













PyTorch版EfficientDet比官方TF實(shí)現(xiàn)快25倍?這個(gè)GitHub項(xiàng)目數(shù)天狂攬千星
EfficientDet 難復(fù)現(xiàn),復(fù)現(xiàn)即趟坑。在此 Github 項(xiàng)目中,開發(fā)者 zylo117 開源了 PyTorch 版本的 EfficientDet,速度比原版高 20 余倍。如今,該項(xiàng)目已經(jīng)登上 Github Trending 熱榜。

去年 11 月份,谷歌大腦提出兼顧準(zhǔn)確率和模型效率的新型目標(biāo)檢測(cè)器 EfficientDet,實(shí)現(xiàn)了新的 SOTA 結(jié)果。前不久,該團(tuán)隊(duì)開源了 EfficientDet 的 TensorFlow 實(shí)現(xiàn)代碼。
如此高效的 EfficientDet 還能更高效嗎?最近,有開發(fā)者在 GitHub 上開源了「PyTorch 版本的 EfficientDet」。該版本的性能接近原版,但速度是官方 TensorFlow 實(shí)現(xiàn)的近 26 倍!
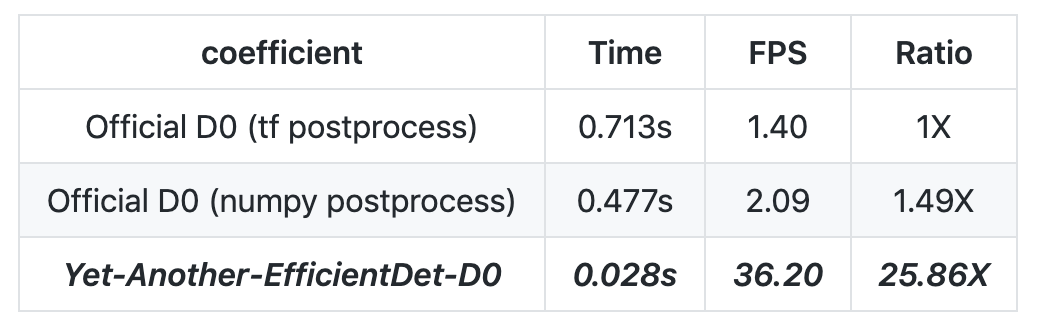
目前,該項(xiàng)目在 GitHub 上獲得了 957 顆星,最近一天的收藏量接近 300。
GitHub 地址:https://github.com/zylo117
EfficientDet 簡介
近年來,在面對(duì)廣泛的資源約束時(shí)(如 3B 到 300B FLOPS),構(gòu)建兼具準(zhǔn)確率和效率的可擴(kuò)展檢測(cè)架構(gòu)成為優(yōu)化目標(biāo)檢測(cè)器的重要問題。基于單階段檢測(cè)器范式,谷歌大腦團(tuán)隊(duì)的研究者查看了主干網(wǎng)絡(luò)、特征融合和邊界框/類別預(yù)測(cè)網(wǎng)絡(luò)的設(shè)計(jì)選擇,發(fā)現(xiàn)了兩大主要挑戰(zhàn)并提出了相應(yīng)的解決方法:
