三年之久的 etcd3 數(shù)據(jù)不一致 bug 分析
etcd 作為 Kubernetes 集群的元數(shù)據(jù)存儲,是被業(yè)界廣泛使用的強一致性 KV 存儲,但近日被挖掘出一個存在 3 年之久的數(shù)據(jù)不一致 bug——client 寫入后無法在異常節(jié)點讀取到數(shù)據(jù),即數(shù)據(jù)丟失。本文介紹了我們是如何從問題分析、大膽猜測、嚴謹驗證、排除、工程化復現(xiàn),從 raft 到 boltdb,從源碼定制再到 chaos monkey,一步步定位并解決 etcd 數(shù)據(jù)不一致 bug 的詳細流程,并將解決方案提交給社區(qū),移植到 etcd 3.4/3.3 生產(chǎn)環(huán)境分支。希望通過本文,能夠揭開 etcd 的神秘面紗,讓大家對 etcd 的原理和問題定位有一個較為深入的了解。
問題背景
詭異的 K8S 滾動更新異常
筆者某天收到同事反饋,測試環(huán)境中 K8S 集群進行滾動更新發(fā)布時未生效。通過 kube-apiserver 查看發(fā)現(xiàn),對應的 Deployment 版本已經(jīng)是最新版,但是這個最新版本的 Pod 并未創(chuàng)建出來。
針對該現(xiàn)象,我們最開始猜測可能是 kube-controller-manager 的 bug 導致,但是觀察 controller-manager 日志并未發(fā)現(xiàn)明顯異常。第一次調高 controller-manager 的日志等級并進行重啟操作之后,似乎由于 controller-manager 并沒有 watch 到這個更新事件,我們仍然沒有發(fā)現(xiàn)問題所在。此時,觀察 kube-apiserver 日志,同樣也沒有出現(xiàn)明顯異常。
于是,再次調高日志等級并重啟 kube-apiserver,詭異的事情發(fā)生了,之前的 Deployment 正常滾動更新了!
etcd 數(shù)據(jù)不一致 ?
由于從 kube-apiserver 的日志中同樣無法提取出能夠幫助解決問題的有用信息,起初我們只能猜測可能是 kube-apiserver 的緩存更新異常導致的。正當我們要從這個切入點去解決問題時,該同事反饋了一個更詭異的問題——自己新創(chuàng)建的 Pod,通過 kubectl查詢 Pod 列表,突然消失了!納尼?這是什么騷操作?經(jīng)過我們多次測試查詢發(fā)現(xiàn),通過 kubectl 來 list pod 列表,該 pod 有時候能查到,有時候查不到。那么問題來了,K8s api 的 list 操作是沒有緩存的,數(shù)據(jù)是 kube-apiserver 直接從 etcd 拉取返回給客戶端的,難道是 etcd 本身出了問題?
眾所周知,etcd 本身是一個強一致性的 KV 存儲,在寫操作成功的情況下,兩次讀請求不應該讀取到不一樣的數(shù)據(jù)。懷著不信邪的態(tài)度,我們通過 etcdctl 直接查詢了 etcd 集群狀態(tài)和集群數(shù)據(jù),返回結果顯示 3 個節(jié)點狀態(tài)都正常,且 RaftIndex 一致,觀察 etcd 的日志也并未發(fā)現(xiàn)報錯信息,唯一可疑的地方是 3 個節(jié)點的 dbsize 差別較大。接著,我們又將 client 訪問的 endpoint 指定為不同節(jié)點地址來查詢每個節(jié)點的 key 的數(shù)量,結果發(fā)現(xiàn) 3 個節(jié)點返回的 key 的數(shù)量不一致,甚至兩個不同節(jié)點上 Key 的數(shù)量差最大可達到幾千!而直接通過 etcdctl 查詢剛才創(chuàng)建的 Pod,發(fā)現(xiàn)訪問某些 endpoint 能夠查詢到該 pod,而訪問其他 endpoint 則查不到。至此,基本可以確定 etcd 集群的節(jié)點之間確實存在數(shù)據(jù)不一致現(xiàn)象。
