睡眠研究可以幫助創建更好的AI模型嗎?
我們為什么要睡覺?一個明顯的原因是恢復我們身體和四肢的力量。但是睡眠的另一個非常重要的作用是鞏固記憶并組織清醒時大腦攝入的所有信息。缺乏適當睡眠的人會認知能力下降,記憶力下降。
睡眠的奇觀和奧秘仍然是研究的活躍領域。除了醫學,心理學和神經科學外,睡眠研究還可以用于其他科學領域。人工智能研究人員也在研究這一領域所做的工作,以開發在更長時間內更有效地處理數據的人工智能模型。
DeepMind的人工智能研究人員最近的工作顯示,他們利用對大腦和睡眠機制的研究,來應對自然語言處理(NLP)的一個基本挑戰:處理長期記憶。
人工智能苦苦掙扎的語言記憶
人腦具有非常有趣的組織記憶的方式。我們可以長期管理不同的思路。考慮這個假設的例子:你早上醒來,花45分鐘閱讀一本有關認知科學的書。一個小時后,你瀏覽了新聞并閱讀了幾則新聞文章。下午,你將繼續研究幾天前開始的AI研究論文,并為以后的文章做筆記。在日常的鍛煉中,您會收聽科學播客或有聲讀物。在晚上,入睡前,您打開一本幻想小說,然后找到前一天晚上讀到的地方。
你不需要成為一個天才就可以做到這一點。實際上,我們大多數人每天都在處理各種各樣的信息。有趣的是,我們的大腦能夠保存和管理這些信息,而且可以在很長時間,一天,幾周,幾個月甚至幾年內做到這一點。
近年來,人工智能算法在保持較長數據流的一致性方面已逐漸變得更好,但是要與人腦的技能相匹配,它們還有很長的路要走。
用于處理語言的經典機器學習構造模型是遞歸神經網絡(RNN),這是一種人工神經網絡,旨在處理數據的時間一致性。經過數據語料庫訓練的RNN(例如,大量的Wikipedia文章數據集)可以執行任務,例如預測序列中的下一個單詞或找到問題的答案。
早期版本的RNN的問題在于它們處理信息所需的內存量。AI模型可以處理的數據序列越長,所需的內存就越多。這個限制主要是因為,與人腦不同,神經網絡不知道應該保留哪些數據以及可以丟棄哪些數據。
提取重要信息
想想看:當你讀一本小說,比如《指環王》,你的大腦并不會記住所有的單詞和句子。它被優化以從故事中提取有意義的信息,包括人物(例如,佛羅多、甘道夫、索倫)、他們的關系(例如,博羅米爾幾乎是佛羅多的朋友)、地點(例如,里文德爾、莫爾多、羅漢)、對象(例如,一環和烏里爾)、關鍵事件(例如,佛羅多將一環扔到末日山的中心,甘道夫掉進了哈扎德·杜姆的深淵,赫爾姆之戰的深淵),也許是故事中一些非常重要的對話(例如,不是所有閃光的都是金子,不是所有游蕩的人都迷路了)。
這一小部分信息對于能夠在所有四本書(霍比特人和指環王的所有三卷書)和576459個單詞中遵循故事的情節是非常關鍵的。
人工智能科學家和研究人員一直在試圖找到一種方法,將神經網絡嵌入到同樣有效的信息處理中。這一領域的一個重大成就是發展了"注意"機制,使神經網絡能夠發現和關注數據中更重要的部分。注意力使神經網絡能夠以更有效的記憶方式處理更大量的信息。
Transformers是近年來越來越流行的一種神經網絡,它有效地利用了意圖機制,使人工智能研究人員能夠創建越來越大的語言模型。例子包括OpenAI的GPT-2文本生成器,在40G的文本上訓練,谷歌的Meena chatbot,在341GB的語料庫上訓練,以及AI2的Aristo,一個在300G的數據上訓練以回答科學問題的深度學習算法。
所有這些語言模型都比以前的人工智能算法在較長的文本序列上表現出顯著的一致性。GPT-2可以經常(但并不總是)寫出跨越多個段落的相當連貫的文本。Meena還沒有發布,但是Google提供的示例數據在對話中顯示了有趣的結果,而不僅僅是簡單的查詢。Aristo在回答科學問題方面勝過其他人工智能模型(盡管它只能回答多項選擇題)。
然而,顯而易見的是,語言處理人工智能還有很大的改進空間。目前,通過創建更大的神經網絡并為它們提供越來越大的數據集,仍有一種改進該領域的動力。很明顯,我們的大腦不需要,甚至沒有足夠的能力來獲取數百千兆字節的數據來學習語言的基礎知識。
從睡眠中汲取靈感
當記憶在我們的大腦中被創造出來時,它們開始是編碼在大腦不同部分的感官和認知活動的混亂。這是短期記憶。根據神經科學的研究,海馬體從大腦不同部位的神經元收集激活信息,并以一種可以進入記憶的方式記錄下來。它還存儲了將重新激活這些記憶的提示(名稱、氣味、聲音、視覺等)。記憶被激活得越多,它就變得越強大。
