免訓練加速DiT!Meta提出自適應緩存新方法,視頻生成快2.6倍
現在,視頻生成模型無需訓練即可加速了?!
Meta提出了一種新方法AdaCache,能夠加速DiT模型,而且是無需額外訓練的那種(即插即用)。
話不多說,先來感受一波加速feel(最右):

可以看到,與其他方法相比,AdaCache生成的視頻質量幾乎無異,而生成速度卻提升了2.61倍。
據了解,AdaCache靈感源于“并非所有視頻都同等重要”。
啥意思??原來團隊發現:
有些視頻在達到合理質量時所需的去噪步驟比其他視頻少
因此,團隊在加速DiT時主打一個“按需分配,動態調整”,分別提出基于內容的緩存調度和運動正則化(MoReg)來控制緩存及計算分配。
目前這項技術已在GitHub開源,單個A100(80G)GPU 上就能運行,網友們直呼:
看起來速度提升了2~4倍,Meta讓開源AI再次偉大!

“并非所有視頻都同等重要”
下面我們具體介紹下這項研究。
先說結論,以Open-Sora是否加持AdaCache為例,使用AdaCache能將視頻生成速度提升4.7倍——
質量幾乎相同的情況下,前后速度從419.60s降低到89.53s。

具體如何實現的呢??
眾所周知,DiT(Diffusion Transformers)結合了擴散模型和Transformer架構的優勢,通過模擬從噪聲到數據的擴散過程,能夠生成高質量圖像和視頻。
不過DiT并非完美無缺,自OpenAI發布Sora以來(DiT因被視為Sora背后的技術基礎之一而廣受關注),人們一直嘗試改進它。
這不,Meta的這項研究就瞄準了DiT為人熟知的痛點:
依賴更大的模型和計算密集型的注意力機制,導致推理速度變慢。
展開來說——
首先,團隊在研究中發現,有些視頻在達到合理質量時所需的去噪步驟比其他視頻少。
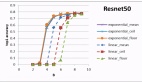
他們展示了基于Open-Sora的不同視頻序列在不同去噪步驟下的穩定性和質量變化。
通過逐步減少去噪步驟,他們發現每個視頻序列的 “中斷點”(即質量開始顯著下降的步驟數量)是不同的,右側直方圖也顯示了在不同步驟中特征變化的幅度。
這啟發了團隊,“并非所有視頻都同等重要”。
換句話說,針對每個視頻都可以有不同的緩存和計算分配,以此節約資源。

于是針對緩存,Meta推出了一種名為AdaCache(自適應緩存)的新方法,核心是:
每次生成視頻時,AdaCache會按視頻的特定內容分配緩存資源,將不同視頻的緩存需求動態調整到最優。
其架構如圖所示,下面具體展開。

左側部分,AdaCache將DiT的原始擴散過程分為多個步驟,并對每一步進行殘差計算,以生成新的表示。
這些新的表示會在后續步驟中被重復使用,而不需要每次都重新計算,從而節省大量計算資源。
過程中,研究使用一個距離度量(ct)來判斷當前表示和之前緩存的表示之間的變化幅度。
如果變化較小,就可以直接使用緩存,節省計算量;如果變化較大,則需要重新計算。
右側部分,是DiT內部的計算過程,可以看到空間-時間注意力(STA)、交叉注意力(CA)和多層感知器(MLP)三個模塊。
其中每一步生成的新表示(如ft+k和ft)會使用緩存中的殘差進行更新,從而減少重復計算的次數。
總之一句話,這種策略使得計算資源能夠根據視頻內容的復雜性和變化率動態分配。
此外,為了進一步改進AdaCache,團隊還引入運動正則化(MoReg)來控制計算分配。
通過考慮視頻特定的運動信息來優化緩存策略
團隊發現,視頻中的運動內容對于確定最佳的去噪步驟數量至關重要,通常高運動內容需要更多去噪步驟來保證生成質量。
基于此,MoReg的核心思想是:
對于運動內容較多的視頻,應該減少緩存的使用,從而允許在更多的步驟中進行重新計算。
由于需要在視頻生成過程中實時估計運動,MoReg不能依賴于傳統的、計算密集型的像素空間運動估計算法。
補充一下,這是一種用于視頻編碼中的技術,它通過比較相鄰幀之間的像素差異來估計運動向量,從而實現視頻的壓縮。
因此,MoReg使用殘差幀差異作為噪聲潛在運動得分(noisy latent motion-score)的度量,其公式如下:
 且為了進一步提高運動估計的準確性,MoReg引入了運動梯度(motion-gradient)的概念。
且為了進一步提高運動估計的準確性,MoReg引入了運動梯度(motion-gradient)的概念。

它可以作為一個更好的趨勢估計,幫助在視頻生成的早期階段預測運動,并作為調整緩存策略的依據。
那么,采用AdaCache+MoReg的最終效果如何呢?
實驗結果:優于其他免訓練加速方法
最后,團隊使用了VBench基準測試來評估AdaCache在不同視頻生成任務中的性能。
其中VBench提供了一系列的質量指標,包括峰值信噪比(PSNR)、結構相似性(SSIM)和感知圖像質量指標(LPIPS)。
同時,還測量了推理延遲(Latency)和計算復雜度(FLOPs)。

測試對象包括了AdaCache的多個變體,包括慢速(slow)、快速(fast)和帶有MoReg的版本。
結果顯示,fast變體提供了更高的加速比,而slow變體則提供了更高的生成質量。
與此同時,與其他無訓練加速方法(如?-DiT、T-GATE和PAB)相比,在生成質量相當或更高的情況下,AdaCache都提供了顯著的加速效果。
另外,隨著GPU的數量增加,AdaCache的加速比也相應增加,這表明它能夠有效地利用并行計算資源,并減少GPU之間的通信開銷。

更多實驗細節歡迎查閱原論文。
論文:https://arxiv.org/abs/2411.02397
項目主頁:https://adacache-dit.github.io/
GitHub:https://github.com/AdaCache-DiT/AdaCache