問題分析和排查過程
遇事不決問Google
強一致性的存儲突然數(shù)據(jù)不一致了,這么嚴重的問題,想必日志里肯定會有所體現(xiàn)。然而,可能是 etcd 開發(fā)者擔心日志太多會影響性能的緣故,etcd 的日志打印的比較少,以至于我們排查了 etcd 各個節(jié)點的日志,也沒有發(fā)現(xiàn)有用的報錯日志。甚至是在我們調高日志級別之后,仍沒有發(fā)現(xiàn)異常信息。
作為一個21世紀的程序員,遇到這種詭異且暫時沒頭緒的問題,第一反應當然是先 Google 一下啦,畢竟不會 StackOverFlow 的程序員不是好運維!Google 輸入“etcd data inconsistent” 搜索發(fā)現(xiàn),并不是只有我們遇到過該問題,之前也有其他人向 etcd 社區(qū)反饋過類似問題,只是苦于沒有提供穩(wěn)定的復現(xiàn)方式,最后都不了了之。如 issue
- https://github.com/etcd-io/etcd/issues/9630
- https://github.com/etcd-io/etcd/issues/10407
- https://github.com/etcd-io/etcd/issues/10594
- https://github.com/etcd-io/etcd/issues/11643
由于這個問題比較嚴重,會影響到數(shù)據(jù)的一致性,而我們生產(chǎn)環(huán)境中當前使用了數(shù)百套 etcd 集群,為了避免出現(xiàn)類似問題,我們決定深入定位一番。
etcd 工作原理和術語簡介
在開始之前,為方便讀者理解,這里先簡單介紹下 etcd 的常用術語和基本讀寫原理。
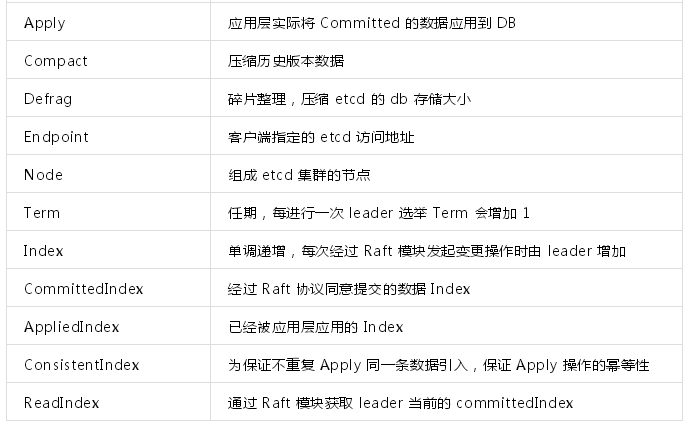
術語表:

etcd 是一個強一致性的分布式 KV 存儲,所謂強一致性,簡單來說就是一個寫操作成功后,從任何一個節(jié)點讀出來的數(shù)據(jù)都是最新值,而不會出現(xiàn)寫數(shù)據(jù)成功后讀不出來或者讀到舊數(shù)據(jù)的情況。etcd 通過 raft 協(xié)議來實現(xiàn) leader 選舉、配置變更以及保證數(shù)據(jù)讀寫的一致性。下面簡單介紹下 etcd 的讀寫流程:
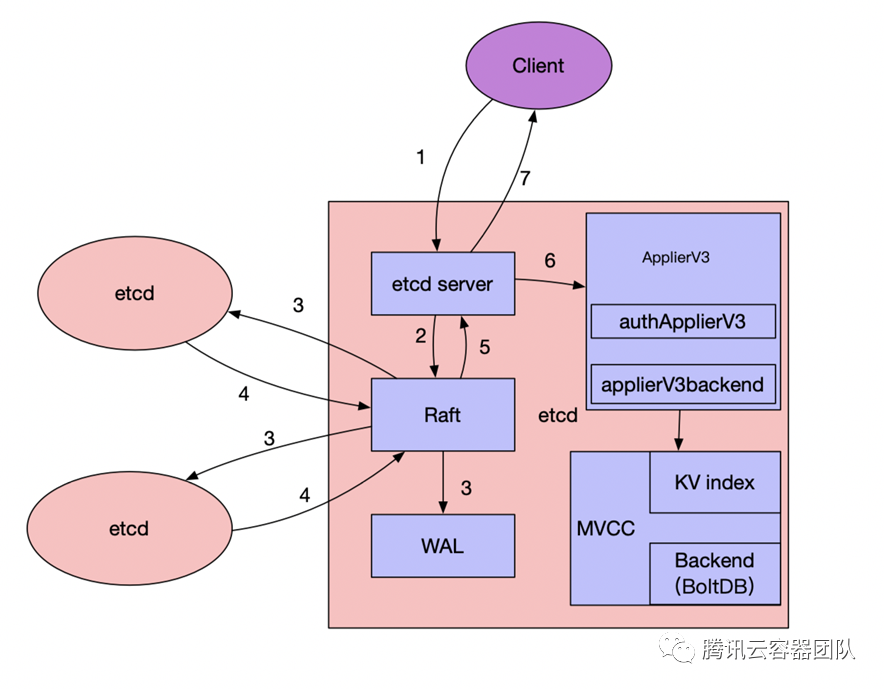
寫數(shù)據(jù)流程(以 leader 節(jié)點為例,見上圖):
- etcd 任一節(jié)點的 etcd server 模塊收到 Client 寫請求(如果是 follower 節(jié)點,會先通過 Raft 模塊將請求轉發(fā)至 leader 節(jié)點處理)。
- etcd server 將請求封裝為 Raft 請求,然后提交給 Raft 模塊處理。
- leader 通過 Raft 協(xié)議與集群中 follower 節(jié)點進行交互,將消息復制到follower 節(jié)點,于此同時,并行將日志持久化到 WAL。
- follower 節(jié)點對該請求進行響應,回復自己是否同意該請求。
- 當集群中超過半數(shù)節(jié)點((n/2)+1 members )同意接收這條日志數(shù)據(jù)時,表示該請求可以被Commit,Raft 模塊通知 etcd server 該日志數(shù)據(jù)已經(jīng) Commit,可以進行 Apply。
- 各個節(jié)點的 etcd server 的 applierV3 模塊異步進行 Apply 操作,并通過 MVCC 模塊寫入后端存儲 BoltDB。
- 當 client 所連接的節(jié)點數(shù)據(jù) apply 成功后,會返回給客戶端 apply 的結果。