挑戰(zhàn) 1:高效的多尺度特征融合。研究者提出一種簡單高效的加權(quán)雙向特征金字塔網(wǎng)絡(luò)(BiFPN),該模型引入了可學(xué)習(xí)的權(quán)重來學(xué)習(xí)不同輸入特征的重要性,同時(shí)重復(fù)應(yīng)用自上而下和自下而上的多尺度特征融合。
挑戰(zhàn) 2:模型縮放。受近期研究的啟發(fā),研究者提出一種目標(biāo)檢測(cè)器復(fù)合縮放方法,即統(tǒng)一擴(kuò)大所有主干網(wǎng)絡(luò)、特征網(wǎng)絡(luò)、邊界框/類別預(yù)測(cè)網(wǎng)絡(luò)的分辨率/深度/寬度。
谷歌大腦團(tuán)隊(duì)的研究者發(fā)現(xiàn),EfficientNets 的效率超過之前常用的主干網(wǎng)絡(luò)。于是研究者將 EfficientNet 主干網(wǎng)絡(luò)和 BiFPN、復(fù)合縮放結(jié)合起來,開發(fā)出新型目標(biāo)檢測(cè)器 EfficientDet,其準(zhǔn)確率優(yōu)于之前的目標(biāo)檢測(cè)器,同時(shí)參數(shù)量和 FLOPS 比它們少了一個(gè)數(shù)量級(jí)。
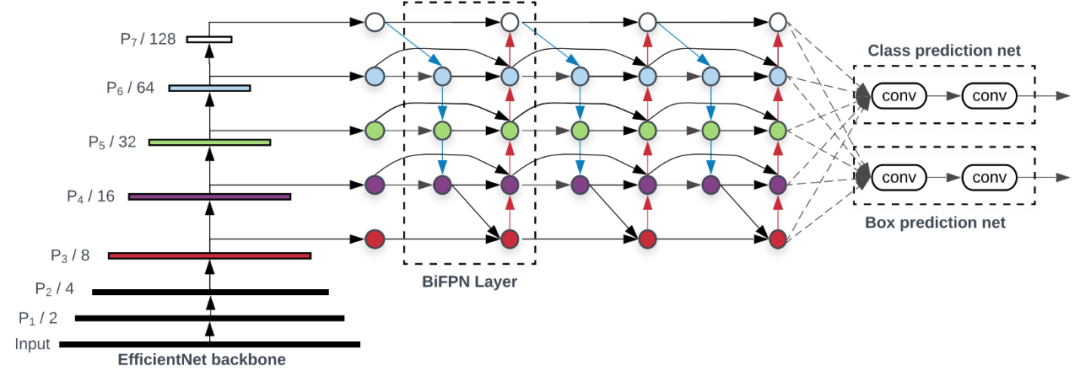
