老板問我分布式鎖,結果悲劇了......
公司交給了萌新小猿一個光榮而艱巨的項目,該項目需要使用分布式鎖,這可難到了小猿。
圖片來自 Pexels
只是聽說過分布式鎖很牛掰,其他就一概不知了,唉,不懂就問唄,遂向老板請教。
老板:我們每天不都在經歷分布式鎖嗎,我來給你回憶回憶。
小猿:好勒,瓜子板凳已備好。
本文結構:
- 為什么要使用分布式鎖
- 分布式鎖有哪些特點
- 分布式鎖流行算法及其優缺點
- 總結
為什么要使用分布式鎖
這個問題應該拆分成以下 2 個問題回答。
①為什么使用鎖
保證在同一時刻共享資源只能被一個客戶端訪問;根據鎖用途分為以下兩種:
- 共享資源只允許一個客戶端操作
- 共享資源允許多個客戶端操作
僅允許一個客戶端訪問:共享資源的操作不具備冪等性。常見于數據的修改、刪除操作。
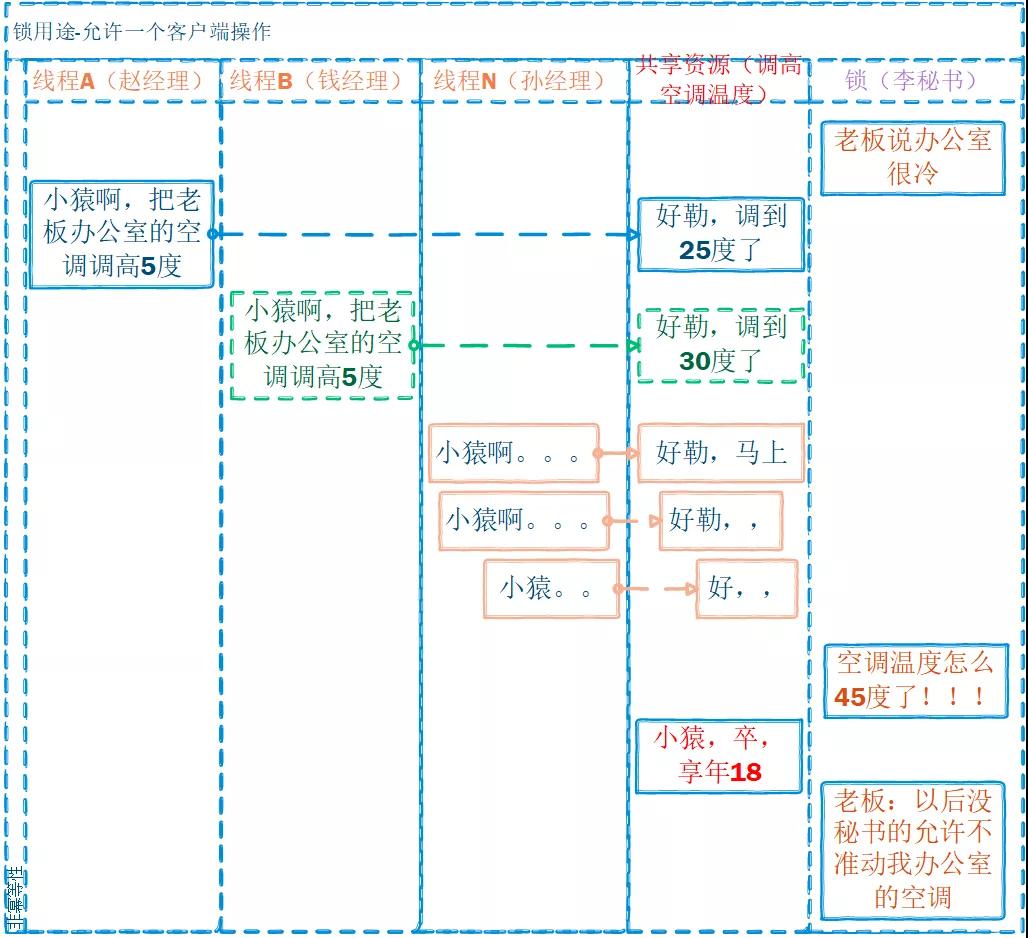