讀數(shù)據(jù)流程:
- etcd 任一節(jié)點的 etcd server 模塊收到客戶端讀請求(Range 請求)
- 判斷讀請求類型,如果是串行化讀(serializable)則直接進入 Apply 流程
- 如果是線性一致性讀(linearizable),則進入 Raft 模塊
- Raft 模塊向 leader 發(fā)出 ReadIndex 請求,獲取當前集群已經(jīng)提交的最新數(shù)據(jù) Index
- 等待本地 AppliedIndex 大于或等于 ReadIndex 獲取的 CommittedIndex 時,進入 Apply 流程
- Apply 流程:通過 Key 名從 KV Index 模塊獲取 Key 最新的 Revision,再通過 Revision 從 BoltDB 獲取對應的 Key 和 Value。
初步驗證
通常集群正常運行情況下,如果沒有外部變更的話,一般不會出現(xiàn)這么嚴重的問題。我們查詢故障 etcd 集群近幾天的發(fā)布記錄時發(fā)現(xiàn),故障前一天對該集群進行的一次發(fā)布中,由于之前 dbsize 配置不合理,導致 db 被寫滿,集群無法寫入新的數(shù)據(jù),為此運維人員更新了集群 dbsize 和 compaction 相關配置,并重啟了 etcd。重啟后,運維同學繼續(xù)對 etcd 手動執(zhí)行了 compact 和 defrag 操作,來壓縮 db 空間。通過上述場景,我們可以初步判斷出以下幾個可疑的觸發(fā)條件:
- dbsize 滿
- dbsize 和 compaction 配置更新
- compaction 操作和 defrag 操作
- 重啟 etcd
出了問題肯定要能夠復現(xiàn)才更有利于解決問題,正所謂能夠復現(xiàn)的 bug 就不叫 bug。復現(xiàn)問題之前,我們通過分析 etcd 社區(qū)之前的相關 issue 發(fā)現(xiàn),觸發(fā)該 bug 的共同條件都包含執(zhí)行過 compaction 和 defrag 操作,同時重啟過 etcd 節(jié)點。因此,我們計劃首先嘗試同時模擬這幾個操作,觀察是否能夠在新的環(huán)境中復現(xiàn)。為此我們新建了一個集群,然后通過編寫腳本向集群中不停的寫入和刪除數(shù)據(jù),直到 dbsize 達到一定程度后,對節(jié)點依次進行配置更新和重啟,并觸發(fā) compaction 和 defrag 操作。然而經(jīng)過多次嘗試,我們并沒有復現(xiàn)出類似于上述數(shù)據(jù)不一致的場景。
抽絲剝繭,初現(xiàn)端倪
緊接著,在之后的測試中無意發(fā)現(xiàn),client 指定不同的 endpoint 寫數(shù)據(jù),能夠查到數(shù)據(jù)的節(jié)點也不同。比如,endpoint 指定為 node1 進行寫數(shù)據(jù),3個節(jié)點都可以查到數(shù)據(jù);endpoint 指定為 node2 進行寫數(shù)據(jù),node2 和 node3 可以查到;endpoint 指定為 node3 寫數(shù)據(jù),只有 node3 自己能夠查到。具體情況如下表:
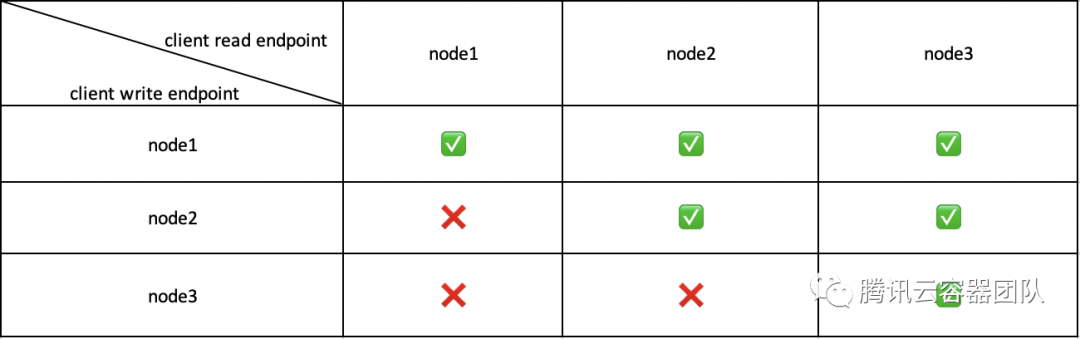
于是我們做出了初步的猜測,有以下幾種可能:
- 集群可能分裂了,leader 未將消息發(fā)送給 follower 節(jié)點。
- leader 給 follower 節(jié)點發(fā)送了消息,但是 log 異常,沒有對應的 command 。
- leader 給 follower 節(jié)點發(fā)送了消息,有對應的 command,但是 apply 異常,操作還未到 KV Index 和 boltdb 就異常了。