下圖展示了 EfficientDet 的整體架構(gòu),大致遵循單階段檢測(cè)器范式。谷歌大腦團(tuán)隊(duì)的研究者將在 ImageNet 數(shù)據(jù)集上預(yù)訓(xùn)練的 EfficientNet 作為主干網(wǎng)絡(luò),將 BiFPN 作為特征網(wǎng)絡(luò),接受來自主干網(wǎng)絡(luò)的 level 3-7 特征 {P3, P4, P5, P6, P7},并重復(fù)應(yīng)用自上而下和自下而上的雙向特征融合。然后將融合后的特征輸入邊界框/類別預(yù)測(cè)網(wǎng)絡(luò),分別輸出目標(biāo)類別和邊界框預(yù)測(cè)結(jié)果。
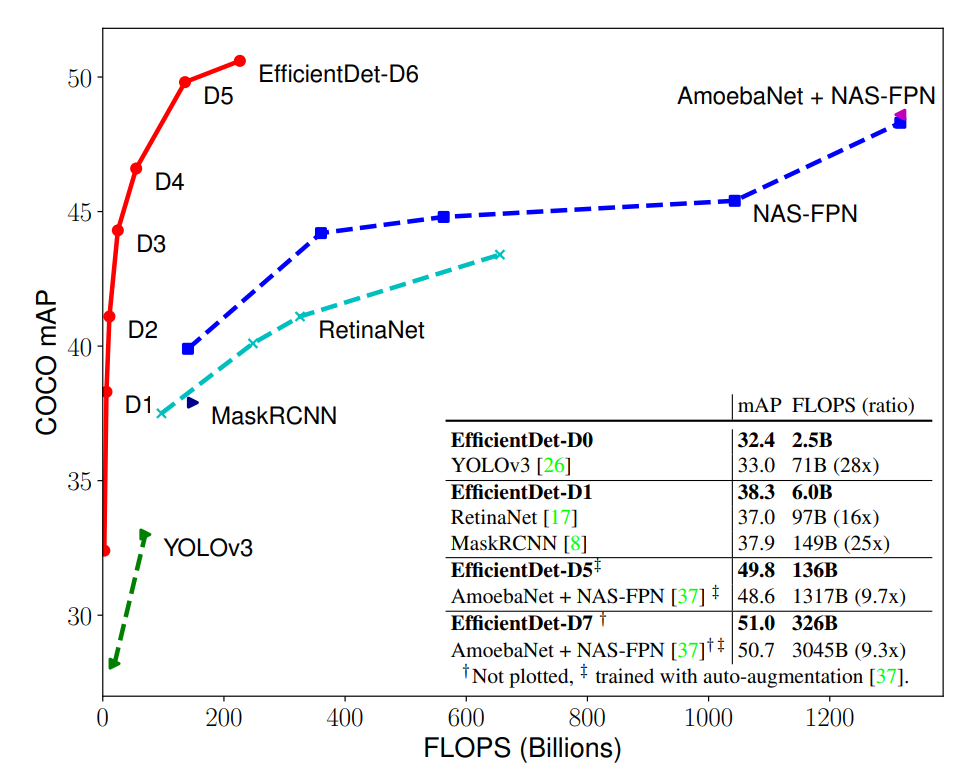
下圖展示了多個(gè)模型在 COCO 數(shù)據(jù)集上的性能對(duì)比情況。在類似的準(zhǔn)確率限制下,EfficientDet 的 FLOPS 僅為 YOLOv3 的 1/28、RetinaNet 的 1/30、NASFPN 的 1/19,所有數(shù)字均為單個(gè)模型在單一尺度下所得。可以看到,EfficientDet 的計(jì)算量較其他檢測(cè)器少,但準(zhǔn)確率優(yōu)于后者,其中 EfficientDet-D7 獲得了當(dāng)前最優(yōu)性能。
更詳細(xì)的介紹,可參見機(jī)器之心文章:比當(dāng)前 SOTA 小 4 倍、計(jì)算量少 9 倍,谷歌最新目標(biāo)檢測(cè)器 EfficientDet
「宅」是第一生產(chǎn)力
項(xiàng)目作者今年 1 月宅家為國出力時(shí),開始陸續(xù)嘗試各類 EfficientDet PyTorch 版實(shí)現(xiàn),期間趟過了不少坑,也流過幾把辛酸淚。但最終得出了非常不錯(cuò)的效果,也是全網(wǎng)第一個(gè)跑出接近論文成績的 PyTorch 版。