在上面的例子中:

允許多個客戶端操作:主要應用場景是共享資源的操作具有冪等性;如數據的查詢。
既然都具有冪等性了,為什么還需要分布式鎖呢,通常是為了效率或性能,避免重復操作(尤其是消耗資源的操作)。
例如我們常見的緩存方案:
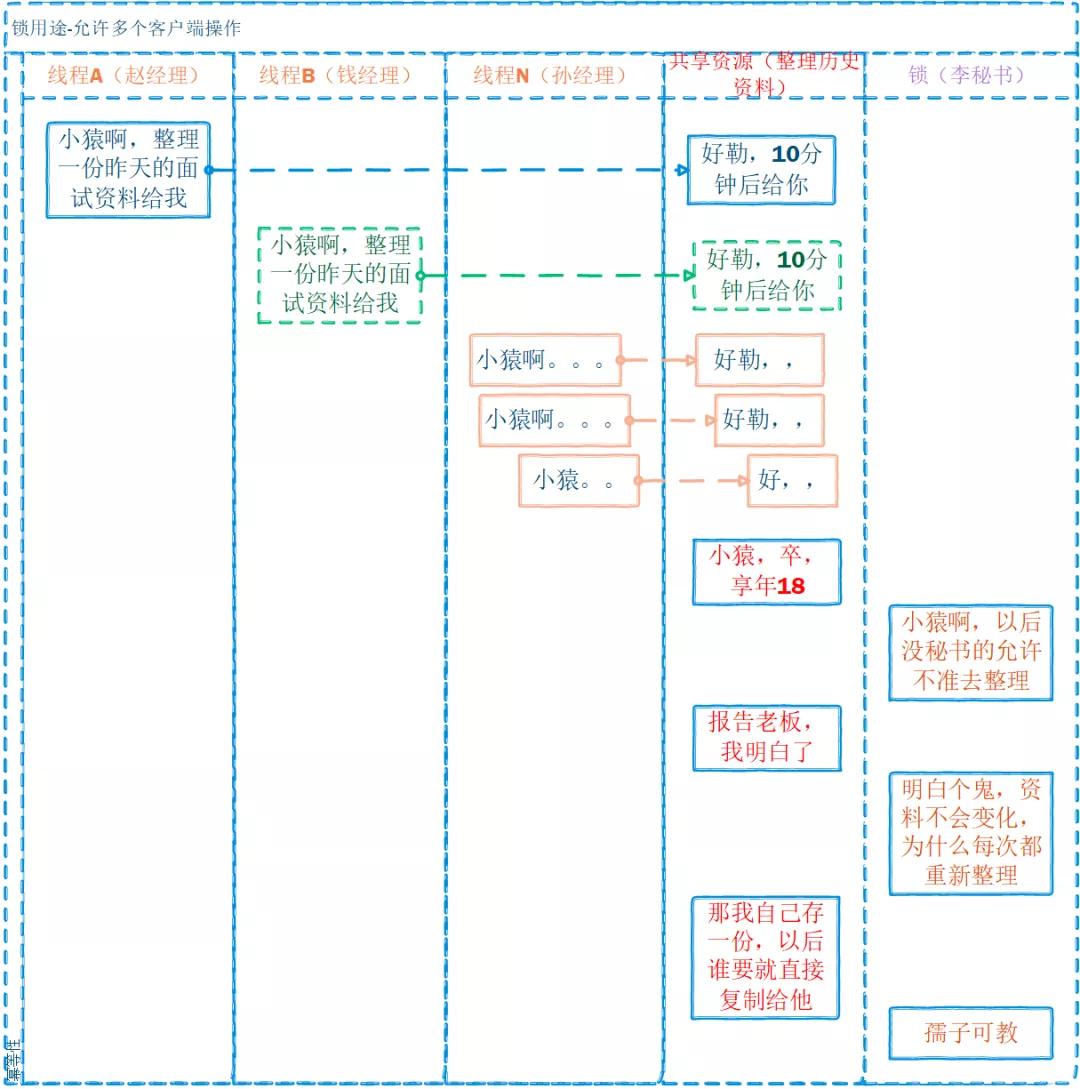
在上面的例子中:
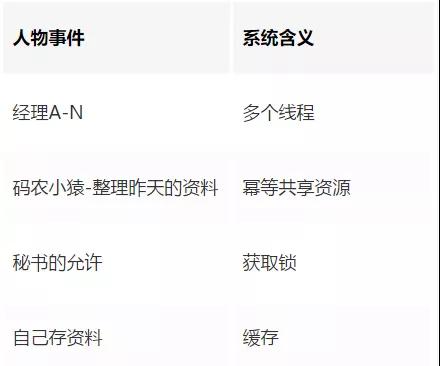
由于此處的資源是冪等的,通常會將這類資源做緩存,這就是常見的鎖+緩存架構。
常適用于獲取較為消耗資源(時間、內存、CPU 等)的冪等資源,如:
- 查詢用戶信息
- 查詢歷史訂單
當然,如果資源僅在一段時間范圍內具有冪等性,這時候,架構就應該升級了:
鎖+緩存+緩存失效/失效重新獲取/緩存定時更新。
②鎖為什么需要分布式的?