據《你的大腦》一書的作者馬克·丁曼(Marc Dingman)介紹說,"研究發現,在最初的經歷中開啟的相同神經元在深度睡眠時會被重新激活。這使得神經科學家們假設,在睡眠期間,我們的大腦正在努力確保前一天的重要記憶被轉移到長期儲存中。"
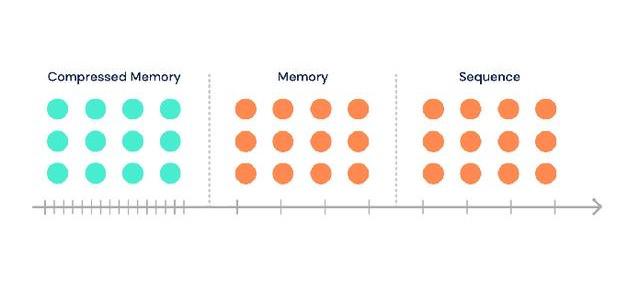
DeepMind的AI研究人員從睡眠中汲取了靈感,創建了Compression Transformer,這是一種更適合遠程記憶的語言模型。"睡眠對記憶至關重要,人們認為睡眠有助于壓縮和鞏固記憶,從而提高記憶任務的推理能力。" 當模型經過一系列輸入時,將在線收集類似于情景存儲器的顆粒存儲器。隨著時間的流逝,它們最終會被壓縮。" 研究人員在Compression Transformer的博客文章中寫道。
與Transformer的其他變體一樣,Compression Transformer使用注意力機制來選擇序列中相關的數據位。但是,AI模型不是丟棄舊的內存,而是刪除了不相關的部分,并通過保留顯著的部分并將其存儲在壓縮的內存位置中來組合其余部分。
根據DeepMind的說法,Compressive Transformer在流行的自然語言AI基準測試中顯示了比較先進的性能。人工智能研究人員寫道:"我們還證明,它可以有效地用于語音建模,特別好地處理稀有單詞,并且可以在強化學習代理中用以解決記憶任務。"
然而,重要的是,人工智能提高了長文本建模的性能。DeepMind的研究人員寫道:"該模型的條件樣本可用于編寫類似書的摘錄。"
博客文章和論文包含了Compressive Transformer輸出的樣本,與該領域中正在做的其他工作相比,這是非常令人印象深刻的。
語言尚未解決
壓縮與歸檔是兩個不同的概念。讓我們回到《指環王》的例子,看看這意味著什么。例如,在閱讀了在埃爾隆德家舉行會議的那一章之后,你不一定記得與會者之間交流的每一個字。但你還記得一件重要的事情:當每個人都在為如何決定這枚戒指的命運而爭吵時,佛羅多走上前,接受了把它扔進厄運山的責任。因此,為了壓縮信息,大腦在儲存記憶時似乎會改變它。隨著記憶的變老,這種轉變還在繼續。
顯然,存在某種模式識別,可以使Compressive Transformer找到應該存儲在壓縮內存段中的相關部分。但是,這些數據位是否等同于以上示例中提到的元素還有待觀察。
使用深度學習算法來處理人類語言的挑戰已經有了很好的記錄。雖然統計方法可以在大量的數據中發現有趣的相關性和模式,但它們無法執行一些需要了解文本以外內容的微妙任務。 諸如抽象,常識,背景知識以及智能的其他方面之類的東西,使我們能夠填補空白并提取單詞背后的隱含含義,而當前的AI方法仍無法解決這些問題。
正如計算機科學家梅拉妮·米切爾(Melanie Mitchell)在她的《人工智能:思考人類的指南》一書中所解釋的那樣,"在我看來,機器不可能完全通過在線學習來達到翻譯,閱讀理解等方面的人類水平。 數據,實際上對它們處理的語言沒有真正的了解。 語言依賴于對世界的常識和理解。"
添加這些元素將使人工智能模型能夠處理語言的不確定性。認知科學家加里·馬庫斯說"除了幾個小句子,你聽到的幾乎每一個句子都是原創的。你沒有直接的數據。這意味著你有一個關于推理和理解的問題。那些有助于對事物進行分類、將它們放入你已經知道的容器中的技術,根本不適合這樣做。理解語言就是把你對這個世界已經知道的東西和別人想用他們說的話、做的事情聯系起來。"
馬庫斯和他的合著者,紐約大學教授歐內斯特·戴維斯(Ernest Davis)在" 重新啟動AI"一書中寫道:"統計數據不能替代對現實世界的理解。問題不僅在于到處都是隨機誤差,還在于滿足翻譯要求的統計分析模型與系統真正理解它們所需要的認知模型構建之間存在根本的不匹配。"
但是壓縮技術可能會幫助我們在人工智能和語言建模研究中找到新的方向。"能夠捕捉跨天、跨月或跨年經驗相關關系的模型即將出現。"我們相信,隨著時間的推移,更強大的推理途徑將來自過去更好的選擇性關注,以及更有效的壓縮機制,"DeepMind的人工智能研究人員寫道。