我們先來看一下項(xiàng)目作者與 EfficientDet 官方提供代碼的測(cè)試效果對(duì)比。第一張圖為官方代碼的檢測(cè)效果,第二張為項(xiàng)目作者的檢測(cè)效果。項(xiàng)目作者的實(shí)現(xiàn)竟然透過汽車的前擋風(fēng)玻璃檢測(cè)出了車輛里面的人?!!這樣驚艷的檢測(cè)效果不愧是目前 EfficientDet 的霸榜存在。

接下來我們來看一下 coco 數(shù)據(jù)集上目標(biāo)檢測(cè)算法的排名,多個(gè)屠榜的目標(biāo)檢測(cè)網(wǎng)絡(luò)基于 EfficientDet 構(gòu)建。一圖以言之:
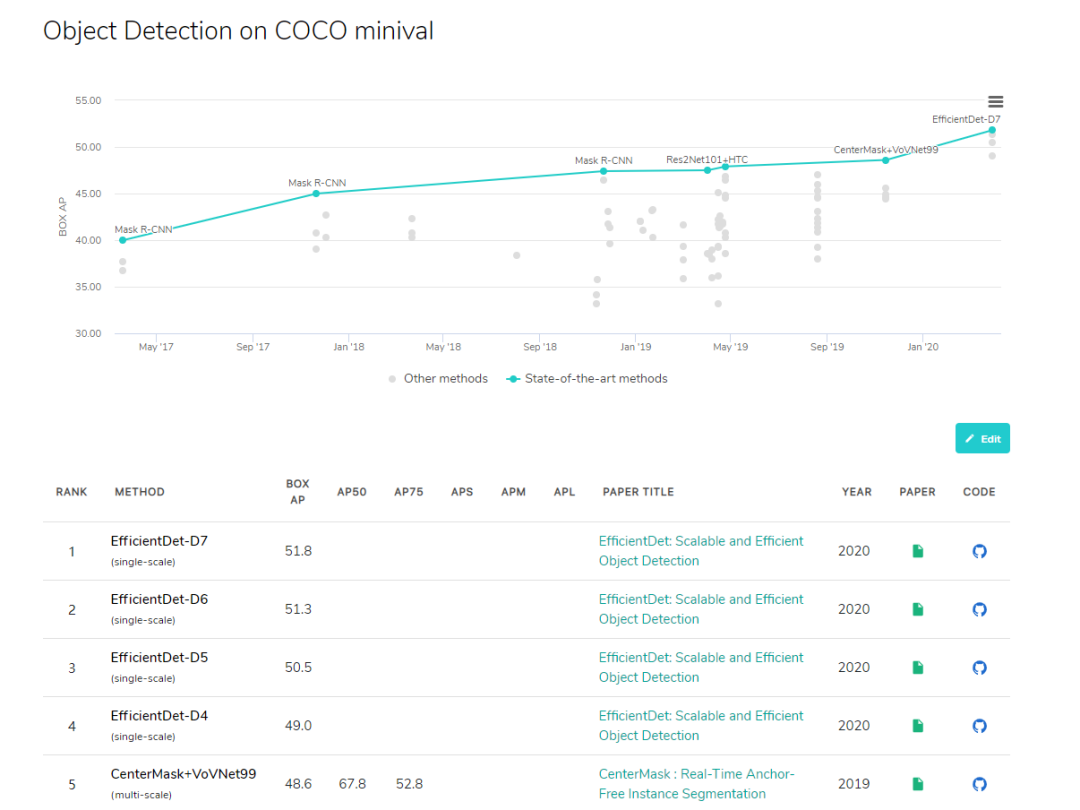
來自 paperswithcode
前五里包攬前四,屠榜之勢(shì)不言而喻,也難怪各類煉金術(shù)士們躍躍欲試。但是,EfficientDet 的實(shí)現(xiàn)難度貌似與其知名度「成正比」,眾煉金師紛紛表示「難訓(xùn)練」「至今未訓(xùn)練好」「誰復(fù)現(xiàn)誰被坑」。項(xiàng)目作者也表示「由于谷歌一直不發(fā)官方 repository,所以只能民間發(fā)力,那些靠 paper 的內(nèi)容實(shí)現(xiàn)出來的真的不容易」。
假期三天,拿下 PyTorch 版 EfficientDet D0 到 D7
項(xiàng)目作者復(fù)現(xiàn)結(jié)果與論文中并沒完全一致,但相較于其他同類復(fù)現(xiàn)項(xiàng)目來說,稱的上是非常接近了(詳細(xì)信息可參考項(xiàng)目鏈接)。
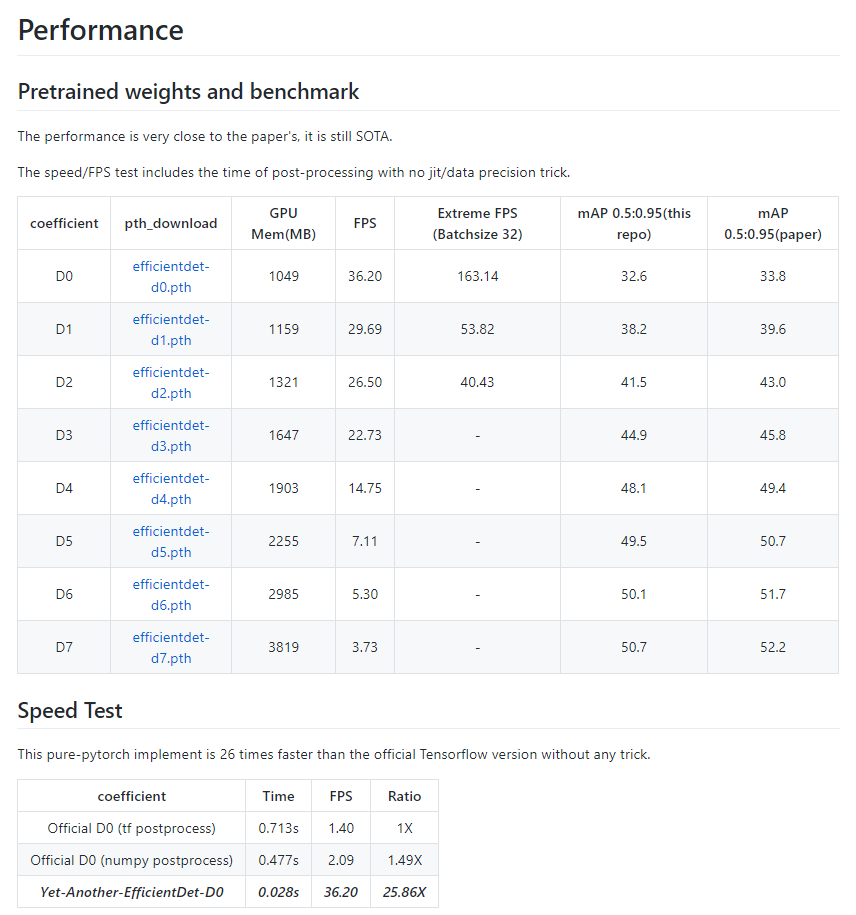
值得注意的是,此次項(xiàng)目處理速度比原版快了 20 余倍。
那么為什么之前都沒有人復(fù)現(xiàn) EfficientDet 的成績?具體哪些細(xì)節(jié)需要注意?