還是以上面的緩存方案為例,此處略作變化:
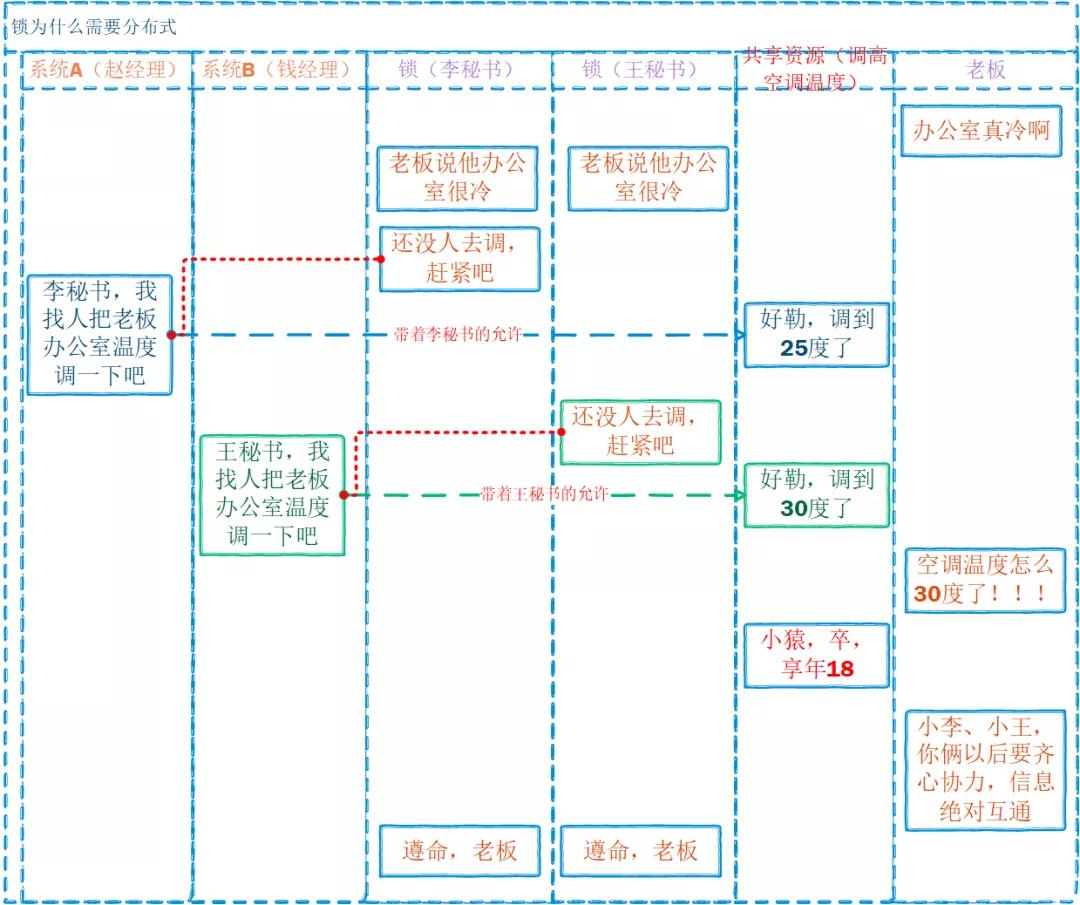
在上面的例子中:
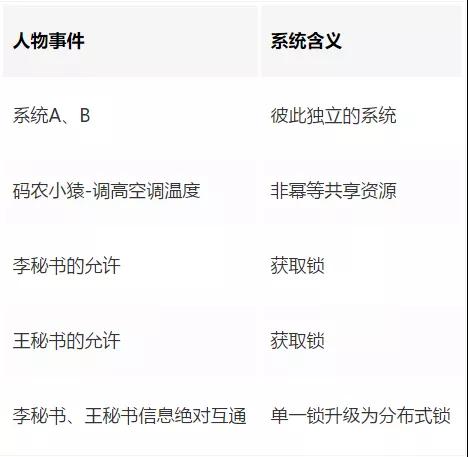
分布式鎖有哪些特點?