- leader 給 follower 節(jié)點發(fā)送了消息, 有對應的 command,但是 apply 異常,KV Index 出現(xiàn)了問題。
- leader 給 follower 節(jié)點發(fā)送了消息, 有對應的 command,但是 apply 異常,boltdb 出現(xiàn)了問題。
為了驗證我們的猜測,我們進行了一系列測試來縮小問題范圍:首先,我們通過 endpoint status 查看集群信息,發(fā)現(xiàn) 3 個節(jié)點的 clusterId,leader,raftTerm,raftIndex 信息均一致,而 dbSize 大小和 revision 信息不一致。clusterId 和 leader 一致,基本排除了集群分裂的猜測,而 raftTerm 和 raftIndex 一致,說明 leader 是有向 follower 同步消息的,也進一步排除了第一個猜測,但是 WAL落盤有沒有異常還不確定。dbSize 和 revision 不一致則進一步說明了 3 個節(jié)點數(shù)據(jù)已經(jīng)發(fā)生不一致了。
其次,由于 etcd 本身提供了一些 dump 工具,例如 etcd-dump-log 和 etcd-dump-db。我們可以像下圖一樣,使用 etcd-dump-log dump 出指定 WAL 文件的內容,使用 etcd-dump-db dump 出 db 文件的數(shù)據(jù),方便對 WAL 和 db 數(shù)據(jù)進行分析。


于是,我們向 node3 寫了一條便于區(qū)分的數(shù)據(jù),然后通過 etcd-dump-log 來分析 3 個節(jié)點的 WAL,按照剛才的測試,endpoint 指定為 node3 寫入的數(shù)據(jù),通過其他兩個節(jié)點應該查不到的。但是我們發(fā)現(xiàn) 3 個節(jié)點都收到了 WAL log,也就是說 WAL 并沒有丟,因此排除了第二個猜測。
接下來我們 dump 了 db 的數(shù)據(jù)進行分析,發(fā)現(xiàn) endpoint 指定為 node3 寫入的數(shù)據(jù),在其他兩個節(jié)點的 db 文件里找不到,也就是說數(shù)據(jù)確實沒有落到 db,而不是寫進去了查不出來。
既然 WAL 里有而 db 里沒有,因此很大可能是 apply 流程異常了,數(shù)據(jù)可能在 apply 時被丟棄了。
由于現(xiàn)有日志無法提供更有效的信息,我們打算在 etcd 里新加一些日志來更好地幫助我們定位問題。etcd 在做 apply 操作時,trace 日志會打印超過每個超過 100ms 的請求,我們首先把 100ms 這個閾值調低,調整到 1ns,這樣每個 apply 的請求都能夠記錄下來,可以更好的幫助我們定位問題。
編譯好新版本之后,我們替換了其中一個 etcd 節(jié)點,然后向不同 node 發(fā)起寫請求測試。果然,我們發(fā)現(xiàn)了一條不同尋常的錯誤日志:"error":"auth:revision in header is old",因此我們斷定問題很可能是因為——發(fā)出這條錯誤日志的節(jié)點,對應的 key 剛好沒有寫進去。
搜索代碼后,我們發(fā)現(xiàn) etcd 在進行 apply 操作時,如果開啟了鑒權,在鑒權時會判斷 raft 請求 header 中的 AuthRevision,如果請求中的 AuthRevision 小于當前 node 的AuthRevision,則會認為 AuthRevision 太老而導致 Apply 失敗。
- func (as *authStore) isOpPermitted(userName string, revision uint64, key, rangeEnd []byte, permTyp authpb.Permission_Type) error {
- // ...