「民間」EfficientDet 的取舍
作者前后試用了兩個(gè) GitHub 項(xiàng)目進(jìn)行實(shí)現(xiàn),但效果并不理想。首先采用的 star 量最高的一個(gè),同時(shí)可能也說明了一點(diǎn),不是 star 越高就越適合。
針對(duì)第一個(gè)項(xiàng)目,作者表示:「因?yàn)?EfficientDet 的特性之一是 BiFPN,它會(huì)融合 backbone 輸出的任意相鄰兩層的 feature,但是由于有兩層尺寸的寬高是不同的,所以會(huì)進(jìn)行 upsample 或者 pooling 來保證它們寬高一致。而這個(gè)作者沒有意識(shí)到,他不知道從 backbone 抽哪些 feature 出來,他覺得是 backbone 有問題,改了人家的 stride,隨便挑了幾層,去強(qiáng)迫 backbone 輸出他想要的尺寸」
「改了網(wǎng)絡(luò)結(jié)構(gòu),pretrained 權(quán)值基本就廢了,所以作者也發(fā)現(xiàn)了,發(fā)現(xiàn)訓(xùn)練不下去了」。至此第一個(gè)項(xiàng)目畫上句號(hào),同時(shí)作者提供了官方參數(shù)與試用項(xiàng)目作者改后的參數(shù)對(duì)比鏈接,有興趣的朋友可瀏覽參考鏈接。
而面向第二個(gè)項(xiàng)目,雖然 star 不及前者一半,但顯然可靠度更甚前者。作者表示,第二個(gè)項(xiàng)目起碼在 D0 上有論文成績的支撐,同時(shí) repo 也提供了 coco 的 pretrained 權(quán)值 31.4mAP。然而實(shí)操后作者得到 24mAP,同時(shí)社區(qū)普遍也在 20-22 范圍中。
那么此次結(jié)果的原因是什么?作者經(jīng)過反復(fù)的思考檢測(cè),得到以下 7 點(diǎn)總結(jié),并就此 7 點(diǎn)復(fù)盤進(jìn)行適當(dāng)?shù)谜{(diào)整,得到了當(dāng)前項(xiàng)目不錯(cuò)的效果。
一波三折后的答案
針對(duì)第二個(gè)測(cè)試項(xiàng)目的復(fù)盤,作者表示一共有 7 個(gè)關(guān)鍵點(diǎn)需要額外注意:
- 第二個(gè)項(xiàng)目的 BN 實(shí)現(xiàn)有問題:BatchNorm 是有一個(gè)參數(shù),叫做 momentum,用來調(diào)整新舊均值的比例,從而調(diào)整移動(dòng)平均值的計(jì)算方式的。
- Depthwise-Separatable Conv2D 的錯(cuò)誤實(shí)現(xiàn)。
- 誤解了 maxpool2d 的參數(shù),kernel_size 和 stride。
- 減少通道的卷積后面,沒有進(jìn)行 BN
- backbone feature 抽頭抽錯(cuò)了
- Conv 和 pooling,沒有用到 same padding
- 沒有能正確的理解 BiFPN 的流程

來源于項(xiàng)目作者知乎賬號(hào),詳情請(qǐng)見參考鏈接
作者還表示,其中有個(gè)非常關(guān)鍵點(diǎn),「雞賊的官方并沒有表示這里是兩個(gè)獨(dú)立的 P4_0」。
簡而言之,這篇知乎博客非常詳細(xì)的介紹了各種復(fù)現(xiàn)注意事項(xiàng),細(xì)節(jié)在此不再一一贅述。筆者認(rèn)為對(duì)各煉金術(shù)師有一定參考價(jià)值,感興趣的可以直接查看原文博客。
同時(shí),機(jī)器之心對(duì)此項(xiàng)目也進(jìn)行了實(shí)測(cè)。
項(xiàng)目實(shí)測(cè)
測(cè)試
我們?cè)?P100 GPU,Ubuntu 18.04 系統(tǒng)下對(duì)本項(xiàng)目進(jìn)行了測(cè)試。
首先將項(xiàng)目克隆到本地,并切換到相關(guān)目錄下:
- !git clone https://github.com/zylo117/Yet-Another-EfficientDet-Pytorch
- import os
- os.chdir('Yet-Another-EfficientDet-Pytorch')
安裝如下依賴環(huán)境:
- !pip install pycocotools numpy opencv-python tqdm tensorboard tensorboardX pyyaml
- !pip install torch==1.4.0
- !pip install torchvision==0.5.0
項(xiàng)目作者為我們提供了用于推斷測(cè)試的 Python 腳本 efficientdet_test.py,該腳本會(huì)讀取 weights 文件夾下保存的網(wǎng)絡(luò)權(quán)重,并對(duì) test 文件夾中的圖片進(jìn)行推斷,之后將檢測(cè)結(jié)果保存到同一文件夾下。首先,我們使用如下命令下載預(yù)訓(xùn)練模型:
- !mkdir weights
- os.chdir('weights')
- !wget https://github.com/zylo117/Yet-Another-Efficient-Pytorch/releases/download/1.0/efficientdet-d0.pth
之后把需要檢測(cè)的圖片放在 test 文件夾下,這里別忘了還要把 efficientdet_test.py 中對(duì)應(yīng)的圖像名稱修改為我們想要檢測(cè)圖片的名稱,運(yùn)行 efficientdet_test.py 腳本即可檢測(cè)圖片中的物體,輸出結(jié)果如下:

我們先用曾經(jīng)爆火的共享單車,現(xiàn)如今倒了一大片淪為「共享單車墳場(chǎng)」測(cè)試一下效果如何。下圖分別為原圖與使用本項(xiàng)目的檢測(cè)結(jié)果。


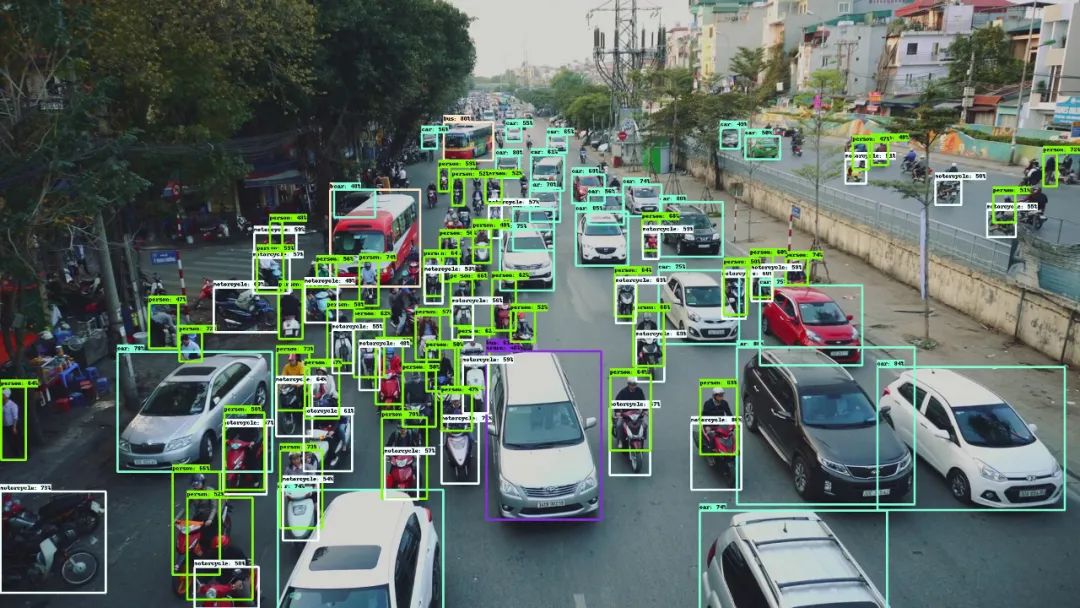
效果很不錯(cuò),圖片中的人與密密麻麻、橫七豎八擺放的共享單車大多都檢測(cè)了出來。接下來我們用一張國內(nèi)常見的堵車場(chǎng)景來測(cè)試一下,車輛、非機(jī)動(dòng)車、行人交錯(cuò)出現(xiàn)在畫面中,可以說是非常復(fù)雜的場(chǎng)景了。從檢測(cè)結(jié)果可以看出,基本上所有的行人、車輛、背包、袋子等物體都較好地檢測(cè)了出來。


最后當(dāng)然要在「開掛民族」坐火車的場(chǎng)景下測(cè)試一番,密集恐懼癥慎入。雖然把旗子檢測(cè)成了風(fēng)箏(很多目標(biāo)檢測(cè)算法都容易出現(xiàn)這樣的問題),但總體來說檢測(cè)效果可以說是非常驚艷的。它檢測(cè)出了圖片中大部分的人物,和機(jī)器之心此前報(bào)道過的高精度人臉檢測(cè)方法-DBFace 的準(zhǔn)確率有得一拼。需要注意的是,DBFace 是專用于人臉檢測(cè)的方法,而本項(xiàng)目實(shí)現(xiàn)的是通用物體檢測(cè)。

訓(xùn)練
項(xiàng)目作者同時(shí)也提供了訓(xùn)練 EfficientDet 相關(guān)的代碼。我們只需要準(zhǔn)備好訓(xùn)練數(shù)據(jù)集,設(shè)置好類似于如下代碼所示的訓(xùn)練參數(shù),運(yùn)行 train.py 即可進(jìn)行訓(xùn)練。
- # create a yml file {your_project_name}.yml under 'projects'folder
- # modify it following 'coco.yml'
- # for example
- project_name: coco
- train_set: train2017
- val_set: val2017
- num_gpus: 4 # 0 means using cpu, 1-N means using gpus