①互斥性
在任意時刻,僅允許有一個客戶端獲得鎖。
PS:如果多個客戶端都能同時獲得鎖,那鎖就沒意義了,共享資源的安全性也就無法保證了。
老板:當我在會議室接待客戶 A 時,其他客戶只有等待,你需要等到我空閑了才能把其他人帶到我辦公室。
小猿:明白。
接待客戶(非冪等共享資源);等到老板空閑(獲取鎖)。
②可重入性
客戶端 A 獲得了鎖,只要鎖沒有過期,客戶端 A 可以繼續獲得該鎖。鎖在我這里,我還要繼續使用,其他人不準搶。
這種特性可以很好的支持【鎖續約】功能。例如:客戶端 A 獲取鎖,鎖釋放時間為 10S,即將到達 10S 時,客戶端 A 未完成任務,需要再申請 5S。若鎖沒有可重入性,客戶端 A 將無法續約,導致鎖可能被其他客戶端搶走。
小猿:受教了,老板 3 分鐘后你還有一場面試。
老板:小猿啊,難得你這么好學,我很欣慰,我們的交流時間延10分鐘吧,其他會議延后。
③高性能
獲取鎖的效率應該足夠高;總不能讓業務阻塞在獲取鎖上面吧?
小猿:好的,我已在釘釘申請將會議延長 10 分鐘了。
老板:嗯,我已經接受會議邀請了;
小猿:老板你真高效。
④高可用
分布式、微服務環境下,必須保證服務的高可用,否則輕則影響其他業務模塊,重則引發服務雪崩。
老板:我手機 24 小時開機,有會議時聯系不上我也可以聯系我秘書。
⑤支持阻塞和非阻塞式鎖
獲取鎖失敗,是直接返回失敗,還是一直阻塞知道獲取成功?不同的業務場景有不同的答案。
例如:

⑥解鎖權限
客戶端僅能釋放(解鎖)自己加的鎖。常見的解決方案是,給鎖加隨機數(或 ThreadID)。
老板:小猿啊,給你講了這么多,都明白了嗎?
籠子里的鸚鵡:明白啦,明白啦。
老板:閉嘴,我問的是小猿,只有小猿自己有資格回答。
⑦避免死鎖
加鎖方異常終止無法主動釋放鎖;常規做法是 加鎖時設置超時時間,如果未主動釋放鎖,則利用 Redis 的自動過期被動釋放鎖。
秘書破門而入:老板,你們 10 分鐘的會議已經到點了,隔壁的李總已經等不及了。
老板:一不留神就忘記時間了,我得去見李總了。
小猿:老板,我們還沒聊完呢...
⑧異常處理
常見的異常情況有 Redis 宕機、時鐘跳躍、網絡故障等。
小猿:不管出現哪種情況,我獲取鎖都會失敗啊,這可怎么辦呢?