- if revision < as.Revision() {
- return ErrAuthOldRevision
- }
- // ...
- }
這樣看來,很可能是不同節(jié)點之間的 AuthRevision 不一致了,AuthRevision 是 etcd 啟動時直接從 db 讀取的,每次變更后也會及時的寫入 db,于是我們簡單修改了下 etcd-dump-db工具,將每個節(jié)點 db 內存儲的 AuthRevision 解碼出來對比了下,發(fā)現(xiàn) 3 個節(jié)點的 AuthRevision 確實不一致,node1 的 AuthRevision 最高,node3 的 AuthRevision 最低,這正好能夠解釋之前的現(xiàn)象,endpoint 指定為 node1 寫入的數(shù)據(jù),3 個節(jié)點都能查到,指定為 node3 寫入的數(shù)據(jù),只有 node3 能夠查到,因為 AuthRevision 較低的節(jié)點發(fā)起的 Raft 請求,會被 AuthRevision 較高的節(jié)點在 Apply 的過程中丟棄掉(如下表)。

源碼之前,了無秘密?
目前為止我們已經(jīng)可以明確,新寫入的數(shù)據(jù)通過訪問某些 endpoint 查不出來的原因是由于 AuthRevision 不一致。但是,數(shù)據(jù)最開始發(fā)生不一致問題是否是由 AuthRevision 造成,還暫時不能斷定。為什么這么說呢?因為 AuthRevision 很可能也是受害者,比如 AuthRevision 和數(shù)據(jù)的不一致都是由同一個原因導致的,只不過是 AuthRevision 的不一致放大了數(shù)據(jù)不一致的問題。但是,為更進一步接近真相,我們先假設 AuthRevision 就是導致數(shù)據(jù)不一致的罪魁禍首,進而找出導致 AuthRevision 不一致的真實原因。
原因到底如何去找呢?正所謂,源碼之前了無秘密,我們首先想到了分析代碼。于是,我們走讀了一遍 Auth 操作相關的代碼(如下),發(fā)現(xiàn)只有在進行權限相關的寫操作(如增刪用戶/角色,為角色授權等操作)時,AuthRevision 才會增加。AuthRevision 增加后,會和寫權限操作一起,寫入 backend 緩存,當寫操作超過一定閾值(默認 10000 條記錄)或者每隔100ms(默認值),會執(zhí)行刷盤操作寫入 db。由于 AuthRevision 的持久化和創(chuàng)建用戶等操作的持久化放在一個事務內,因此基本不會存在創(chuàng)建用戶成功了,而 AuthRevision 沒有正常增加的情況。
- func (as *authStore) UserAdd(r *pb.AuthUserAddRequest) (*pb.AuthUserAddResponse, error) {
- // ...
- tx := as.be.BatchTx()
- tx.Lock()
- defer tx.Unlock() // Unlock時滿足條件會觸發(fā)commit操作
- // ...
- putUser(tx, newUser)
- as.commitRevision(tx)
- return &pb.AuthUserAddResponse{}, nil
- }
- func (t *batchTxBuffered) Unlock() {
- if t.pending != 0 {
- t.backend.readTx.Lock() // blocks txReadBuffer for writing.