- # mean and std in RGB order, actually this part should remain unchanged as long as your dataset is similar to coco.
- mean: [0.485, 0.456, 0.406]
- std: [0.229, 0.224, 0.225]
- # this is coco anchors, change it if necessary
- anchors_scales: '[2 ** 0, 2 ** (1.0 / 3.0), 2 ** (2.0 / 3.0)]'
- anchors_ratios: '[(1.0, 1.0), (1.4, 0.7), (0.7, 1.4)]'
- # objects from all labels from your dataset with the order from your annotations.
- # its index must match your dataset's category_id.
- # category_id is one_indexed,
- # for example, index of 'car' here is 2, while category_id of is 3
- obj_list: ['person', 'bicycle', 'car', ...]
在 coco 數(shù)據(jù)集上訓(xùn)練代碼如下:
- # train efficientdet-d0 on coco from scratch
- # with batchsize 12
- # This takes time and requires change
- # of hyperparameters every few hours.
- # If you have months to kill, do it.
- # It's not like someone going to achieve
- # better score than the one in the paper.
- # The first few epoches will be rather unstable,
- # it's quite normal when you train from scratch.
- python train.py -c 0 --batch_size 12
在自定義數(shù)據(jù)集上訓(xùn)練:
- # train efficientdet-d1 on a custom dataset
- # with batchsize 8 and learning rate 1e-5
- python train.py -c 1 --batch_size 8 --lr 1e-5
項(xiàng)目作者強(qiáng)烈推薦在預(yù)訓(xùn)練的權(quán)重上對(duì)網(wǎng)絡(luò)進(jìn)行訓(xùn)練:
- # train efficientdet-d2 on a custom dataset with pretrained weights
- # with batchsize 8 and learning rate 1e-5 for 10 epoches
- python train.py -c 2 --batch_size 8 --lr 1e-5 --num_epochs 10
- --load_weights /path/to/your/weights/efficientdet-d2.pth
- # with a coco-pretrained, you can even freeze the backbone and train heads only
- # to speed up training and help convergence.
- python train.py -c 2 --batch_size 8 --lr 1e-5 --num_epochs 10
- --load_weights /path/to/your/weights/efficientdet-d2.pth
- --head_only True
【編輯推薦】

