PS:這就復雜了,需要根據具體的業務場景分析。對于必須同步處理的業務,則必須失敗告警,對于允許延遲處理的業務可以考慮記錄失敗信息待其他系統處理。
分布式鎖流行算法
基本方案 SETNX
基于 Redis 的 SETNX 指令完成鎖的獲取。
①獲取鎖 SET lock:resource_name random_value NX PX 30000
lock:resource_name:資源名字,加鎖對象的唯一標記。
random_value:通常存儲加鎖方的唯一標記,如“UUID+ThreadID”。
NX:Key 不存在才設置,即鎖未被其他人加鎖才能加鎖。
PX:鎖超時時間。
當然,此種加鎖方式是不支持“鎖重入性”的。
②釋放鎖(LUA 腳本)
checkValueThenDelete:檢查解鎖方是否是加鎖方,是則允許解鎖,否則不允許解鎖。
偽代碼是:
- public class RedisTool {
- // 釋放鎖成功標記
- private static final Long RELEASE_LOCK_SUCCESS = 1L;
- /**
- * 釋放分布式鎖
- *
- * @param jedis Redis客戶端
- * @param lockKey 鎖標記
- * @param lockValue 加鎖方標記
- * @return 是否釋放成功
- */
- public static boolean releaseDistributedLock(Jedis jedis, String lockKey, String lockValue) {
- String script = "" +
- "if redis.call('get', KEYS[1]) == ARGV[1] then" +
- " return redis.call('del', KEYS[1]) " +
- "else" +
- " return 0 " +
- "end";
- // Collections.singletonList():用于只有一個元素的場景,減少內存分配
- Object result = jedis.eval(script, Collections.singletonList(lockKey), Collections.singletonList(lockValue));
- if (RELEASE_LOCK_SUCCESS.equals(result)) {
- return true;
- }
- return false;
- }
- }
Redlock 算法
此算法由 Redis 作者 antirez 提出,作為一種分布式場景下的鎖實現方案。
Redlock 算法原理:【核心】大多數節點獲取鎖成功且鎖依舊有效。
Step 1:獲取當前時間(毫秒數)。
Step 2:按序想 N 個 Redis 節點獲取鎖。設置隨機字符串 random_value;設置鎖過期時間:
- Note 1:獲取鎖需設置超時時間(防止某個節點不可用),且 timeout 應遠小于鎖有效時間(幾十毫秒級)。
- Note 2:某節點獲取鎖失敗后,立即向下一個節點獲取鎖(任何類型失敗,包含該節點上的鎖已被其他客戶端持有)。
Step 3:計算獲取鎖的總耗時 totalTime。
Step 4:獲取鎖成功。
獲取鎖成功:客戶端從大多數節點(>=N/2+1)成功獲取鎖,且 totalTime 不超過鎖的有效時間。
重新計算鎖有效時間:最初鎖有效時間減 3.1 計算的獲取鎖消耗的時間。
Step 5:獲取鎖失敗。
獲取失敗后應立即向【所有】客戶端發起釋放鎖(Lua 腳本)。
Step 6:釋放鎖。
業務完成后應立即向【所有】客戶端發起釋放鎖(Lua 腳本)。
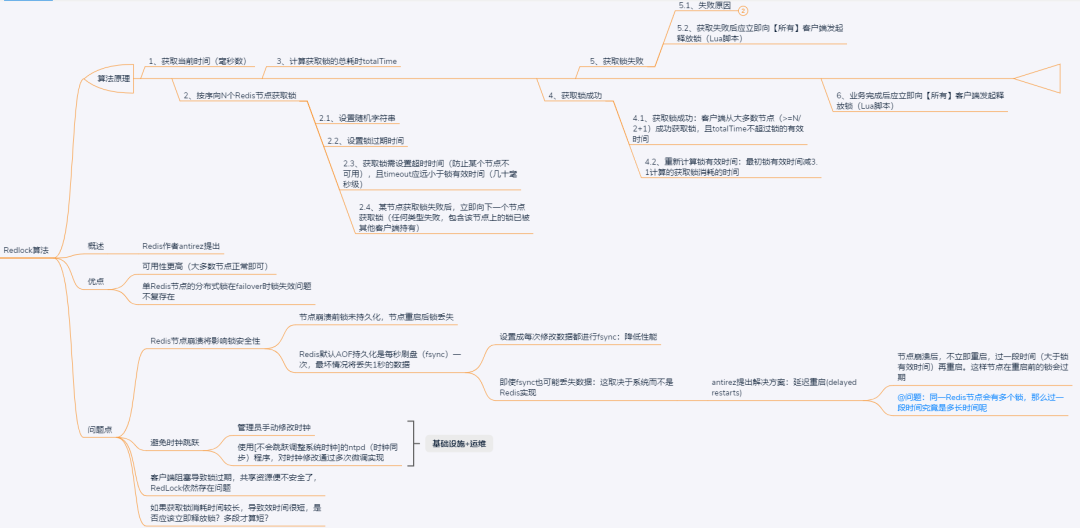
Redlock 算法優點:
- 可用性高,大多數節點正常即可。
- 單 Redis 節點的分布式鎖在 failover 時鎖失效問題不復存在。
Redlock 算法問題點:
- Redis 節點崩潰將影響鎖安全性:節點崩潰前鎖未持久化,節點重啟后鎖將丟失;Redis 默認 AOF 持久化是每秒刷盤(fsync)一次,最壞情況將丟失 1 秒的數據。
- 需避免始終跳躍:管理員手動修改時鐘;使用[不會跳躍調整系統時鐘]的 ntpd(時鐘同步)程序,對時鐘修改通過多次微調實現。
- 客戶端阻塞導致鎖過期,導致共享資源不安全。
- 如果獲取鎖消耗時間較長,導致效時間很短,是否應該立即釋放鎖?多段才算短?