- t.buf.writeback(&t.backend.readTx.buf)
- t.backend.readTx.Unlock()
- if t.pending >= t.backend.batchLimit {
- t.commit(false)
- }
- }
- t.batchTx.Unlock()
- }
那么,既然 3 個節(jié)點的 AuthRevision 不一致,會不會是因為某些節(jié)點寫權限相關的操作丟失了,從而沒有寫入 db ?如果該猜測成立,3 個節(jié)點的 db 里 authUser 和 authRole 的 bucket 內容應該有所不同才對。于是為進一步驗證,我們繼續(xù)修改了下 etcd-dump-db 這個工具,加入了對比不同 db 文件 bucket 內容的功能。遺憾的是,通過對比發(fā)現(xiàn),3 個節(jié)點之間的 authUser 和 authRole bucket 的內容并沒有什么不同。
既然節(jié)點寫權限相關的操作沒有丟,那會不會是命令重復執(zhí)行了呢?查看異常時間段內日志時發(fā)現(xiàn),其中包含了較多的 auth 操作;進一步分別比對 3 個節(jié)點的 auth 操作相關的日志又發(fā)現(xiàn),部分節(jié)點日志較多,而部分節(jié)點日志較少,看起來像是存在命令重復執(zhí)行現(xiàn)象。由于日志壓縮,雖然暫時還不能確定是重復執(zhí)行還是操作丟失,但是這些信息能夠為我們后續(xù)的排查帶來很大啟發(fā)。
我們繼續(xù)觀察發(fā)現(xiàn),不同節(jié)點之間的 AuthRevison雖有差異,但是差異較小,而且差異值在我們壓測期間沒有變過。既然不同節(jié)點之間的 AuthRevision 差異值沒有進一步放大,那么通過新增的日志基本上也看不出什么問題,因為不一致現(xiàn)象的出現(xiàn)很可能是在過去的某個時間點瞬時造成的。這就造成我們如果想要發(fā)現(xiàn)問題根因,還是要能夠復現(xiàn) AuthRevison 不一致或者數(shù)據(jù)不一致問題才行,并且要能夠抓到復現(xiàn)瞬間的現(xiàn)場。
問題似乎又回到了原點,但好在我們目前已經(jīng)排除了很多干擾信息,將目標聚焦在了 auth 操作上。
混沌工程,成功復現(xiàn)
鑒于之前多次手動模擬各種場景都沒能成功復現(xiàn),我們打算搞一套自動化的壓測方案來復現(xiàn)這個問題,方案制定時主要考慮的點有以下幾個:
- 如何增大復現(xiàn)的概率?
根據(jù)之前的排查結果,很有可能是 auth 操作導致的數(shù)據(jù)不一致,因此我們實現(xiàn)了一個 monkey 腳本,每隔一段時間,會向集群寫入隨機的用戶、角色,并向角色授權,同時進行寫數(shù)據(jù)操作,以及隨機的重啟集群中的節(jié)點,詳細記錄每次一操作的時間點和執(zhí)行日志。
- 怎樣保證在復現(xiàn)的情況下,能夠盡可能的定位到問題的根因?
根據(jù)之前的分析得出,問題根因大概率是 apply 過程中出了問題,于是我們在 apply 的流程里加入了詳細的日志,并打印了每次 apply 操作committedIndex、appliedIndex、consistentIndex 等信息。
- 如果復現(xiàn)成功,如何能夠在第一時間發(fā)現(xiàn)?
由于日志量太大,只有第一時間發(fā)現(xiàn)問題,才能夠更精確的縮小問題范圍,才能更利于我們定位問題。于是我們實現(xiàn)了一個簡單的 metric-server,每隔一分鐘拉取各個節(jié)點的 key 數(shù)量,并進行對比,將差異值暴露為 metric,通過 prometheus 進行拉取,并用 grafana 進行展示,一旦差異值超過一定閾值(寫入數(shù)據(jù)量大的情況下,就算并發(fā)統(tǒng)計各個節(jié)點的 key 數(shù)量,也可能會有少量的差異,所以這里有一個容忍誤差),則立刻通過統(tǒng)一告警平臺向我們推送告警,以便于及時發(fā)現(xiàn)。
方案搞好后,我們新建了一套 etcd 集群,部署了我們的壓測方案,打算進行長期觀察。結果第二天中午,我們就收到了微信告警——集群中存在數(shù)據(jù)不一致現(xiàn)象。
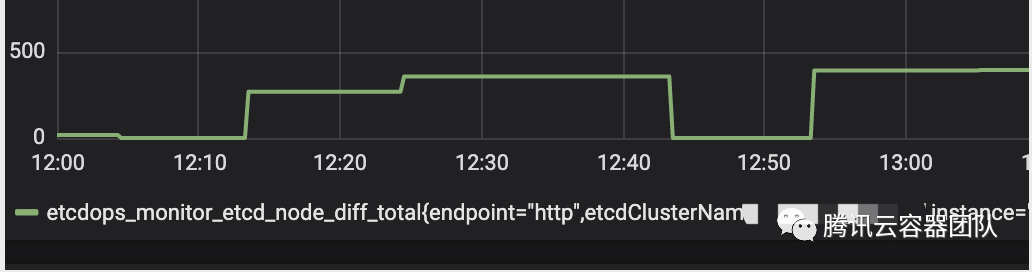
于是,我們立刻登錄壓測機器進行分析,首先停掉了壓測腳本,然后查看了集群中各個節(jié)點的 AuthRevision,發(fā)現(xiàn) 3 個節(jié)點的 AuthRevision 果然不一樣!根據(jù) grafana 監(jiān)控面板上的監(jiān)控數(shù)據(jù),我們將數(shù)據(jù)不一致出現(xiàn)的時間范圍縮小到了 10 分鐘內,然后重點分析了下這 10 分鐘的日志,發(fā)現(xiàn)在某個節(jié)點重啟后,consistentIndex 的值比重啟前要小。然而 etcd 的所有 apply 操作,冪等性都依賴 consistentIndex 來保證,當進行 apply 操作時,會判斷當前要 apply 的 Entry 的 Index 是否大于 consistentIndex,如果 Index 大于 consistentIndex,則會將 consistentIndex 設為 Index,并允許該條記錄被 apply。否則,則認為該請求被重復執(zhí)行了,不會進行實際的 apply 操作。
- // applyEntryNormal apples an EntryNormal type raftpb request to the EtcdServer
- func (s *EtcdServer) applyEntryNormal(e *raftpb.Entry) {
- shouldApplyV3 := false
- if e.Index > s.consistIndex.ConsistentIndex() {
- // set the consistent index of current executing entry
- s.consistIndex.setConsistentIndex(e.Index)
- shouldApplyV3 = true
- }
- // ...
