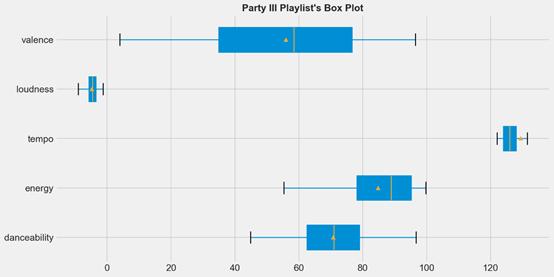
df_party_exp_III描述性統計和方框圖
事實上,這次:
- danceability特征提高了近1.17,valence增加了4.06(平均值的右移)
- 兩種分布都得到改善(中位數移到平均值的右側)
- score為122.3,是目前為止最好的!(上下文意味著更高的潛力,播放列表在加權音頻特征上更加統一)
作為一個完整的檢查,應該一次性描述和比較所有的方塊圖—這可能看起來有點擁擠。幸運的是,變量的性質(見上文)允許使用KDE(內核密度圖)。
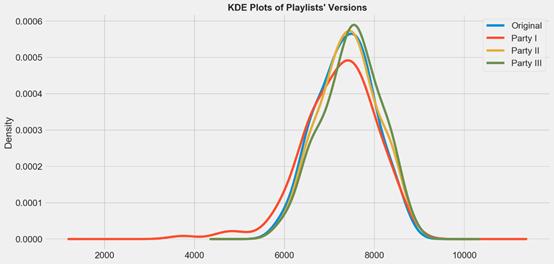
KDE圖
現在非常清楚了,方法三(綠色分布)是最好的,因為它實現了更高的右移。
最后,最終得到的數據幀(df_party_exp_III)包含了最終的音軌。唯一懸而未決的操作是將其轉換為真正的播放列表。下面,第一個函數創建最終的播放列表,將其名稱作為參數以及描述。另一個,從數據幀遷移軌跡。
請注意,授權流將再次運行,這次將使用不同的作用域(playlist modify public)。只需查看指南就好(https://github.com/makispl/Spotify-Data-Analysis/blob/master/README.md)。
- defcreate_playlist(sp,username, playlist_name, playlist_description):
- playlists = sp.user_playlist_create(username, playlist_name, description =playlist_description)
- create_plst.py
- defenrich_playlist(sp,username, playlist_id, playlist_tracks):
- index =0
- results = []
- while index <len(playlist_tracks):
- results += sp.user_playlist_add_tracks(username, playlist_id, tracks =playlist_tracks[index:index +100])
- index +=100
enrich_plst.py
- # Make a temporary list of tracks
- list_track =df_party_exp_III.index
- # Create the playlist
- enrich_playlist(sp,username, '779Uv1K6LcYiiWxblSDjx7', list_track)
create_plst.py
播放列表數據幀
Bingo!
結論
到目前為止,已經處理了數百首曲目,檢查了它們的音頻特征,最后選擇了最適合聚會的曲目,只用到了Python。通過這種方式,成功地完成了任務:
- 演示了簡單(描述性)的統計數據和編碼(如果適當組合)是如何計算出此類耗時的活動的。
- “嘗到”了擁有可請求的API的重要性,以便提取有意義的數據。
無論是從DJ還是從數據科學家的角度“深入”音樂世界,這無疑都是美妙的……
但是,有效地,當涉及到大量音樂數據集的精確性、敏捷性和徹底處理時,后者可以通過幾行代碼來指示計算機體面地執行。也就是說,有一件事是必然的:
數據科學已經找到了另一個發展壯大的“市場”,這意味著統計背后確實有“音樂”,達到了節拍背后有數學的水平…
Jupyternotebook已準備好立即運行,讓Pandas搖滾吧!