帶 fencing token 的實現
分布式系統專家 Martin Kleppmann 討論提出 RedLock 存在安全性問題。
神仙之戰:Martin Kleppmann 認為 Redis 作者 antirez 提出的 RedLock 算法有安全性問題,雙方在網絡上多輪探討交鋒。
Martin 指出 RedLock 算法的核心問題點如下:
- 鎖過期或者網絡延遲將導致鎖沖突:客戶端 A 進程 pause→鎖過期→客戶端 B 持有鎖→客戶端 A 恢復并向共享資源發起寫請求;網絡延遲也會產生類似效果。
- RedLock 安全性對系統時鐘有強依賴。
fencing token 算法原理:
- fencing token 是一個單調遞增的數字,當客戶端成功獲取鎖時隨同鎖一起返回給客戶端。
- 客戶端訪問共享資源時帶上 token。
- 共享資源服務檢查 token,拒絕延遲到來的請求。
fencing token 算法問題點:
- 需要改造共享資源服務。
- 如果資源服務也是分布式,如何保證 token 在多個資源服務節點遞增。
- 2 個 fencing token 到達資源服務的順序顛倒,服務檢查將異常。
- 【antirez】既然存在 fencing 機制保持資源互斥訪問,為什么還需要分布式鎖且要求強安全性呢。
其他分布式鎖
數據庫排它鎖:
- 獲取鎖(select for update ,悲觀鎖)。
- 處理業務邏輯。
- 釋放鎖(connection.commit())。
注意:InnoDB 引擎在加鎖的時候,只有通過索引進行檢索的時候才會使用行級鎖,否則會使用表級鎖。So 必須給 lock_name 加索引。
ZooKeeper 分布式鎖:
- 客戶端創建 znode 節點,創建成功則獲取鎖成功。
- 持有鎖的客戶端訪問共享資源完成后刪除 znode。
- znode 創建成 ephemeral(znode 特性),保證創建 znode 的客戶端崩潰后,znode 會被自動刪除。
- 【問題】Zookeeper 基于客戶端與 Zookeeper 某臺服務器維護 Session,Session 依賴定期心跳(heartbeat)維持。
Zookeeper 長時間收不到客戶端心跳,就任務 Session 過期,這個 Session 所創建的所有 ephemeral 類型的 znode 節點都將被刪除。
Google 的 Chubby 分布式鎖:
- sequencer 機制(類似 fencing token)緩解延遲導致的問題。
- 鎖持有者可隨時請求一個 sequencer。
- 客戶端操作資源時將 sequencer 傳給資源服務器。
- 資源服務器檢查 sequencer 有效性:①調用 Chubby 的 API(CheckSequencer)檢查。②對比檢查客戶端、資源服務器當前觀察到的 sequencer(類似 fencing token)。③lock-delay:允許客戶端為持有鎖指定一個 lock-delay 延遲時間,Chubby 發現客戶端失去聯系時,在 lock-delay 時間內組織其他客戶端獲取鎖;
總結
我們該使用怎樣的分布式鎖算法?
- 技術都是為業務服務的,避免選擇“高大上”的炫技;
- 依托業務場景,盡可能選擇最簡單的做法;
- 最簡單的分布式鎖導致偶發性異常如何處理呢?建議增加額外的機制甚至人工介入保證業務準確性,通常這部分成本低于復雜的分布式鎖的開發、運維成本。
分布式鎖的另類玩法,“分而治之”經久不衰:
- 如果共享資源本身可以拆分,那就分開處理吧。
- 比如電商系統防止超賣,假設有 10000 個口罩將被秒殺,常規做法是一個鎖控制所有資源。另類玩法就是將 10000 個口罩交由 20 個鎖控制,整體性能瞬間提升幾十倍。
PS:此處超賣僅是舉例,真實場景下的秒殺超賣有更加復雜的場景,慎重。