- // do not re-apply applied entries.
- if !shouldApplyV3 {
- return
- }
- // ...
- }
也就是說,由于 consistentIndex 的減小,etcd 本身依賴它的冪等操作將變得不再冪等,導致權限相關的操作在 etcd 重啟后被重復 apply 了,即一共apply 了兩次!
問題原理分析
為何 consistentIndex 會減小?走讀了 consistentIndex 相關代碼后,我們終于發(fā)現(xiàn)了問題的根因:consistentIndex 本身的持久化,依賴于 mvcc 的寫數(shù)據(jù)操作;通過 mvcc 寫入數(shù)據(jù)時,會調用 saveIndex 來持久化 consistentIndex 到 backend,而 auth 相關的操作,是直接讀寫的 backend,并沒有經(jīng)過 mvcc。這就導致,如果做了權限相關的寫操作,并且之后沒有通過 mvcc 寫入數(shù)據(jù),那么這期間 consistentIndex 將不會被持久化,如果這時候重啟了 etcd,就會造成權限相關的寫操作被 apply 兩次,帶來的副作用可能會導致 AuthRevision 重復增加,從而直接造成不同節(jié)點的 AuthRevision 不一致,而 AuthRevision 不一致又會造成數(shù)據(jù)不一致。
- func putUser(lg *zap.Logger, tx backend.BatchTx, user *authpb.User) {
- b, err := user.Marshal()
- tx.UnsafePut(authUsersBucketName, user.Name, b) // 直接寫入Backend,未經(jīng)過MVCC,此時不會持久化consistentIndex
- }
- func (tw *storeTxnWrite) End() {
- // only update index if the txn modifies the mvcc state.
- if len(tw.changes) != 0 {
- tw.s.saveIndex(tw.tx) // 當通過MVCC寫數(shù)據(jù)時,會觸發(fā)consistentIndex持久化
- tw.s.revMu.Lock()
- tw.s.currentRev++
- }
- tw.tx.Unlock()
- if len(tw.changes) != 0 {
- tw.s.revMu.Unlock()
- }
- tw.s.mu.RUnlock()
- }
再回過頭來,為什么數(shù)據(jù)不一致了還可以讀出來,而且讀出來的數(shù)據(jù)還可能不一樣?etcd 不是使用了 raft 算法嗎,難道不能夠保證強一致性嗎?其實這和 etcd 本身的讀操作實現(xiàn)有關。上邊我們已經(jīng)講過,etcd 為了提升讀數(shù)據(jù)的性能,使用了 ReadIndex 操作來實現(xiàn)從當前節(jié)點讀取數(shù)據(jù),而不是每次都從 leader 讀。而影響 ReadIndex 操作的,一個是 leader 節(jié)點的 CommittedIndex,一個是當前節(jié)點的 AppliedIndex,etcd 在 apply 過程中,無論 apply 是否成功,都會更新 AppliedIndex,這就造成,雖然當前節(jié)點 apply 失敗了,但讀操作在判斷的時候,并不會感知到這個失敗,從而導致某些節(jié)點可能讀不出來數(shù)據(jù);而且 etcd 支持多版本并發(fā)控制,同一個 key 可以存在多個版本的數(shù)據(jù),apply 失敗可能只是更新某個版本的數(shù)據(jù)失敗,這就造成不同節(jié)點之間最新的數(shù)據(jù)版本不一致,導致讀出不一樣的數(shù)據(jù)。
影響范圍
該問題從 2016 年引入,所有開啟鑒權的 etcd3 集群都會受到影響,在特定場景下,會導致 etcd 集群多個節(jié)點之間的數(shù)據(jù)不一致,并且 etcd 對外表現(xiàn)還可以正常讀寫,日志無明顯報錯。
觸發(fā)條件
- 使用的為 etcd3 集群,并且開啟了鑒權。
- etcd 集群中節(jié)點發(fā)生重啟。
- 節(jié)點重啟之前,有 grant-permission 操作(或短時間內對同一個權限操作連續(xù)多次增刪),且操作之后重啟之前無其他數(shù)據(jù)寫入。
- 通過非重啟節(jié)點向集群發(fā)起寫數(shù)據(jù)請求。
修復方案
