谷歌提出AI訓練提速新方法,榨干GPU空閑時間,最高提速3倍多
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
因為通用計算芯片不能滿足神經網絡運算需求,越來越多的人轉而使用GPU和TPU這類專用硬件加速器,加快神經網絡訓練的速度。
但是,用了更快的GPU和TPU就一定能加速訓練嗎?
訓練流水線的所有操作并不都是在加速器上運行。上游數據處理(如磁盤I/O和數據預處理)就不能在加速器上運行。
隨著GPU等加速器越來越快,超過了CPU、磁盤處理數據的速度,上游就逐漸成了訓練瓶頸。

在某些情況下,GPU上游的代碼花費的時間甚至是GPU本身運行時間的幾倍。上游沒做完,下游只能空等,浪費了大量時間。
為此,Google AI團隊,提出一種簡單的數據回波(Data Echoing)方法,可以解決這個問題。該方法最多能將訓練速度加速3倍以上,且對模型的精度沒有明顯影響。
Jeff Dean也在Twitter上轉發點贊。

重復數據讓GPU不空等
很多情況下,上游花費的時間比加速器更長,使用更快的GPU或TPU根本不會提高訓練速度。如果投入大量的工程工作以及額外的計算資源,確實可以加快流水線的速度。
對于非常小的數據集,可以離線預先計算擴增的數據集,并將整個預處理的數據集加載到內存中。
但這種方法不適用于大多數機器學習訓練場景,既耗時又分散了改善推理性能的主要目標。
與其等待更多的數據,不如利用已有的數據來使加速器保持忙碌狀態。

在加速器空置50%情況下,預處理batch的第一個優化步驟之后,我們可以重復利用該batch再進行一次訓練。
如果重復數據與新數據一樣有用,訓練效率會提高一倍。
實際上,由于重復數據不如新數據有用,因此數據回波提供的加速要小一些,但和加速器處于空閑狀態相比,仍然可以提供明顯的加速。
通常有幾種方法可以在給定的神經網絡訓練管道中實現數據回波。
Google提出的技術,是將數據復制到訓練管道中某個位置的隨機緩沖區中,無論在哪個階段產生瓶頸之后,都可以將緩存數據插入任意位置。
數據回波在樣本級別對數據進行混洗,而batch回波則對重復批次的序列進行混洗。另外還可以在數據擴充之前插入緩沖區,以使重復數據的每個副本略有不同,因此不是簡單機械重復,而是更接近一個新樣本。
加速3倍多,精度無損失
那么數據回波到底多有用呢?
Google在五個神經網絡訓練管道上嘗試了數據回波,涵蓋了圖像分類、語言建模和目標檢測3個不同的任務,并測量了達到特定性能目標所需的新樣本數量。
Google發現,數據回波可以用更少的新樣本來達到目標性能,這表明重復使用數據對于降低磁盤I/O很有用。在某些情況下,重復數據幾乎與新數據一樣有用。
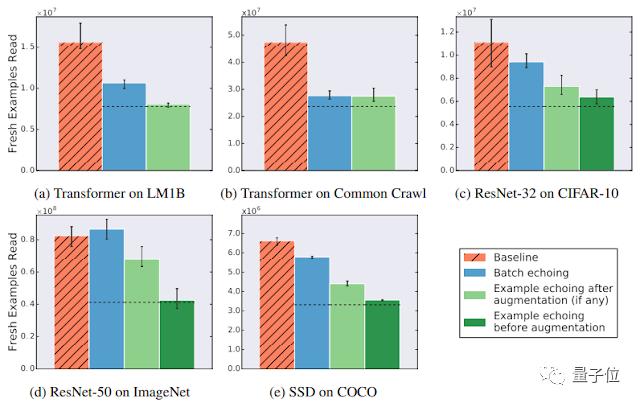
在ImageNet的ResNet-50訓練任務中,數據回波可以顯著提高訓練速度,加速了3倍以上。
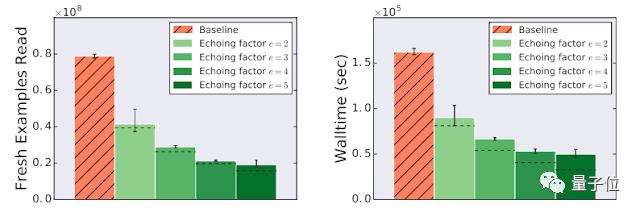
從云存儲中讀取一批訓練數據所花的時間是使用每一批數據執行訓練步驟的6倍。因此數據最多可以重復5次。
我們將回波因子定義為重復每個數據項的次數,對于以上任務,回波因子最大是5。如果重復樣本與新樣本一樣有用,則應該帶來6倍加速,而實際上只加速了3.25倍,但也相當可觀。
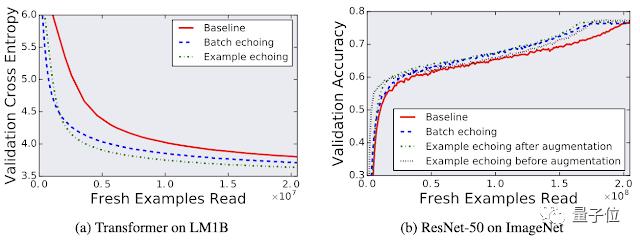
可能有人會擔心重復使用數據會損害模型的最終性能,但實驗發現,測試的任何工作負載,數據回波都不會降低最終模型的質量。
隨著GPU和TPU性能的繼續提升,和通用處理器的差距會越來越大,Google期望數據回波和類似策略將成為神經網絡培訓工具包中越來越重要的一部分。
怎么樣,谷歌AI的這項最新研究,是不是也給你訓練神經網絡帶來一些新啟發?