了解了問題的根因,修復方案就比較明確了,我們只需要在 auth 操作調用 commitRevision 后,觸發(fā) consistentIndex 的持久化操作,就能夠保證 etcd 在重啟的時候 consistentIndex 的本身的正確性,從而保證 auth 操作的冪等性。具體的修復方式我們已經(jīng)向 etcd 社區(qū)提交了 PR #11652,目前這個特性已經(jīng) backport 到 3.4,3.3 等版本,將會在最近一個 release 更新。
那么如果數(shù)據(jù)已經(jīng)不一致了怎么辦,有辦法恢復嗎?在 etcd 進程沒有頻繁重啟的情況下,可以先找到 authRevision 最小的節(jié)點,它的數(shù)據(jù)應該是最全的,然后利用 etcd 的 move-leader 命令,將 leader 轉移到這個節(jié)點,再依次將其他節(jié)點移出集群,備份并刪除數(shù)據(jù)目錄,然后將節(jié)點重新加進來,此時它會從 leader 同步一份最新的數(shù)據(jù),這樣就可以使集群其他節(jié)點的數(shù)據(jù)都和 leader 保持一致,即最大可能地不丟數(shù)據(jù)。
升級建議
需要注意的是,升級有風險,新版本雖然解決了這個問題,但由于升級過程中需要重啟 etcd,這個重啟過程仍可能觸發(fā)這個 bug。因此升級修復版本前建議停止寫權限相關操作,并且手動觸發(fā)一次寫數(shù)據(jù)操作之后再重啟節(jié)點,避免因為升級造成問題。
另外,不建議直接跨大版本升級,例如從 etcd3.2 → etcd3.3。大版本升級有一定的風險,需謹慎測試評估,我們之前發(fā)現(xiàn)過由 lease 和 auth 引起的另一個不一致問題,具體可見 issue #11689,以及相關 PR #11691。
問題總結
導致該問題的直接原因,是由于 consistentIndex 在進行權限相關操作時未持久化,從而導致 auth 相關的操作不冪等,造成了數(shù)據(jù)的不一致。
而造成 auth 模塊未持久化 consistentIndex 的一個因素,是因為 consistentIndex 目前是在 mvcc 模塊實現(xiàn)的,并未對外暴露持久化接口,只能通過間接的方式來調用,很容易漏掉。為了優(yōu)化這個問題,我們重構了 consistentIndex 相關操作,將它獨立為一個單獨的模塊,其他依賴它的模塊可以直接調用,一定程度上可以避免將來再出現(xiàn)類似問題,具體見 PR #11699。
另一方面,etcd 的 apply 操作本身是個異步流程,而且失敗之后沒有打印任何錯誤日志,很大程度上增加了排障的難度,因此我們后邊也向社區(qū)提交了相關 PR #11670,來優(yōu)化 apply 失敗時的日志打印,便于定位問題。
造成問題定位困難的另一個原因,是 auth revision 目前沒有對外暴露 metric 或者 api,每次查詢只能通過 etcd-dump-db 工具來直接從 db 獲取,為方便 debug,我們也增加了相關的 metric 和 status api,增強了 auth revision 的可觀測性和可測試性。
相關 PR/issue 查看地址
PR #11652 :https://github.com/etcd-io/etcd/pull/11652
issue #11689:https://github.com/etcd-io/etcd/issues/11689
PR #11691:https://github.com/etcd-io/etcd/pull/11691
PR #11699 :https://github.com/etcd-io/etcd/pull/11699
PR #11670 :https://github.com/etcd-io/etcd/pull/11670
metric :https://github.com/etcd-io/etcd/pull/11652/commits/f14d2a087f7b0fd6f7980b95b5e0b945109c95f3
status api :https://github.com/etcd-io/etcd/pull/11659
參考資料
etcd 源碼:https://github.com/etcd-io/etcd
etcd 存儲實現(xiàn):https://www.codedump.info/post/20181125-etcd-server/
高可用分布存儲 etcd 的實現(xiàn)原理:https://draveness.me/etcd-introduction/
etcd raft 設計與實現(xiàn):https://zhuanlan.zhihu.com/p/51063866,https://zhuanlan.zhihu.com/p/51065416